As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como funciona a peneiração SageMaker inteligente
O objetivo da peneiração SageMaker inteligente é examinar seus dados de treinamento durante o processo de treinamento e fornecer apenas amostras mais informativas ao modelo. Durante o treinamento típico com PyTorch, os dados são enviados iterativamente em lotes para o ciclo de treinamento e para dispositivos aceleradores (como GPUs chips Trainium) pelo. PyTorchDataLoader
O diagrama a seguir mostra uma visão geral de como o algoritmo de peneiramento SageMaker inteligente foi projetado.
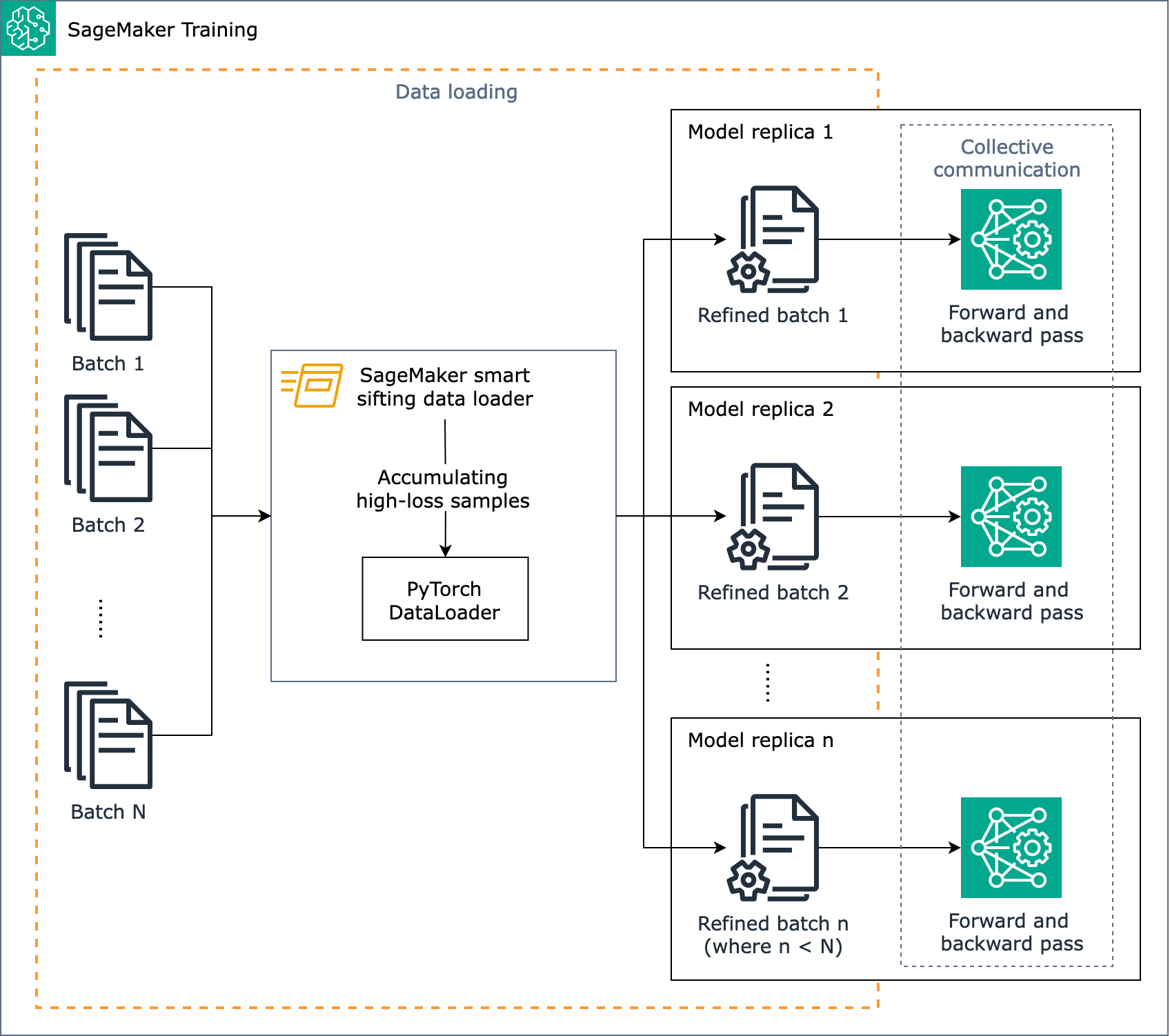
Resumindo, a peneiração SageMaker inteligente opera durante o treinamento à medida que os dados são carregados. O algoritmo de peneiramento SageMaker inteligente executa o cálculo de perdas nos lotes e classifica os dados que não estão melhorando antes da passagem para frente e para trás de cada iteração. O lote de dados refinado é então usado para avançar e retroceder.
nota
A filtragem inteligente de dados SageMaker usa passes adicionais para analisar e filtrar seus dados de treinamento. Por sua vez, há menos retrocessos, pois dados menos impactantes são excluídos do seu trabalho de treinamento. Por esse motivo, os modelos que têm retrocessos longos ou caros obtêm os maiores ganhos de eficiência ao usar a peneiração inteligente. Enquanto isso, se o passe para frente do seu modelo demorar mais do que o passe para trás, a sobrecarga poderá aumentar o tempo total de treinamento. Para medir o tempo gasto em cada passagem, você pode executar um trabalho de treinamento piloto e coletar registros que registram o tempo nos processos. Considere também usar o SageMaker Profiler, que fornece ferramentas de criação de perfil e aplicativos de interface do usuário. Para saber mais, consulte Amazon SageMaker Profiler.
SageMaker A peneiração inteligente funciona para trabalhos de treinamento PyTorch baseados com o clássico paralelismo distribuído de dados, que cria réplicas de modelos em cada trabalhador e executa. GPU AllReduce Ele funciona com PyTorch DDP a biblioteca paralela de dados SageMaker distribuídos.
