As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Usar o estado de mapa no modo distribuído para workloads paralelas em grande escala no Step Functions
Gerenciar estados e transformar dados
Saiba mais sobre como transmitir dados entre estados com variáveis e transformar dados com JSONata.
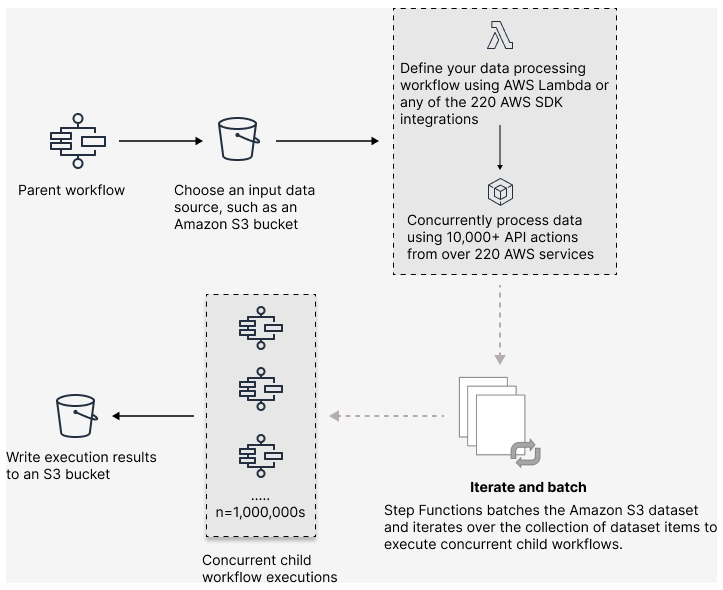
Com o Step Functions, você pode orquestrar workloads paralelas em grande escala para realizar tarefas, como processamento sob demanda de dados semiestruturados. Essas workloads paralelas permitem que você processe simultaneamente fontes de dados em grande escala armazenadas no Amazon S3. Por exemplo, você pode processar um único arquivo JSON ou CSV que contém grandes quantidades de dados. Ou você pode processar um grande conjunto de objetos do Amazon S3.
Para configurar uma workload paralela em grande escala nos fluxos de trabalho, inclua um estado Map no modo distribuído. O estado Mapa processa itens em um conjunto de dados simultaneamente. Um estado Map definido como Distribuído é conhecido como estado Mapa distribuído. No modo distribuído, o estado Map permite o processamento simultâneo em grande escala. No modo distribuído, o estado Map processa os itens no conjunto de dados em iterações chamadas execuções de fluxo de trabalho secundário. É possível especificar o número de execuções de fluxo de trabalho secundário que podem ser executadas em paralelo. Cada execução de fluxo de trabalho secundário tem seu próprio histórico de execução separado do fluxo de trabalho principal. Se você não especificar, o Step Functions executará 10 mil execuções paralelas de fluxo de trabalho secundário.
A ilustração a seguir explica como você pode configurar workloads paralelas em grande escala em seus fluxos de trabalho.
Aprenda em um workshop
Saiba como tecnologias sem servidor, como o Step Functions e o Lambda, podem simplificar o gerenciamento e o ajuste de escala, descarregar tarefas indiferenciadas e enfrentar os desafios do processamento distribuído de dados em grande escala. No decorrer do processo, você trabalhará com um mapa distribuído para processamento de alta simultaneidade. O workshop também apresenta as práticas recomendadas para otimizar os fluxos de trabalho e casos de uso práticos para processamento de reclamações, verificação de vulnerabilidades e simulação de Monte Carlo.
Workshop: Processamento de Large-scale dados com Step Functions
Neste tópico
Principais termos
- Modo distribuído
-
Um modo de processamento do estado Mapa. Nesse modo, cada iteração do estado
Mapé executada como uma execução de fluxo de trabalho secundário que permite processamento simultâneo em grande escala. Cada execução de fluxo de trabalho secundário tem seu próprio histórico de execução, que é separado do histórico de execução do fluxo de trabalho principal. Esse modo é compatível com a leitura de entradas de fontes de dados do Amazon S3 em grande escala. - Estado Mapa distribuído
-
Um estado Mapa definido para o modo de processamento Distribuído.
- Fluxo de trabalho do mapa
Um conjunto de etapas que um estado
Mapexecuta.- Fluxo de trabalho principal
-
Um fluxo de trabalho que contém um ou mais estados Mapa distribuído.
- Execuções de fluxo de trabalho secundário
-
Uma iteração do estado Mapa Distribuído. Uma execução de fluxo de trabalho secundário tem seu próprio histórico de execução, que é separado do histórico de execução do fluxo de trabalho principal.
- Execução de mapa
-
Ao executar um estado
Mapno modo distribuído, o Step Functions cria um recurso de Execução de mapa. Uma Execução de mapa se refere a um conjunto de execuções de fluxo de trabalho secundário que um estado Mapa distribuído inicia e às configurações de runtime que controlam essas execuções. O Step Functions atribui um nome do recurso da Amazon (ARN) à Execução de mapa. Você pode examinar uma Execução de mapa no console do Step Functions. Você também pode invocar a ação da APIDescribeMapRun.As execuções do fluxo de trabalho infantil de um Map Run emitem métricas para CloudWatch;. Essas métricas terão um ARN de máquina de estado rotulado com o seguinte formato:
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUIDPara obter mais informações, consulte Visualizar execuções de mapa.
Exemplo de definição do estado de mapa distribuído (JSONPath)
Use o estado Map no modo distribuído quando precisar orquestrar workloads paralelas em grande escala que atendam a qualquer combinação das seguintes condições:
O tamanho do conjunto de dados excede 256 KiB.
O histórico de eventos de execução do fluxo de trabalho excederia 25 mil entradas.
Você precisa processar simultaneamente mais de 40 iterações simultâneas.
O exemplo de definição de estado Mapa Distribuído a seguir especifica o conjunto de dados como um arquivo CSV armazenado em um bucket do Amazon S3. Ele também especifica uma função do Lambda que processa os dados em cada linha do arquivo CSV. Uma vez que esse exemplo usa um arquivo CSV, ele também especifica a localização dos cabeçalhos das colunas do CSV. Para ver a definição completa da máquina de estado desse exemplo, consulte o tutorial Copiar dados de CSV em grande escala usando o Mapa distribuído.
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}Permissões para executar o Mapa distribuído
Ao incluir um estado Mapa Distribuído nos fluxos de trabalho, o Step Functions precisa de permissões apropriadas para permitir que o perfil de máquina de estado invoque a ação da API StartExecution para o estado Mapa Distribuído.
O exemplo de política do IAM a seguir concede os privilégios mínimos necessários ao perfil da máquina de estado para executar o estado Mapa Distribuído.
nota
Substitua stateMachineNamearn:aws:states:region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
Além disso, você precisa garantir que tenha os privilégios mínimos necessários para acessar os AWS recursos usados no estado do Mapa Distribuído, como os buckets do Amazon S3. Para mais informações, consulte Políticas do IAM para usar estados de mapa distribuído.
Campos do estado Mapa Distribuído
Para usar o estado Mapa distribuído em fluxos de trabalho, especifique um ou mais dos campos a seguir. Você especifica esses campos além dos campos de estado comuns.
Type(Obrigatório)-
Define o tipo de estado, como
Map. ItemProcessor(Obrigatório)-
Contém os seguintes objetos JSON que especificam a definição e o modo de processamento estado
Map.-
ProcessorConfig: objeto JSON que especifica o modo de processamento de itens, com os seguintes subcampos:-
Mode— Definido comoDISTRIBUTEDpara usar o estadoMapno modo distribuído.Atenção
O modo distribuído é aceito nos fluxos de trabalho padrão, mas não nos fluxos de trabalho expressos.
-
ExecutionType— Especifica o tipo de execução do fluxo de trabalho do mapa como PADRÃO ou EXPRESSO. Você deve fornecer esse campo se tiver especificadoDISTRIBUTEDpara o subcampoMode. Para ver mais informações sobre tipos de fluxos de trabalho, consulte Escolher o tipo de fluxo de trabalho no Step Functions.
-
StartAt— Especifica uma string que indica o primeiro estado em um fluxo de trabalho. Essa string diferencia maiúsculas de minúsculas e deve corresponder ao nome de um dos objetos de estado. Esse estado é executado primeiro para cada item no conjunto de dados. Qualquer entrada de execução fornecida ao estadoMapé transmitida primeiro para o estadoStartAt.States– Um objeto JSON que contém um conjunto de estados delimitado por vírgulas. Nesse objeto, você define o Map workflow.
-
ItemReader-
Especifica um conjunto de dados e sua localização. O estado
Maprecebe seus dados de entrada do conjunto de dados especificado.No modo distribuído, você pode usar uma carga JSON transferida de um estado anterior ou uma fonte de dados do Amazon S3 em grande escala como conjunto de dados. Para obter mais informações, consulte ItemReader (Mapa).
Items(opcional, somente JSONata)-
Uma matriz JSON, um objeto JSON ou uma expressão JSONata que deve ser avaliada como uma matriz ou objeto.
ItemsPath(opcional, somente JSONPath)-
Especifica um caminho de referência usando a JsonPath
sintaxe para selecionar o nó JSON que contém uma matriz de itens ou um objeto com pares de valores-chave dentro da entrada de estado. No modo distribuído, você especifica esse campo somente quando usa uma matriz ou objeto JSON de uma etapa anterior como entrada de estado. Para obter mais informações, consulte ItemsPath (Mapa, JSONPath somente).
ItemSelector(opcional, somente JSONPath)-
Substitui os valores de itens individuais do conjunto de dados antes de serem transmitidos para cada iteração do estado
Map.Nesse campo, você especifica uma entrada JSON válida que contém um conjunto de pares de valores-chave. Esses pares podem ser valores estáticos configurados na definição da máquina de estado, valores selecionados da entrada de estado usando um caminho ou valores acessados a partir do objeto de contexto. Para obter mais informações, consulte ItemSelector (mapa).
ItemBatcher(Opcional)-
Especifica o processamento dos itens do conjunto de dados em lotes. Em seguida, cada execução de fluxo de trabalho secundário recebe um lote desses itens como entrada. Para obter mais informações, consulte ItemBatcher (mapa).
MaxConcurrency(Opcional)-
Especifica o número de execuções de fluxo de trabalho secundário que podem ser executadas em paralelo. O intérprete só permite até o número especificado de execuções paralelas de fluxo de trabalho secundário. Se você não especificar um valor de processamento simultâneo ou defini-lo como zero, o Step Functions não limitará o processamento simultâneo e fará 10 mil execuções paralelas do fluxo de trabalho secundário. Nos estados JSONata, é possível especificar uma expressão JSONata que seja avaliada como um número inteiro.
nota
Embora você possa especificar um limite maior de simultaneidade para execuções paralelas de fluxos de trabalho secundários, recomendamos que você não exceda a capacidade de um AWS serviço downstream, como. AWS Lambda
MaxConcurrencyPath(opcional, somente JSONPath)-
Para fornecer dinamicamente um valor máximo de processamento simultâneo a partir da entrada de estado usando um caminho de referência, use
MaxConcurrencyPath. Quando resolvido, o caminho de referência deve selecionar um campo cujo valor seja um número inteiro não negativo.nota
Um estado
Mapnão pode incluirMaxConcurrencyeMaxConcurrencyPath. ToleratedFailurePercentage(Opcional)-
Define a porcentagem de itens com falha a serem tolerados em uma Execução de mapa. A Execução de mapa falhará automaticamente se exceder essa porcentagem. O Step Functions calcula a porcentagem de itens com falha como resultado do número total de itens com falha ou com tempo limite esgotado dividido pelo número total de itens. Você deve especificar um valor entre zero e cem. Para obter mais informações, consulte Definir limites de falha para estados de mapa distribuído no Step Functions.
Nos estados JSONata, é possível especificar uma expressão JSONata que seja avaliada como um número inteiro.
ToleratedFailurePercentagePath(opcional, somente JSONPath)-
Para fornecer dinamicamente um valor de porcentagem de falha tolerada com base na entrada de estado utilizando um caminho de referência, use
ToleratedFailurePercentagePath. Quando resolvido, o caminho de referência deve selecionar um campo cujo valor seja um número entre zero e cem. ToleratedFailureCount(Opcional)-
Define o número de itens com falha a serem tolerados em uma Execução de mapa. A Execução de mapa falhará automaticamente se exceder esse número. Para obter mais informações, consulte Definir limites de falha para estados de mapa distribuído no Step Functions.
Nos estados JSONata, é possível especificar uma expressão JSONata que seja avaliada como um número inteiro.
ToleratedFailureCountPath(opcional, somente JSONPath)-
Para fornecer dinamicamente um valor de contagem de falhas toleradas com base na entrada de estado utilizando um caminho de referência, use
ToleratedFailureCountPath. Quando resolvido, o caminho de referência deve selecionar um campo cujo valor seja um número inteiro não negativo. Label(Opcional)-
Uma string que identifica exclusivamente um estado
Map. Para cada Execução de mapa, o Step Functions adiciona o rótulo ao ARN da Execução de mapa. Veja a seguir um exemplo de um ARN de Execução de mapa com um rótulo personalizado chamadodemoLabel:arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0bSe você não especificar um rótulo, o Step Functions gerará automaticamente um rótulo exclusivo.
nota
Os rótulos não podem ter mais de 40 caracteres, devem ser exclusivos em uma definição de máquina de estado e não podem conter nenhum dos caracteres a seguir.
-
Espaço em branco
-
Caracteres curinga (
? *) -
Caracteres de colchete (
< > { } [ ]) -
Caracteres especiais (
: ; , \ | ^ ~ $ # % & ` ") -
caracteres de controle (
\\u0000-\\u001fou\\u007f-\\u009f).
O Step Functions aceita nomes de máquina de estado, execuções, atividades e rótulos que contenham caracteres não ASCII. Como esses caracteres impedirão que a Amazon CloudWatch registre dados, recomendamos usar somente caracteres ASCII para que você possa acompanhar as métricas do Step Functions.
-
ResultWriter(Opcional)-
Especifica o local do Amazon S3 em que o Step Functions grava todos os resultados da execução do fluxo de trabalho secundário.
O Step Functions consolida todos os dados da execução de um fluxo de trabalho secundário, como a entrada e saída de execução, ARN e status da execução. Em seguida, ele exporta as execuções com o mesmo status para seus respectivos arquivos na localização especificada do Amazon S3. Para obter mais informações, consulte ResultWriter (Mapa).
Se você não exportar os resultados do estado
Map, ele retornará uma matriz de todos os resultados da execução do fluxo de trabalho secundário. Por exemplo:[1, 2, 3, 4, 5] ResultPath(opcional, somente JSONPath)-
Especifica onde colocar a saída das iterações na entrada. A entrada é então filtrada conforme especificado pelo campo OutputPath (se presente), antes de ser transmitida como a saída do estado. Para obter mais informações, consulte Processamento de entrada e saída.
ResultSelector(Opcional)-
Transmitir um conjunto de pares de valores-chave, em que os valores são estáticos ou selecionados a partir do resultado. Para obter mais informações, consulte ResultSelector.
dica
Se o estado Paralelo ou Mapa usado nas máquinas de estado retornar uma matriz de matrizes, você poderá transformá-las em uma matriz nivelada com o campo ResultSelector. Para obter mais informações, consulte Nivelamento de uma matriz de matrizes.
Retry(Opcional)-
Uma matriz de objetos, chamados Retriers, que definem uma política de novas tentativas. Uma execução usará a política de novas tentativas caso o estado encontre erros de runtime. Para obter mais informações, consulte Exemplos de máquina de estado usando repetição e captura.
nota
Se você definir Retriers para o estado Mapa Distribuído, a política de novas tentativas se aplicará a todas as execuções do fluxo de trabalho secundário iniciadas pelo estado
Map. Por exemplo, imagine que o estadoMapiniciou três execuções de fluxo de trabalho secundário, das quais uma falha. Quando a falha ocorre, a execução usa o campoRetry, se definido, para o estadoMap. A política de repetição se aplica a todas as execuções do fluxo de trabalho secundário e não apenas à execução com falha. Se uma ou mais execuções de fluxo de trabalho secundário falharem, o mesmo ocorrerá com a Execução de mapa.Ao repetir um estado
Map, uma nova Execução de mapa é criada. Catch(Opcional)-
Uma matriz de objetos, chamados Catchers, que definem um estado de fallback. O Step Functions usará os Catchers definidos em
Catchse o estado encontrar erros de runtime. Quando ocorre um erro, a execução usa primeiro todos os retriers definidos emRetry. Se a política de novas tentativas não estiver definida ou estiver esgotada, a execução usará seus Catchers, se definidos. Para obter mais informações, consulte Estados de fallback. Output(opcional, somente JSONata)-
Usado para especificar e transformar a saída do estado. Quando especificado, o valor substitui o padrão de saída de estado.
O campo de saída aceita qualquer valor JSON (objeto, matriz, string, número, booleano, nulo). Qualquer valor de string, incluindo aqueles em objetos ou matrizes, será avaliado como JSONata se estiver entre caracteres {% %}.
A saída também aceita uma expressão JSONata direta, por exemplo: “Output”: “{% jsonata expression %}”
Para obter mais informações, consulte Transformar dados com JSONata no Step Functions.
-
Assign(Opcional) -
Usado para armazenar variáveis. O
Assigncampo aceita um objeto JSON com key/value pares que definem nomes de variáveis e seus valores atribuídos. Qualquer valor de string, incluindo aqueles em objetos ou matrizes, será avaliado como JSONata se estiver entre caracteres{% %}Para obter mais informações, consulte Transmitir dados entre estados com variáveis.
Definir limites de falha para estados de mapa distribuído no Step Functions
Ao orquestrar cargas de trabalho paralelas em grande escala, você também pode definir um limite de falha tolerado. Esse valor permite especificar o número máximo ou a porcentagem de itens com falha como um limite de falha para uma Execução de mapa. Dependendo do valor que você especificar, a Execução de mapa falhará automaticamente se exceder o limite. Se você especificar os dois valores, o fluxo de trabalho falhará quando exceder qualquer um dos valores.
Especificar um limite ajuda você a falhar em um número específico de itens antes que toda a execução do mapa falhe. O Step Functions retorna um erro de States.ExceedToleratedFailureThreshold quando a Execução de mapa falha porque o limite especificado foi excedido.
nota
O Step Functions pode continuar executando fluxos de trabalho secundários em uma Execução de mapa mesmo depois que o limite de falha tolerado for excedido, mas antes que a Execução de mapa falhe.
Para especificar o valor do limite no Workflow Studio, selecione Definir um limite de falha tolerado em Configuração adicional, no campo Configurações de tempo de execução.
- Porcentagem de falha tolerada
-
Define a porcentagem de itens com falha a serem tolerados em uma Execução de mapa. A Execução de mapa falhará se esse valor for excedido. O Step Functions calcula a porcentagem de itens com falha como resultado do número total de itens com falha ou com tempo limite esgotado dividido pelo número total de itens. Você deve especificar um valor entre zero e cem. O valor percentual padrão é zero, o que significa que o fluxo de trabalho falhará se qualquer uma das execuções de fluxo de trabalho secundárias falhar ou atingir o tempo limite. Se você especificar a porcentagem como cem, o fluxo de trabalho não falhará, mesmo que todas as execuções de fluxo de trabalho secundárias falhem.
Como alternativa, você pode especificar a porcentagem como um caminho de referência para um par de chave-valor existente na entrada do estado Mapa Distribuído. Esse caminho deve ser um número inteiro positivo entre 0 e cem no runtime. O caminho de referência é especificado no subcampo
ToleratedFailurePercentagePath.Por exemplo, dada a seguinte entrada:
{"percentage":15}Você pode especificar a porcentagem usando um caminho de referência para essa entrada da seguinte forma:
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }Importante
Você pode especificar
ToleratedFailurePercentageouToleratedFailurePercentagePath, mas não ambos, na definição do estado Mapa Distribuído. - Contagem de falhas toleradas
-
Define o número de itens com falha a serem tolerados. A Execução de mapa falhará se esse valor for excedido.
Como alternativa, você pode especificar a contagem como um caminho de referência para um par de chave-valor existente na entrada do estado Mapa Distribuído. Esse caminho deve ser um inteiro positivo no runtime. O caminho de referência é especificado no subcampo
ToleratedFailureCountPath.Por exemplo, dada a seguinte entrada:
{"count":10}Você pode especificar o número usando um caminho de referência para essa entrada da seguinte forma:
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }Importante
Você pode especificar
ToleratedFailureCountouToleratedFailureCountPath, mas não ambos, na definição do estado Mapa Distribuído.
Saiba mais sobre mapas distribuídos.
Para continuar aprendendo mais sobre o estado Mapa Distribuído, consulte os seguintes recursos:
-
Processamento de entrada e saída
Para configurar a entrada que um estado Mapa Distribuído recebe e a saída que ele gera, o Step Functions fornece os seguintes campos:
Além desses campos, o Step Functions também fornece a capacidade de definir um limite de falha tolerado para Mapa distribuído. Esse valor permite especificar o número máximo ou a porcentagem de itens com falha como um limite de falha para uma Execução de mapa. Para ver mais informações sobre como configurar o limite de falhas toleradas, consulte Definir limites de falha para estados de mapa distribuído no Step Functions
-
Usar o estado Mapa Distribuído
Consulte os seguintes tutoriais e exemplos de projetos para começar a usar o estado Mapa Distribuído.
-
Examine a execução do estado Mapa Distribuído
O console do Step Functions tem uma página Detalhes da Execução de mapa que exibe todas as informações relacionadas à execução de um estado Mapa distribuído. Para ver informações sobre como examinar as informações exibidas nesta página, consulte Visualizar execuções de mapa.
