As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como o RCF funciona
O Amazon SageMaker AI Random Cut Forest (RCF) é um algoritmo não supervisionado para detectar pontos de dados anômalos em um conjunto de dados. Trata-se de observações que divergem de outros dados padronizados ou bem-estruturados. As anomalias podem se manifestar como picos inesperados em dados de séries temporais, pausas na periodicidade ou pontos de dados inclassificáveis. São de fácil descrição quando visualizados em um gráfico, pois frequentemente se distinguem dos dados "normais". A inclusão dessas anomalias em um conjunto de dados pode aumentar drasticamente a complexidade de uma tarefa de machine learning, já que os dados "normais" podem ser descritos com um modelo simples.
A principal ideia subjacente do algoritmo RCF é criar uma floresta de árvores em que cada árvore é obtida por meio de uma partição de uma amostra de dados de treinamento. Por exemplo, uma amostra aleatória dos dados de entrada é determinada pela primeira vez. A amostra aleatória é, então, particionada de acordo com o número de árvores na floresta. Cada árvore recebe uma partição e organiza esse subconjunto de pontos em uma árvore k-d. A pontuação de anomalia atribuída a um ponto de dados pela árvore é definida como a alteração esperada na complexidade dessa árvore, resultando na inclusão do ponto à árvore. Além disso, tal resultado, na aproximação, é inversamente proporcional à profundidade resultante do ponto na árvore. Para atribuir uma pontuação de anomalia, o Random Cut Forest calcula a pontuação média de cada árvore integrante e escala o resultado em relação ao tamanho da amostra. O algoritmo RCF baseia-se no item descrito na referência [1].
Obter amostra de dados de forma aleatória
A primeira etapa do algoritmo RCF é obter uma amostra aleatória dos dados de treinamento. Em particular, suponha que queiramos uma amostra de tamanho
 do total de
do total de
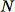 pontos de dados. Se os dados de treinamento forem pequenos o suficiente, todo o conjunto de dados poderá ser usado, poderíamos desenhar aleatoriamente
elementos desse conjunto. No entanto, os dados de treinamento frequentemente são muito grandes para se encaixarem todos de uma vez, e essa abordagem não é viável. Em vez disso, usamos uma técnica chamada de amostragem de reservatório.
pontos de dados. Se os dados de treinamento forem pequenos o suficiente, todo o conjunto de dados poderá ser usado, poderíamos desenhar aleatoriamente
elementos desse conjunto. No entanto, os dados de treinamento frequentemente são muito grandes para se encaixarem todos de uma vez, e essa abordagem não é viável. Em vez disso, usamos uma técnica chamada de amostragem de reservatório.
A amostragem de reservatório , em que os elementos no conjunto de dados só podem ser observados um de cada vez ou em lotes. De fato, a amostragem de reservatório funciona mesmo quando
não é conhecido a priori. Se apenas uma amostra for solicitada, como quando
, em que os elementos no conjunto de dados só podem ser observados um de cada vez ou em lotes. De fato, a amostragem de reservatório funciona mesmo quando
não é conhecido a priori. Se apenas uma amostra for solicitada, como quando
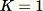 , o algoritmo será:
, o algoritmo será:
Algoritmo: Amostragem de reservatório
-
Entrada: conjunto de dados ou fluxo de dados
-
Inicialize a amostra aleatória

-
Para cada amostra observada
 :
:-
Escolha um número aleatório uniforme
![Equation in text-form: \xi \in [0,1]](images/rcf6.jpg)
-
Se

-
Definir

-
-
-
Return

Esse algoritmo seleciona uma amostra aleatória, de modo que
 para todos os
para todos os
 . Quando
. Quando
 , o algoritmo é mais complicado. Além disso, é necessário estabelecer uma distinção entre a amostragem aleatória que está com substituição e a que está sem. O RCF realiza uma amostragem de reservatório aumentada sem substituição nos dados de treinamento com base nos algoritmos descritos em [2].
, o algoritmo é mais complicado. Além disso, é necessário estabelecer uma distinção entre a amostragem aleatória que está com substituição e a que está sem. O RCF realiza uma amostragem de reservatório aumentada sem substituição nos dados de treinamento com base nos algoritmos descritos em [2].
Treinar um modelo RFC e produzir inferências
A próxima etapa do RCF é construir uma floresta de corte aleatório usando a amostra aleatória de dados. Primeiramente, a amostra é particionada em uma série de partições de tamanho igual, na mesma quantidade de árvores da floresta. Em seguida, cada partição é enviada para uma árvore individual. Para organizar recursivamente a partição em uma árvore binária, a árvore particiona o domínio de dados em caixas delimitadoras.
Esse procedimento é mais bem ilustrado com um exemplo. Digamos que uma árvore receba o seguinte conjunto de dados bidimensional: A árvore correspondente é inicializada para o nó raiz:

Figura: Um conjunto de dados bidimensional onde a maioria dos dados reside em um cluster (azul), exceto pelo ponto de dados anormal (laranja). A árvore é inicializada com um nó raiz.
O algoritmo RCF organiza esses dados em uma árvore. Primeiramente, ele calcula uma caixa delimitadora dos dados, selecionando uma dimensão aleatória (atribuindo mais peso às dimensões com maior "variação"). Em seguida, aleatoriamente determina a posição de um "corte" hiperplano através da dimensão. Os dois subespaços resultantes definem a própria subárvore deles. Nesse exemplo, o corte ocorre para separar um ponto isolado do restante da amostra. O primeiro nível da árvore binária resultante consiste em dois nós: um com a subárvore de pontos à esquerda do corte inicial, e o outro representando o único ponto à direita.

Figura: Um corte aleatório particionando o conjunto de dados bidimensional. É mais provável que um ponto de dados anormal resida isoladamente em uma caixa delimitadora, em uma profundidade menor do que outros pontos na árvore.
As caixas delimitadoras são então calculadas para as metades esquerda e direita dos dados, e o processo é repetido até que todas as folhas da árvore represente um único ponto de dados da amostra. Observe que, se o ponto único estiver suficientemente longe, é mais provável que um corte aleatório resulte em seu isolamento. Essa observação fornece a intuição de que a profundidade da árvore é, a grosso modo, inversamente proporcional à pontuação de anomalia.
Na execução de inferência com um modelo RCF treinado, a pontuação de anomalia final é registrada como a média entre as pontuações registradas por cada árvore. Observe que é frequente o fato de que o novo ponto de dados ainda não reside na árvore. Para determinar a pontuação associada ao novo ponto, o ponto de dados é inserido na árvore em questão, que, por sua vez, é eficientemente (e temporariamente) remontada de uma maneira equivalente ao processo de treinamento descrito acima. Ou seja, a árvore resultante é como se o ponto de dados de entrada fosse um membro da amostra usada para construir a árvore no começo. A pontuação registrada é inversamente proporcional à profundidade do ponto de entrada na árvore.
Escolher hiperparâmetros
Os principais hiperparâmetros usados para ajustar o modelo RCF são num_trees e num_samples_per_tree. Se você aumentar o num_trees, o ruído observado em pontuações de anomalia será reduzido, já que a última pontuação é a média das pontuações registradas por cada árvore. Embora o valor ideal dependa da aplicação, recomendamos começar usando 100 árvores, para que haja equilíbrio entre o ruído das pontuações e a complexidade do modelo. Observe que o tempo de inferência é proporcional ao número de árvores. Embora o tempo de treinamento também seja afetado, ele é controlado pelo algoritmo de amostragem de reservatório descrito acima.
O parâmetro num_samples_per_tree está relacionado à densidade esperada de anomalias no conjunto de dados. Especificamente, num_samples_per_tree deve ser escolhido de modo que 1/num_samples_per_tree se aproxime da proporção entre dados anormais e dados normais. Por exemplo, se 256 amostras forem usadas em cada árvore, o esperado é que os dados contenham anomalias de 1/256 ou aproximadamente 0,4% do tempo. Novamente, um valor ideal para esse hiperparâmetro depende da aplicação.
Referências
-
Sudipto Guha, Nina Mishra, Gourav Roy e Okke Schrijvers. "Robust random cut forest based anomaly detection on streams." Em International Conference on Machine Learning, pp. 2712-2721. 2016.
-
Byung-Hoon Park, George Ostrouchov, Nagiza F. Samatova e Al Geist. "Reservoir-based random sampling with replacement from data stream." Em Proceedings of the 2004 SIAM International Conference on Data Mining, pp. 492-496. Society for Industrial and Applied Mathematics, 2004.
