As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Comece com scripts básicos de ciclo de vida fornecidos por HyperPod
Esta seção mostra cada componente do fluxo básico de configuração do Slurm on HyperPod em uma abordagem de cima para baixo. Ele começa com a preparação de uma solicitação de criação de HyperPod cluster para executar o CreateCluster API e se aprofunda na estrutura hierárquica até os scripts de ciclo de vida. Use os exemplos de scripts de ciclo de vida fornecidos no repositório do Awsome Distributed Training
git clone https://github.com/aws-samples/awsome-distributed-training/
Os scripts básicos do ciclo de vida para configurar um cluster Slurm estão disponíveis em SageMaker HyperPod . 1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
O fluxograma a seguir mostra uma visão geral detalhada de como você deve criar os scripts básicos do ciclo de vida. As descrições abaixo do diagrama e do guia de procedimentos explicam como eles funcionam durante a HyperPod CreateCluster API chamada.
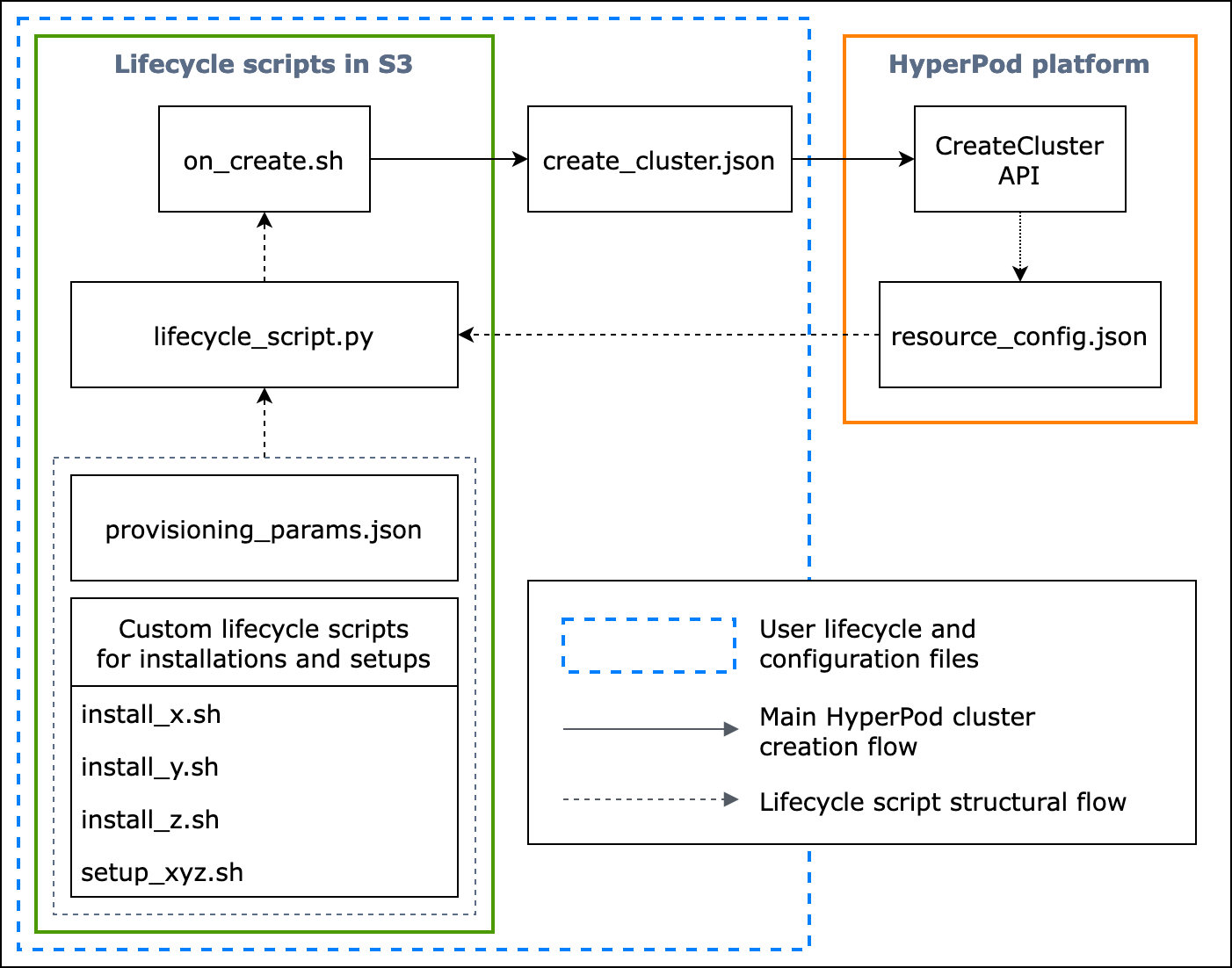
Figura: Um fluxograma detalhado da criação do HyperPod cluster e da estrutura dos scripts do ciclo de vida. (1) As setas tracejadas são direcionadas para onde as caixas são “chamadas” e mostram o fluxo dos arquivos de configuração e a preparação dos scripts do ciclo de vida. Tudo começa com a preparação provisioning_parameters.json e os scripts do ciclo de vida. Eles são então codificados lifecycle_script.py para uma execução coletiva em ordem. E a execução do lifecycle_script.py script é feita pelo script on_create.sh shell, que deve ser executado no terminal da HyperPod instância. (2) As setas sólidas mostram o fluxo principal de criação do HyperPod cluster e como as caixas são “chamadas para” ou “enviadas para”. on_create.shé necessário para a solicitação de criação de cluster, no formulário Criar uma solicitação de cluster create_cluster.json ou no formulário Criar uma solicitação de cluster na interface do console. Depois de enviar a solicitação, HyperPod executa o CreateCluster API com base nas informações de configuração fornecidas da solicitação e nos scripts do ciclo de vida. (3) A seta pontilhada indica que a HyperPod plataforma cria resource_config.json nas instâncias do cluster durante o provisionamento de recursos do cluster. resource_config.jsoncontém informações sobre os recursos do HyperPod cluster, como o clusterARN, os tipos de instância e os endereços IP. É importante observar que você deve preparar os scripts de ciclo de vida para esperar o resource_config.json arquivo durante a criação do cluster. Para obter mais informações, consulte o guia de procedimentos abaixo.
O guia de procedimentos a seguir explica o que acontece durante a criação HyperPod do cluster e como os scripts básicos do ciclo de vida são projetados.
-
create_cluster.json— Para enviar uma solicitação de criação de HyperPod cluster, você prepara um arquivo deCreateClustersolicitação em JSON formato. Neste exemplo de melhores práticas, presumimos que o arquivo de solicitação tenha um nomecreate_cluster.json. Escrevacreate_cluster.jsonpara provisionar um HyperPod cluster com grupos de instâncias. A melhor prática é adicionar o mesmo número de grupos de instâncias que o número de nós do Slurm que você planeja configurar no HyperPod cluster. Certifique-se de dar nomes distintos aos grupos de instâncias que você atribuirá aos nós do Slurm que você planeja configurar.Além disso, é necessário especificar um caminho de bucket do S3 para armazenar todo o conjunto de arquivos de configuração e scripts de ciclo de vida no nome do campo
InstanceGroups.LifeCycleConfig.SourceS3Urino formulário deCreateClustersolicitação e especificar o nome do arquivo de um script de shell de ponto de entrada (suponha que ele seja nomeado) para.on_create.shInstanceGroups.LifeCycleConfig.OnCreatenota
Se você estiver usando o formulário de envio Criar um cluster na interface do usuário do HyperPod console, o console gerencia o preenchimento e o envio da
CreateClustersolicitação em seu nome e a executaCreateClusterAPI no back-end. Nesse caso, você não precisa criarcreate_cluster.json; em vez disso, certifique-se de especificar as informações corretas de configuração do cluster no formulário de envio Criar um cluster. -
on_create.sh— Para cada grupo de instâncias, você precisa fornecer um script de shell de ponto de entrada, executar comandoson_create.sh, executar scripts para instalar pacotes de software e configurar o ambiente de HyperPod cluster com o Slurm. As duas coisas que você precisa preparar são umaprovisioning_parameters.jsonexigência HyperPod para configurar o Slurm e um conjunto de scripts de ciclo de vida para instalar pacotes de software. Esse script deve ser escrito para localizar e executar os seguintes arquivos, conforme mostrado no script de amostra emon_create.sh. nota
Certifique-se de carregar todo o conjunto de scripts de ciclo de vida no local do S3 especificado.
create_cluster.jsonVocê também deve colocar o seuprovisioning_parameters.jsonno mesmo local.-
provisioning_parameters.json— Este é umFormulário de configuração para provisionamento de nós do Slurm em HyperPod. Oon_create.shscript encontra esse JSON arquivo e define a variável de ambiente para identificar o caminho até ele. Por meio desse JSON arquivo, você pode configurar os nós do Slurm e as opções de armazenamento, como o Amazon FSx for Lustre for Slurm, com os quais se comunicar. Emprovisioning_parameters.json, certifique-se de atribuir os grupos de instâncias do HyperPod cluster usando os nomes especificados noscreate_cluster.jsonnós do Slurm de forma adequada, com base em como você planeja configurá-los.O diagrama a seguir mostra um exemplo de como os dois arquivos de JSON configuração
provisioning_parameters.jsondevem sercreate_cluster.jsongravados para atribuir grupos de HyperPod instâncias aos nós do Slurm. Neste exemplo, assumimos um caso de configuração de três nós do Slurm: nó controlador (gerenciamento), nó de login (que é opcional) e nó de computação (trabalhador).dica
Para ajudá-lo a validar esses dois JSON arquivos, a equipe de HyperPod serviço fornece um script de validação,
validate-config.py. Para saber mais, consulte Valide os arquivos JSON de configuração antes de criar um cluster Slurm no HyperPod. 
Figura: Comparação direta entre
create_cluster.jsona criação HyperPod do cluster e a configuraçãoprovisiong_params.jsondo Slurm. O número de grupos de instâncias emcreate_cluster.jsondeve corresponder ao número de nós que você deseja configurar como nós do Slurm. No caso do exemplo na figura, três nós do Slurm serão configurados em um HyperPod cluster de três grupos de instâncias. Você deve atribuir os grupos de instâncias do HyperPod cluster aos nós do Slurm especificando os nomes dos grupos de instâncias adequadamente. -
resource_config.json— Durante a criação do cluster, olifecycle_script.pyscript é escrito para esperar umresource_config.jsonarquivo do HyperPod. Esse arquivo contém informações sobre o cluster, como tipos de instância e endereços IP.Quando você executa o
CreateClusterAPI, HyperPod cria um arquivo de configuração de recursos/opt/ml/config/resource_config.jsoncom base nocreate_cluster.jsonarquivo. O caminho do arquivo é salvo na variável de ambiente chamadaSAGEMAKER_RESOURCE_CONFIG_PATH.Importante
O
resource_config.jsonarquivo é gerado automaticamente pela HyperPod plataforma e você NOT PRECISA criá-lo. O código a seguir é para mostrar um exemplo doresource_config.jsonque seria criado a partir da criação do cluster com basecreate_cluster.jsonna etapa anterior e para ajudar você a entender o que acontece no back-end e comoresource_config.jsonseria a aparência de uma geração automática.{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py— Esse é o script principal do Python que executa coletivamente scripts de ciclo de vida configurando o Slurm no cluster enquanto está sendo provisionado. HyperPod Esse script lêprovisioning_parameters.jsoneresource_config.jsonrecebe os caminhos especificados ou identificadoson_create.sh, passa as informações relevantes para cada script de ciclo de vida e, em seguida, executa os scripts de ciclo de vida em ordem.Os scripts de ciclo de vida são um conjunto de scripts que você tem total flexibilidade para personalizar para instalar pacotes de software e definir as configurações necessárias ou personalizadas durante a criação do cluster, como configurar o Slurm, criar usuários, instalar o Conda ou o Docker. O
lifecycle_script.pyscript de amostra está preparado para executar outros scripts básicos de ciclo de vida no repositório, como iniciar o Slurm deamons ( start_slurm.sh), montar o FSx Amazon for Lustre () e configurar a contabilidade ( mount_fsx.sh) e a contabilidade () do MariaDB. setup_mariadb_accounting.shRDSsetup_rds_accounting.shVocê também pode adicionar mais scripts, empacotá-los no mesmo diretório e adicionar linhas de código lifecycle_script.pypara permitir a HyperPod execução dos scripts. Para obter mais informações sobre os scripts de ciclo de vida básicos, consulte também 3.1 Scripts de ciclo de vida no repositório Awsome DistributedTraining. GitHub nota
HyperPod é SageMaker HyperPod DLAMI executado em cada instância de um cluster e AMI tem pacotes de software pré-instalados que atendem às compatibilidades e funcionalidades entre eles. HyperPod Observe que, se você reinstalar qualquer um dos pacotes pré-instalados, você será responsável pela instalação de pacotes compatíveis e observe que algumas HyperPod funcionalidades podem não funcionar conforme o esperado.
Além das configurações padrão, mais scripts para instalar o software a seguir estão disponíveis na
utilspasta. O lifecycle_script.pyarquivo já está preparado para incluir linhas de código para executar os scripts de instalação, portanto, consulte os itens a seguir para pesquisar essas linhas e descomentar para ativá-las.-
As linhas de código a seguir são para instalar o Docker
, o Enroot e o Pyxis. Esses pacotes são necessários para executar contêineres Docker em um cluster Slurm. Para ativar essa etapa de instalação, defina o
enable_docker_enroot_pyxisparâmetro comoTruenoconfig.pyarquivo. # Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
Você pode integrar seu HyperPod cluster ao Amazon Managed Service for Prometheus e ao Amazon Managed Grafana para exportar métricas HyperPod sobre o cluster e os nós do cluster para os painéis do Amazon Managed Grafana. Para exportar métricas e usar o painel Slurm, o painel NVIDIA
DCGMExporter e o painel Metrics no Amazon Managed Grafana, você precisa instalar o EFA exportador Slurm para Prometheus, o exportador e o exportador de nós. NVIDIA DCGM EFA Para obter mais informações sobre como instalar os pacotes do exportador e usar os painéis do Grafana em um espaço de trabalho do Amazon Managed Grafana, consulte. SageMaker HyperPod monitoramento de recursos de cluster Para ativar essa etapa de instalação, defina o
enable_observabilityparâmetro comoTruenoconfig.pyarquivo. # Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
Certifique-se de carregar todos os arquivos e scripts de configuração da Etapa 2 para o bucket do S3 que você fornece na
CreateClustersolicitação na Etapa 1. Por exemplo, suponha que vocêcreate_cluster.jsontenha o seguinte."LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }Em seguida, você
"s3://sagemaker-hyperpod-lifecycle/src"deve conteron_create.sh,lifecycle_script.py,provisioning_parameters.json, e todos os outros scripts de configuração. Suponha que você tenha preparado os arquivos em uma pasta local da seguinte maneira.└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.pyPara carregar os arquivos, use o comando S3 da seguinte maneira.
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
