Paralelismo de dados compartilhados
O paralelismo de dados fragmentados é uma técnica de treinamento distribuído que economiza memória e divide o estado de um modelo (parâmetros do modelo, gradientes e estados do otimizador) em GPUs dentro de um grupo paralelo de dados.
nota
Esse recurso está disponível para o PyTorch na biblioteca de paralelismo de modelos do SageMaker v1.11.0 e versões posteriores.
Ao escalar seu trabalho de treinamento para um grande cluster de GPU, você pode reduzir o espaço de memória por GPU do modelo fragmentando o estado de treinamento do modelo em várias GPUs. Isso traz dois benefícios: você pode ajustar modelos maiores, que de outra forma ficariam sem memória com o paralelismo de dados padrão, ou você pode aumentar o tamanho do lote usando a memória liberada da GPU.
A técnica padrão de paralelismo de dados replica os estados de treinamento nas GPUs no grupo paralelo de dados e executa a agregação de gradientes com base na operação AllReduce. O paralelismo de dados fragmentados modifica o procedimento padrão de treinamento distribuído em paralelo a dados para considerar a natureza fragmentada dos estados do otimizador. Um grupo de classificações nas quais os estados do modelo e do otimizador são fragmentados é chamado de grupo de fragmentação. A técnica de paralelismo de dados fragmentados fragmenta os parâmetros treináveis de um modelo e os gradientes e estados do otimizador correspondentes nas GPUs do grupo de fragmentação.
O SageMaker alcança o paralelismo de dados fragmentados por meio da implementação de MiCS, o que é discutido na publicação de blog AWS Near-linear scaling of gigantic-model training on AWSAllGather. Após a passagem para frente ou para trás de cada camada, os MiCS fragmentam os parâmetros novamente para economizar memória da GPU. Durante o retrocesso, os MiCS reduzem os gradientes e os fragmentam simultaneamente nas GPUs durante a operação ReduceScatter. Por fim, os MiCS aplicam os gradientes locais reduzidos e fragmentados aos fragmentos de parâmetros locais correspondentes, usando os fragmentos locais dos estados do otimizador. Para reduzir a sobrecarga de comunicação, a biblioteca de paralelismo de modelos do SageMaker pré-busca as próximas camadas na passagem para frente ou para trás e sobrepõe a comunicação de rede à computação.
O estado de treinamento do modelo é replicado nos grupos de fragmentação. Isso significa que antes que os gradientes sejam aplicados aos parâmetros, a operação AllReduce deve ocorrer nos grupos de fragmentação, além da operação ReduceScatter que ocorre dentro do grupo de fragmentação.
Na verdade, o paralelismo de dados fragmentados introduz uma compensação entre a sobrecarga de comunicação e a eficiência da memória da GPU. Usar o paralelismo de dados fragmentados aumenta o custo de comunicação, mas o espaço de memória por GPU (excluindo o uso de memória devido a ativações) é dividido pelo grau de paralelismo de dados fragmentados, portanto, modelos maiores podem caber no cluster de GPU.
Seleção do grau de paralelismo de dados fragmentados
Quando você seleciona um valor para o grau de paralelismo de dados fragmentados, o valor deve dividir uniformemente o grau de paralelismo de dados. Por exemplo, para um trabalho de paralelismo de dados de 8 vias, escolha 2, 4 ou 8 para o grau de paralelismo de dados fragmentados. Ao escolher o grau de paralelismo de dados fragmentados, recomendamos que você comece com um número pequeno e aumente gradualmente até que o modelo caiba na memória junto com o tamanho de lote desejado.
Seleção do tamanho do lote
Depois de configurar o paralelismo de dados fragmentados, certifique-se de encontrar a configuração de treinamento ideal que possa ser executada com êxito no cluster da GPU. Para treinar grandes modelo de linguagem (LLM), comece com o tamanho do lote 1 e aumente-o gradualmente até chegar ao ponto de receber o erro de falta de memória (OOM). Se você encontrar o erro OOM mesmo com o menor tamanho de lote, aplique um grau mais alto de paralelismo de dados fragmentados ou uma combinação de paralelismo de dados fragmentados e paralelismo de tensores.
Tópicos
- Como aplicar o paralelismo de dados fragmentados ao seu trabalho de treinamento
- Configurações de referência
- Paralelismo de dados fragmentados com coletivos SMDDP
- Treinamento misto de precisão com paralelismo de dados fragmentados
- Paralelismo de dados fragmentados com paralelismo de tensores
- Dicas e considerações para usar o paralelismo de dados fragmentados
Como aplicar o paralelismo de dados fragmentados ao seu trabalho de treinamento
Para começar a usar o paralelismo de dados fragmentados, aplique as modificações necessárias em seu script de treinamento e configure o estimador do SageMaker PyTorch com os parâmetros específicos do paralelismo de dados fragmentados. Considere também usar valores de referência e exemplos de cadernos como ponto de partida.
Adaptar seu script de treinamento do PyTorch
Siga as instruções na Etapa 1: Modifique um script de treinamento do PyTorch para agrupar os objetos do modelo e do otimizador com os invólucros smdistributed.modelparallel.torch dos módulos torch.nn.parallel e torch.distributed.
(Opcional) Modificação adicional para registrar os parâmetros externos do modelo
Se seu modelo for construído com torch.nn.Module e usar parâmetros que não estão definidos na classe do módulo, você deve registrá-los manualmente no módulo para que o SMP colete os parâmetros completos enquanto. Para registrar parâmetros em um módulo, use smp.register_parameter(module,
parameter).
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
Configurar o estimador SageMaker PyTorch
Ao configurar um estimador SageMaker PyTorch em Etapa 2: Iniciar um trabalho de treinamento usando o SDK do SageMaker para Python, adicione os parâmetros para paralelismo de dados fragmentados.
Para ativar o paralelismo de dados fragmentados, adicione o parâmetro sharded_data_parallel_degree ao Estimador PyTorch do SageMaker. Esse parâmetro especifica o número de GPUs nas quais o estado de treinamento é fragmentado. O valor de sharded_data_parallel_degree deve ser um número inteiro entre um e o grau de paralelismo de dados e deve dividir uniformemente o grau de paralelismo de dados. Observe que a biblioteca detecta automaticamente o número de GPUs, portanto, o grau paralelo dos dados. Os parâmetros adicionais a seguir estão disponíveis para configurar o paralelismo de dados fragmentados.
-
"sdp_reduce_bucket_size"(int, default: 5e8): Especifica o tamanho dos buckets de gradiente PyTorch DDPem número de elementos do dtype padrão. -
"sdp_param_persistence_threshold"(int, default: 1e6): Especifica o tamanho de um tensor de parâmetros em número de elementos que podem persistir em cada GPU. O paralelismo de dados fragmentados divide cada tensor de parâmetros em GPUs de um grupo paralelo de dados. Se o número de elementos no tensor de parâmetros for menor que esse limite, o tensor de parâmetros não será dividido; isso ajuda a reduzir a sobrecarga de comunicação porque o tensor de parâmetros é replicado em GPUs paralelas de dados. -
"sdp_max_live_parameters"(int, default: 1e9): Especifica o número máximo de parâmetros que podem estar simultaneamente em um estado de treinamento recombinado durante a passagem para frente e para trás. A busca de parâmetros com a operaçãoAllGatheré interrompida quando o número de parâmetros ativos atinge o limite determinado. Observe que aumentar esse parâmetro aumenta o espaço ocupado pela memória. -
"sdp_hierarchical_allgather"(bool, default: True): Se definida comoTrue, a operaçãoAllGatheré executada hierarquicamente: ela é executada primeiro em cada nó e depois em todos os nós. Para trabalhos de treinamento distribuídos de vários nós, a operaçãoAllGatherhierárquica é ativada automaticamente. -
"sdp_gradient_clipping"(float, padrão: 1.0): especifica um limite para recortar o gradiente na norma L2 dos gradientes antes de propagá-los para trás por meio dos parâmetros do modelo. Quando o paralelismo de dados fragmentados é ativado, o recorte de gradiente também é ativado. O limite padrão é1.0. Ajuste esse parâmetro se você tiver o problema de gradientes explosivos.
O código a seguir mostra um exemplo de como configurar o paralelismo de dados fragmentados.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
Configurações de referência
A equipe de treinamento distribuído do SageMaker fornece as seguintes configurações de referência que você pode usar como ponto de partida: Você pode extrapolar a partir das configurações a seguir para experimentar e estimar o uso de memória da GPU para a configuração do seu modelo.
Paralelismo de dados fragmentados com coletivos SMDDP
| Modelo/número de parâmetros | Número de instâncias | Tipo de instância | Comprimento da sequência | Tamanho global do lote | Tamanho do minilote | Grau paralelo de dados fragmentados |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
Por exemplo, se você aumentar o comprimento da sequência de um modelo de 20 bilhões de parâmetros ou aumentar o tamanho do modelo para 65 bilhões de parâmetros, primeiro precisará tentar reduzir o tamanho do lote. Se o modelo ainda não se adequar ao menor tamanho de lote (o tamanho do lote de 1), tente aumentar o grau de paralelismo do modelo.
Paralelismo de dados fragmentados com paralelismo de tensores e coletivos NCCL
| Modelo/número de parâmetros | Número de instâncias | Tipo de instância | Comprimento da sequência | Tamanho global do lote | Tamanho do minilote | Grau paralelo de dados fragmentados | Tensor de grau paralelo | Ativação e descarregamento |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | S |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | S |
O uso combinado de paralelismo de dados fragmentados e paralelismo de tensores é útil quando você deseja ajustar um grande modelo de linguagem (LLM) em um cluster de grande escala enquanto usa dados de texto com um comprimento de sequência maior, o que leva ao uso de um tamanho de lote menor e, consequentemente, manipula o uso de memória da GPU para treinar LLMs em sequências de texto mais longas. Para saber mais, consulte Paralelismo de dados fragmentados com paralelismo de tensores.
Para estudos de caso, benchmarks e mais exemplos de configuração, consulte a postagem no blog Novas melhorias de performance na biblioteca paralela de modelos do Amazon SageMaker
Paralelismo de dados fragmentados com coletivos SMDDP
A biblioteca de paralelismo de dados do SageMaker oferece primitivos de comunicação coletiva (coletivos SMDDP) otimizados para a infraestrutura AWS. Ele obtém a otimização adotando um padrão de comunicação do tipo “tudo para todos” usando o Elastic Fabric Adapter (EFA)
nota
O paralelismo de dados fragmentados com SMDDP Collectives está disponível na biblioteca de paralelismo de modelos do SageMaker v1.13.0 e posterior, e na biblioteca de paralelismo de dados SageMaker v1.6.0 e posterior. Consulte também Supported configurations para usar o paralelismo de dados fragmentados com coletivos SMDDP.
No paralelismo de dados fragmentados, que é uma técnica comumente usada em treinamento distribuído em grande escala, o coletivo AllGather é usado para reconstituir os parâmetros da camada fragmentada para cálculos de passagem para frente e para trás, em paralelo com a computação da GPU. Para modelos grandes, realizar a operação AllGather com eficiência é fundamental para evitar problemas de gargalo na GPU e diminuir a velocidade de treinamento. Quando o paralelismo de dados fragmentados é ativado, os coletivos SMDDP entram nesses coletivos de performance crítico, melhorando a produtividade do treinamento AllGather.
Treine com coletivos SMDDP
Quando seu trabalho de treinamento tem o paralelismo de dados fragmentados ativado e atende ao Supported configurations, os coletivos SMDDP são ativados automaticamente. Internamente, os coletivos SMDDP otimizam o coletivo AllGather para ter performance na infraestrutura AWS e recorrem ao NCCL para todos os outros coletivos. Além disso, em configurações incompatíveis, todos os coletivos, inclusive AllGather, usam automaticamente o backend NCCL.
Desde a versão 1.13.0 da biblioteca de paralelismo de modelos do SageMaker, o parâmetro "ddp_dist_backend" é adicionado às opções modelparallel. O valor padrão desse parâmetro de configuração é "auto", que usa coletivos SMDDP sempre que possível e, caso contrário, volta para NCCL. Para forçar a biblioteca a sempre usar NCCL, especifique "nccl" para o parâmetro de configuração "ddp_dist_backend".
O exemplo de código a seguir mostra como configurar um estimador PyTorch usando o paralelismo de dados fragmentados com o parâmetro "ddp_dist_backend", que é definido como "auto" por padrão e, portanto, opcional para adição.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Configurações compatíveis
A operação AllGather com coletivos SMDDP é ativada em trabalhos de treinamento quando todos os requisitos de configuração a seguir são atendidos.
-
O grau de paralelismo de dados fragmentados maior que 1
-
Instance_countmaior que 1 -
Instance_typeigual aml.p4d.24xlarge -
Contêiner de treinamento do SageMaker para PyTorch v1.12.1 ou posterior
-
A biblioteca de paralelismo de dados do SageMaker v1.6.0 ou posterior
-
A biblioteca de paralelismo de modelos do SageMaker v1.13.0 ou posterior
Ajuste de performance e memória
Os coletivos SMDDP utilizam memória GPU adicional. Há duas variáveis de ambiente para configurar o uso da memória da GPU, dependendo dos diferentes casos de uso de treinamento de modelo.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES: Durante a operação SMDDPAllGather, o buffer de entradaAllGatheré copiado em um buffer temporário para comunicação entre nós. A variávelSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTEScontrola o tamanho (em bytes) desse buffer temporário. Se o tamanho do buffer temporário for menor que o tamanho do bufferAllGatherde entrada, o coletivoAllGathervoltará a usar o NCCL.-
Valor padrão: 16 * 1024 * 1024 (16 MB)
-
Valores aceitáveis: qualquer múltiplo de 8192
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES: A variávelSMDDP_AG_SORT_BUFFER_SIZE_BYTESé dimensionar o buffer temporário (em bytes) para armazenar os dados coletados da comunicação entre nós. Se o tamanho desse buffer temporário for menor que1/8 * sharded_data_parallel_degree * AllGather input size, o coletivoAllGathervolta a usar o NCCL.-
Valor padrão: 128 * 1024 * 1024 (128 MB)
-
Valores aceitáveis: qualquer múltiplo de 8192
-
Orientação de ajuste sobre as variáveis de tamanho do buffer
Os valores padrão das variáveis de ambiente devem funcionar bem na maioria dos casos de uso. Recomendamos o ajuste dessas variáveis somente se o treinamento apresentar o erro de falta de memória (OOM).
A lista a seguir discute algumas dicas de ajuste para reduzir o consumo de memória da GPU dos coletivos SMDDP e, ao mesmo tempo, reter o ganho de performance deles.
-
Ajustar
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
O tamanho do buffer de entrada
AllGatheré menor para modelos menores. Portanto, o tamanho necessário paraSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpode ser menor para modelos com menos parâmetros. -
O tamanho do buffer de entrada
AllGatherdiminui à medida quesharded_data_parallel_degreeaumenta, porque o modelo é fragmentado em mais GPUs. Portanto, o tamanho necessário paraSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpode ser menor para trabalhos de treinamento com valores grandes parasharded_data_parallel_degree.
-
-
Ajustar
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
A quantidade de dados coletados da comunicação entre nós é menor para modelos com menos parâmetros. Portanto, o tamanho necessário para
SMDDP_AG_SORT_BUFFER_SIZE_BYTESpode ser menor para modelos com menor número de parâmetros.
-
Alguns coletivos podem voltar a usar o NCCL; portanto, você pode não obter o ganho de performance dos coletivos SMDDP otimizados. Se houver memória da GPU adicional disponível para uso, considere aumentar os valores SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES e SMDDP_AG_SORT_BUFFER_SIZE_BYTES se beneficiar do ganho de performance.
O código a seguir mostra como você pode configurar as variáveis de ambiente anexando-as ao parâmetro mpi_options de distribuição do estimador PyTorch.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Treinamento misto de precisão com paralelismo de dados fragmentados
Para economizar ainda mais a memória da GPU com números de ponto flutuante de meia precisão e paralelismo de dados fragmentados, você pode ativar o formato de ponto flutuante de 16 bits (FP16) ou o formato de ponto flutuante Brain (BF16)
nota
O treinamento misto de precisão com paralelismo de dados fragmentados está disponível na biblioteca de paralelismo de modelos do SageMaker v1.11.0 e versões posteriores.
Para treinamento do FP16 com paralelismo de dados fragmentados
Para executar o treinamento do FP16 com paralelismo de dados fragmentados, adicione "fp16": True" ao dicionário de configuração smp_options. Em seu script de treinamento, você pode escolher entre as opções de escalonamento de perda estática e dinâmica por meio do módulo smp.DistributedOptimizer. Para obter mais informações, consulte Treinamento FP16 com paralelismo de modelos.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
Para treinamento do BF16 com paralelismo de dados fragmentados
O atributo de paralelismo de dados fragmentados do SageMaker oferece apoio ao treinamento no tipo de dados BF16. O tipo de dados BF16 usa 8 bits para representar o expoente de um número de ponto flutuante, enquanto o tipo de dados FP16 usa 5 bits. Preservar os 8 bits para o expoente permite manter a mesma representação do expoente de um número de ponto flutuante de precisão única (FP32) de 32 bits. Isso torna a conversão entre FP32 e BF16 mais simples e significativamente menos propensa a causar problemas de estouro e subfluxo que surgem frequentemente no treinamento de FP16, especialmente ao treinar modelos maiores. Embora os dois tipos de dados usem 16 bits no total, esse intervalo de representação aumentado para o expoente no formato BF16 ocorre às custas da precisão reduzida. Para treinar modelos grandes, essa precisão reduzida geralmente é considerada uma compensação aceitável para o alcance e a estabilidade do treinamento.
nota
Atualmente, o treinamento do BF16 funciona somente quando o paralelismo de dados fragmentados é ativado.
Para executar o treinamento BF16 com paralelismo de dados fragmentados, adicione "bf16": True ao dicionário de configuração smp_options.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
Paralelismo de dados fragmentados com paralelismo de tensores
Se você usa paralelismo de dados fragmentados e também precisa reduzir o tamanho global do lote, considere usar paralelismo de tensores com paralelismo de dados fragmentados. Ao treinar um modelo grande com paralelismo de dados fragmentados em um cluster de computação muito grande (normalmente 128 nós ou mais), até mesmo um pequeno tamanho de lote por GPU resulta em um tamanho de lote global muito grande. Isso pode levar a problemas de convergência ou problemas de baixo performance computacional. Às vezes, não é possível reduzir o tamanho do lote por GPU apenas com o paralelismo de dados fragmentados, quando um único lote já é grande e não pode ser reduzido ainda mais. Nesses casos, usar o paralelismo de dados fragmentados em combinação com o paralelismo de tensores ajuda a reduzir o tamanho global do lote.
A escolha dos graus ideais de dados fragmentados paralelos e tensores paralelos depende da escala do modelo, do tipo de instância e do tamanho global do lote que seja razoável para a convergência do modelo. Recomendamos que você comece com um grau paralelo de baixo tensor para ajustar o tamanho do lote global ao cluster de computação para resolver erros de falta de memória do CUDA e obter o melhor performance. Veja os dois exemplos de casos a seguir para saber como a combinação de paralelismo de tensores e paralelismo de dados fragmentados ajuda você a ajustar o tamanho global do lote agrupando GPUs para paralelismo de modelos, resultando em um número menor de réplicas de modelos e em um tamanho de lote global menor.
nota
Esse atributo está disponível na biblioteca de paralelismo de modelos SageMaker v1.15 e é compatível com PyTorch v1.13.1.
nota
Esse atributo está disponível para os modelos compatíveis com a funcionalidade de paralelismo de tensores da biblioteca. Para encontrar a lista dos modelos compatíveis, consulte Ajuda para modelo tipo transformador do Hugging Face. Observe também que você precisa passar tensor_parallelism=True para o argumento smp.model_creation ao modificar seu script de treinamento. Para saber mais, consulte o script de treinamento train_gpt_simple.py
Exemplo 1
Suponha que queremos treinar um modelo em um cluster de 1536 GPUs (192 nós com 8 GPUs em cada), definindo o grau de paralelismo de dados fragmentados como 32 (sharded_data_parallel_degree=32) e o tamanho do lote por GPU como 1, onde cada lote tem um comprimento de sequência de 4096 tokens. Nesse caso, existem 1536 réplicas de modelos, o tamanho do lote global se torna 1536 e cada lote global contém cerca de 6 milhões de tokens.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
Adicionar paralelismo de tensor a ele pode diminuir o tamanho global do lote. Um exemplo de configuração pode ser definir o grau paralelo do tensor como 8 e o tamanho do lote por GPU como 4. Isso forma 192 grupos paralelos de tensores ou 192 réplicas de modelo, em que cada réplica do modelo é distribuída em 8 GPUs. O tamanho do lote de 4 é a quantidade de dados de treinamento por iteração e por grupo paralelo de tensores; ou seja, cada réplica do modelo consome 4 lotes por iteração. Nesse caso, o tamanho do lote global se torna 768 e cada lote global contém cerca de 3 milhões de tokens. Portanto, o tamanho do lote global é reduzido pela metade em comparação com o caso anterior com apenas o paralelismo de dados fragmentados.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
Exemplo 2
Quando o paralelismo de dados fragmentados e o paralelismo de tensores são ativados, a biblioteca primeiro aplica o paralelismo de tensores e fragmenta o modelo em toda essa dimensão. Para cada classificação paralela do tensor, o paralelismo de dados é aplicado conforme sharded_data_parallel_degree.
Por exemplo, suponha que queremos definir 32 GPUs com um grau paralelo de tensor de 4 (formando grupos de 4 GPUs), um grau paralelo de dados fragmentados de 4, terminando com um grau de replicação de 2. A atribuição cria oito grupos de GPU com base no grau paralelo do tensor da seguinte forma: (0,1,2,3), (4,5,6,7), (8,9,10,11), (12,13,14,15), (16,17,18,19), (20,21,22,23), (24,25,26,27), (28,29,30,31). Ou seja, quatro GPUs formam um grupo paralelo de tensores. Nesse caso, o grupo paralelo de dados reduzido para as GPUs de 0ª classificação dos grupos paralelos tensores seria (0,4,8,12,16,20,24,28). O grupo paralelo de dados reduzido é fragmentado com base no grau paralelo de dados fragmentados de 4, resultando em dois grupos de replicação para paralelismo de dados. As GPUs (0,4,8,12) formam um grupo de fragmentação, que coletivamente contém uma cópia completa de todos os parâmetros para a classificação paralela do 0º tensor, e as GPUs (16,20,24,28) formam outro grupo desse tipo. Outras classificações paralelas de tensores também têm grupos de fragmentação e replicação semelhantes.
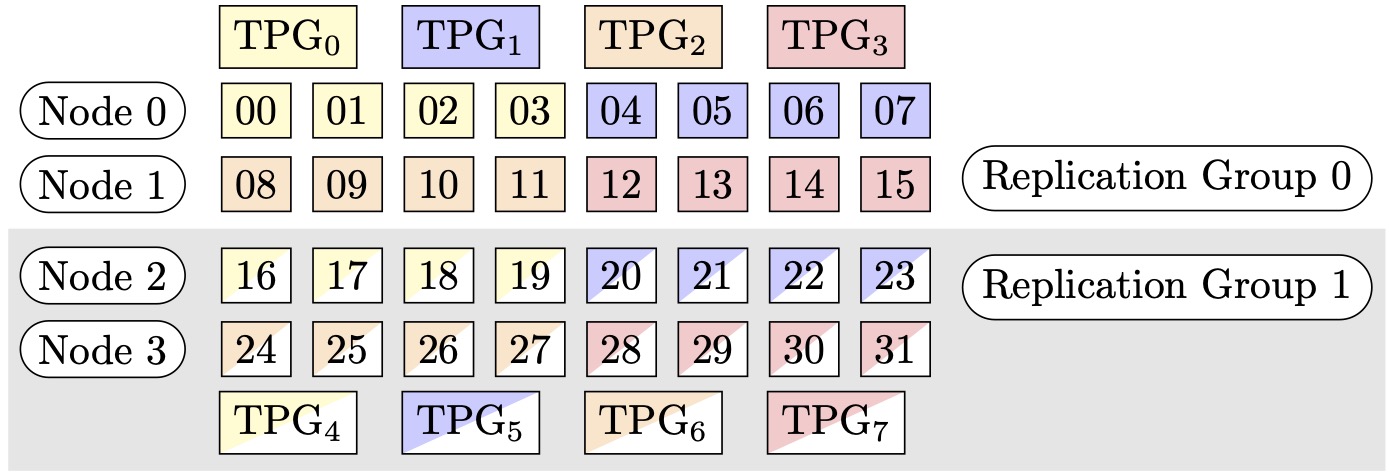
Figura 1: Grupos de paralelismo de tensores para (nós, grau paralelo de dados fragmentados, grau paralelo do tensor) = (4, 4, 4), onde cada retângulo representa uma GPU com índices de 0 a 31. As GPUs formam grupos de paralelismo de tensores de TPG0 a TPG7. Os grupos de replicação são ({TPG0, TPG4}, {TPG1, TPG5}, {TPG2, TPG6} e {TPG3, TPG7}); cada par de grupos de replicação compartilha a mesma cor, mas preenchida de forma diferente.
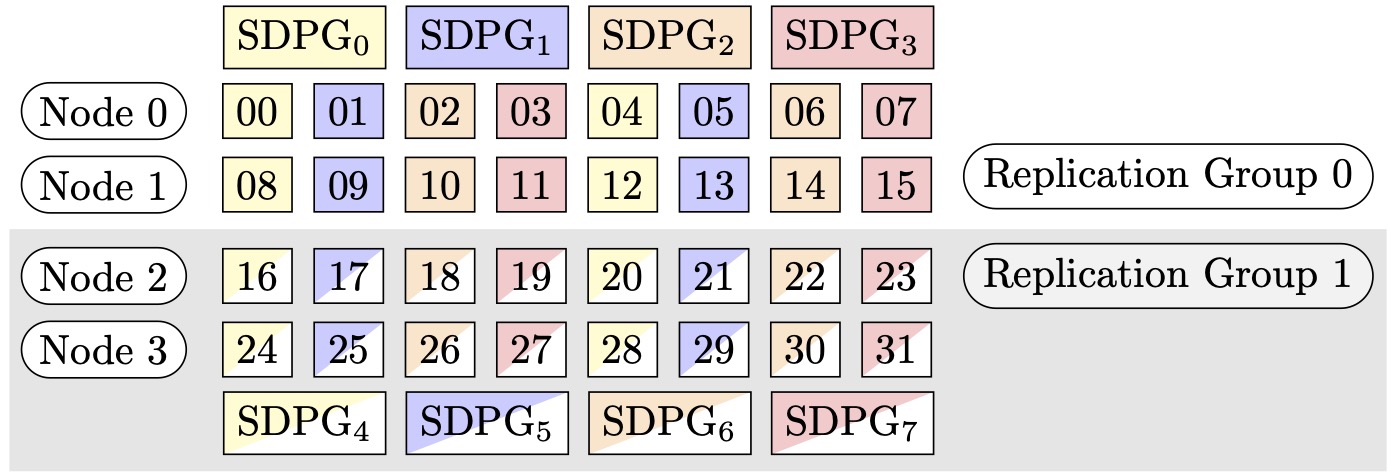
Figura 2: Grupos de paralelismo de dados fragmentados para (nós, grau paralelo de dados fragmentados, grau paralelo do tensor) = (4, 4, 4), onde cada retângulo representa uma GPU com índices de 0 a 31. As GPUs formam grupos de paralelismo de dados fragmentados de SDPG0 a SDPG7. Os grupos de replicação são ({SDPG0, SDPG4}, {SDPG1, SDPG5}, {SDPG2, SDPG6} e {SDPG3, SDPG7}); cada par de grupos de replicação compartilha a mesma cor, mas é preenchido de forma diferente.
Como ativar o paralelismo de dados fragmentados com o paralelismo de tensores
Para usar o paralelismo de dados fragmentados com o paralelismo de tensores, você precisa definir ambos sharded_data_parallel_degree e tensor_parallel_degree na configuração para distribution um objeto da classe estimadora PyTorch do SageMaker.
Você também precisa ativar prescaled_batch. Isso significa que, em vez de cada GPU ler seu próprio lote de dados, cada grupo paralelo de tensores lê coletivamente um lote combinado do tamanho de lote escolhido. Efetivamente, em vez de dividir o conjunto de dados em partes iguais ao número de GPUs (ou tamanho paralelo de dados, smp.dp_size()), ele se divide em partes iguais ao número de GPUs dividido por tensor_parallel_degree (também chamado de tamanho paralelo de dados reduzido smp.rdp_size()). Para obter mais detalhes sobre o lote pré-escalado, consulte Lote pré-escaladotrain_gpt_simple.py
O seguinte trecho de código mostra um exemplo de criação de um objeto de estimativa PyTorch com base no cenário acima mencionado em Exemplo 2:
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
Dicas e considerações para usar o paralelismo de dados fragmentados
Considere o seguinte ao usar o paralelismo de dados fragmentados da biblioteca de paralelismo de modelos do SageMaker:
-
O paralelismo de dados fragmentados é compatível com o treinamento FP16. Para executar o treinamento do FP16, consulte a seção Treinamento FP16 com paralelismo de modelos.
-
O paralelismo de dados fragmentados é compatível com o paralelismo de tensores. Os itens a seguir são o que talvez você precise considerar para usar o paralelismo de dados fragmentados com o paralelismo de tensores.
-
Ao usar paralelismo de dados fragmentados com paralelismo de tensores, as camadas de incorporação também são distribuídas automaticamente pelo grupo paralelo de tensores. Em outras palavras, o parâmetro
distribute_embeddingé definido automaticamente comoTrue. Para obter mais informações sobre paralelismo de tensores, consulte Paralelismo de tensores. -
Observe que o paralelismo de dados fragmentados com o paralelismo de tensores atualmente usa os coletivos NCCL como backend da estratégia de treinamento distribuído.
Para saber mais, consulte a seção Paralelismo de dados fragmentados com paralelismo de tensores.
-
-
Atualmente, o paralelismo de dados fragmentados é incompatível com o paralelismo de pipeline ou com a fragmentação de estado do otimizador. Para ativar o paralelismo de dados fragmentados, desative a fragmentação de estado do otimizador e defina o grau paralelo do pipeline como 1.
-
Os atributos de ponto de verificação de ativação e descarregamento de ativação são compatíveis com o paralelismo de dados fragmentados.
-
Para usar o paralelismo de dados fragmentados com o acúmulo de gradiente, defina o argumento
backward_passes_per_steppara o número de etapas de acumulação ao agrupar seu modelo com o módulosmdistributed.modelparallel.torch.DistributedModel. Isso garante que a operação AllReducede gradiente nos grupos de replicação do modelo (grupos de fragmentação) ocorra no limite do acúmulo de gradiente. -
Você pode verificar seus modelos treinados com paralelismo de dados fragmentados usando as APIs de ponto de verificação da biblioteca
smp.save_checkpointesmp.resume_from_checkpoint. Para obter mais informações, consulte Apontando pontos de verificação de um modelo PyTorch (para a biblioteca de paralelismo de modelos do SageMaker v1.10.0 e versões posteriores). -
O comportamento do parâmetro de configuração
delayed_parameter_initializationmuda sob o paralelismo de dados fragmentados. Quando esses dois atributos são ativados simultaneamente, os parâmetros são inicializados imediatamente após a criação do modelo de forma fragmentada, em vez de atrasar a inicialização do parâmetro, para que cada classificação inicialize e armazene seu próprio fragmento de parâmetros. -
Quando o paralelismo de dados fragmentados é ativado, a biblioteca executa o recorte de gradiente internamente quando a chamada
optimizer.step()é executada. Você não precisa usar APIs utilitárias para recorte de gradiente, comotorch.nn.utils.clip_grad_norm_(). Para ajustar o valor limite para o recorte de gradiente, você pode defini-lo por meio do parâmetro sdp_gradient_clippingpara a configuração do parâmetro de distribuição ao construir o estimador PyTorch do SageMaker, conforme mostrado na seção Como aplicar o paralelismo de dados fragmentados ao seu trabalho de treinamento.
