As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Use o aprendizado por reforço com a Amazon AI SageMaker
O aprendizado por reforço (RL) combina campos como ciência da computação, neurociência e psicologia para determinar como mapear situações em ações para maximizar um sinal numérico de recompensa. Essa noção de um sinal de recompensa no RL tem origem em pesquisas neurocientíficas sobre como o cérebro humano toma decisões sobre quais ações maximizam a recompensa e minimizam a punição. Na maioria das situações, os humanos não recebem instruções explícitas sobre quais ações tomar, mas devem aprender quais ações geram as recompensas mais imediatas e como essas ações influenciam situações e consequências futuras.
O problema da RL é formalizado usando processos de decisão de Markov (Markov Decision Processes, MDPs) que se originam da teoria dos sistemas dinâmicos. Os MDPs visam registrar detalhes gerais de um problema real que um agente de aprendizado encontra durante algum período na tentativa de atingir algum objetivo final. O agente de aprendizado deve ser capaz de determinar o estado atual de próprio ambiente e identificar possíveis ações que afetam o estado atual do agente de aprendizado. Além disso, os objetivos do agente de aprendizado devem se correlacionar fortemente com o estado do ambiente. Uma solução para um problema formulado dessa forma é conhecida como método de aprendizado por reforço.
Quais são as diferenças entre paradigmas de aprendizado por reforço, supervisionado e não supervisionado?
O machine learning pode ser dividido em três paradigmas de aprendizado distintos: supervisionado, não supervisionado e por reforço.
No aprendizado supervisionado, um supervisor externo fornece um conjunto de treinamento com exemplos rotulados. Cada exemplo contém informações sobre uma situação, pertence a uma categoria e tem um rótulo identificando a categoria à qual pertence. O objetivo do aprendizado supervisionado é generalizar para prever corretamente situações que não estão presentes nos dados do treinamento.
Por outro lado, o RL lida com problemas interativos, tornando inviável reunir todos os exemplos possíveis de situações com rótulos corretos que um agente possa encontrar. Esse tipo de aprendizado é mais promissor quando um agente é capaz de aprender com precisão a partir de sua própria experiência e se adaptar adequadamente.
No aprendizado não supervisionado, um agente aprende descobrindo a estrutura em dados não rotulados. Embora um agente de RL possa se beneficiar da descoberta de uma estrutura com base nas experiências, o único propósito do RL é maximizar um sinal de recompensa.
Por que a aprendizado por reforço é importante?
O RL é adequado para resolver problemas grandes e complexos, como gerenciamento da cadeia de suprimentos, sistemas HVAC, robótica industrial, inteligência artificial de jogos, sistemas de diálogo e veículos autônomos. Como os modelos de RL aprendem por um processo contínuo de receber prêmios e punições por cada ação tomada pelo agente, é possível treinar sistemas para tomar decisões sob incerteza e em ambientes dinâmicos.
Processo de decisão de Markov (MDP)
A RL é baseada em modelos chamados Processos de decisão de Markov (MDPs). Um MDP consiste em uma série de etapas de tempo. Cada etapa de tempo consiste no seguinte:
- Environment
-
Define o espaço no qual o modelo de RL opera. Isso pode ser um ambiente do mundo real ou um simulador. Por exemplo, se você treina um veículo físico autônomo em uma estrada física, isso seria um ambiente do mundo real. Se você treina um programa de computador que modela um veículo autônomo dirigindo em uma estrada, isso é um simulador.
- Estado
-
Especifica todas as informações sobre o ambiente e etapas anteriores que são relevantes para o futuro. Por exemplo, em um modelo de RL em que um robô pode se mover em qualquer direção a qualquer momento, a posição do robô no momento atual é o estado, porque, se sabemos onde o robô está, não é necessário conhecer os passos que ele seguiu para chegar lá.
- Ação
-
O que o agente faz. Por exemplo, o robô dá um passo à frente.
- Prêmio
-
Um número que representa o valor do estado resultante da última ação que o agente realizou. Por exemplo, se o objetivo é que um robô encontre um tesouro, o prêmio por encontrar o tesouro pode ser 5, e o prêmio por não encontrar tesouro pode ser 0. O modelo de RL tenta encontrar uma estratégia que otimiza o prêmio cumulativo a longo prazo. Essa estratégia é chamada de política.
- Observação
-
Informações sobre o estado do ambiente que estão disponíveis para o agente em cada etapa. Este pode ser o estado inteiro ou pode ser apenas uma parte do estado. Por exemplo, o agente em um modelo de xadrez poderia observar todo o estado do tabuleiro em qualquer etapa, mas um robô em um labirinto só poderia observar uma pequena área do labirinto que ele ocupa atualmente.
Normalmente, o treinamento em RL consiste em muitos episódios. Um episódio consiste em todas as etapas de tempo em um MDP, desde o estado inicial até que o ambiente atinja o estado terminal.
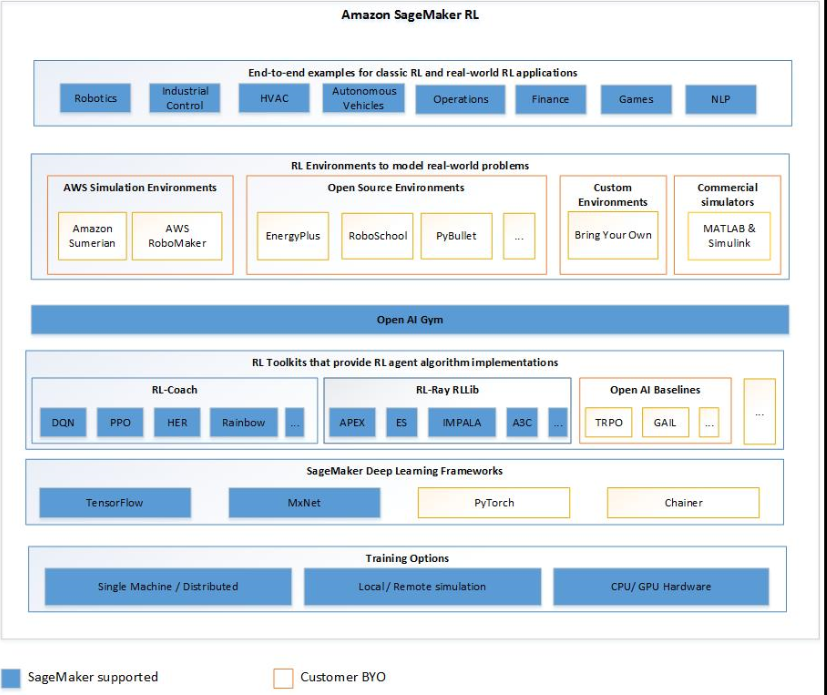
Principais recursos do Amazon SageMaker AI RL
Para treinar modelos de RL em SageMaker AI RL, use os seguintes componentes:
-
Uma estrutura de aprendizado profundo (DL). Atualmente, a SageMaker IA suporta RL no Apache MXNet TensorFlow e no Apache MXNet.
-
Um kit de ferramentas de RL. Um kit de ferramentas de RL gerencia a interação entre o agente e o ambiente e fornece uma ampla seleção de algoritmos de RL de última geração. SageMaker A IA suporta os kits de ferramentas Intel Coach e Ray RLLib. Para obter informações sobre o Intel Coach, consulte https://nervanasystems.github.io/coach/
. Para obter informações sobre Ray RLLib, consulte. https://ray.readthedocs.io/en/latest/rllib.html -
Um ambiente de RL. Você pode usar ambientes personalizados, ambientes de código aberto ou ambientes comerciais. Para mais informações, consulte Ambientes de RL na Amazon AI SageMaker.
O diagrama a seguir mostra os componentes do RL que são compatíveis com o SageMaker AI RL.
Cadernos de amostra de aprendizado por reforço
Para ver exemplos completos de código, consulte os exemplos de cadernos de aprendizado por reforço no repositório
