Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Arquitetura
O Amazon Timestream para Live Analytics foi projetado desde o início para coletar, armazenar e processar dados de séries temporais em grande escala. Sua arquitetura de tecnologia sem servidor oferece suporte a sistemas totalmente desacoplados de ingestão de dados, armazenamento e processamento de consultas que podem ser escalados de forma independente. Esse design simplifica cada subsistema, facilitando a obtenção de confiabilidade inabalável, eliminando gargalos de escala e reduzindo as chances de falhas correlacionadas do sistema. Cada um desses fatores se torna mais importante à medida que o sistema escala.
Tópicos
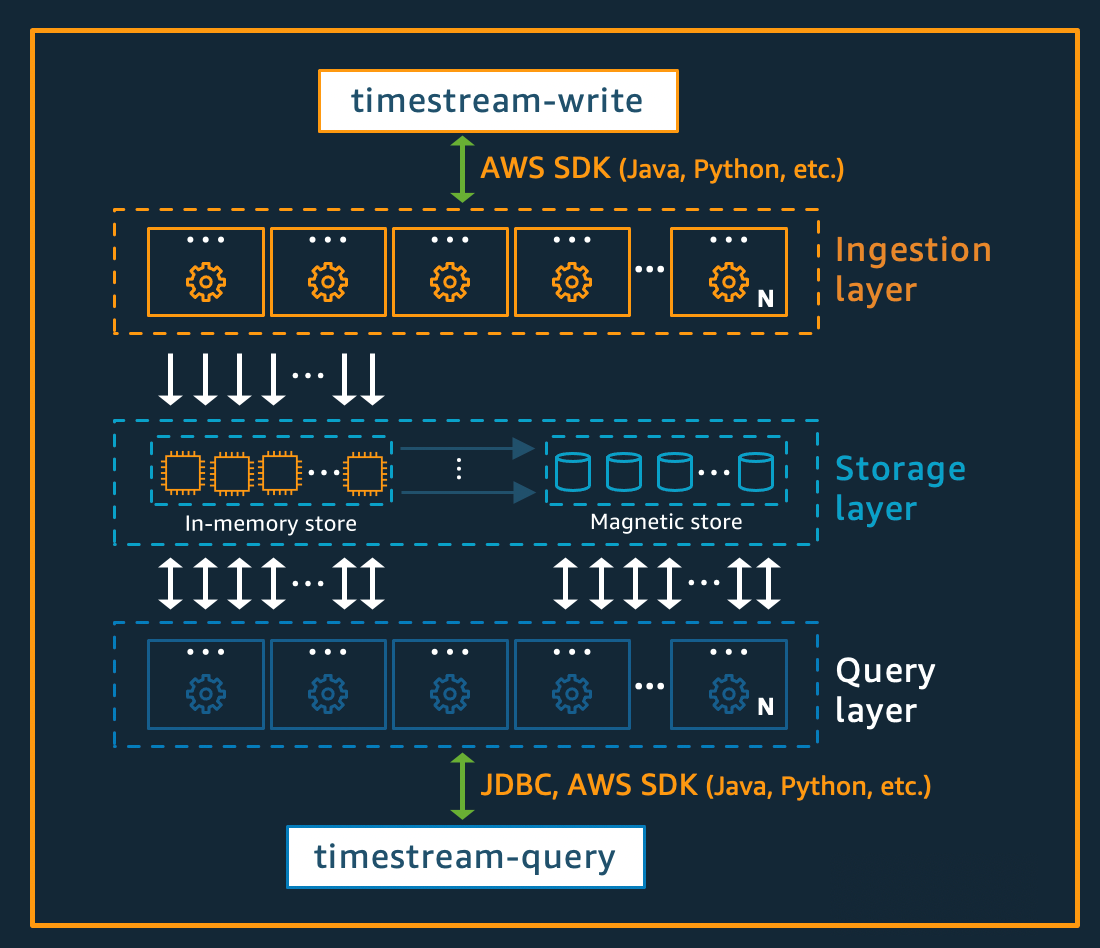
Arquitetura de gravação
Ao gravar dados de séries temporais, o Amazon Timestream para Live Analytics encaminha gravações para uma tabela, partição, para uma instância de armazenamento na memória com tolerância a falhas que processa gravações de dados de alto throughput. O armazenamento de memória, por sua vez, obtém durabilidade em um sistema de armazenamento separado que replica os dados em três zonas de disponibilidade ()AZs. A replicação é baseada em quórum, de forma que a perda de nós, ou de uma AZ inteira, não interrompe a disponibilidade de gravação. Quase em tempo real, outros nós de armazenamento na memória são sincronizados com os dados para atender às consultas. Os nós de réplica do leitor AZs também se estendem, para garantir a alta disponibilidade de leitura.
O Timestream para Live Analytics suporta a gravação de dados diretamente no armazenamento magnético, para aplicativos que geram menor throughput de dados de chegada tardia. Dados de chegada tardia são dados com um registro de data e hora anterior ao atual. Semelhante às gravações de alto rendimento no armazenamento de memória, os dados gravados no armazenamento magnético são replicados em três AZs e a replicação é baseada em quórum.
Independentemente de os dados serem gravados na memória ou no armazenamento magnético, o Timestream para Live Analytics indexa e particiona automaticamente os dados antes de gravá-los no armazenamento. Uma única tabela Timestream para Live Analytics pode ter centenas, milhares ou até milhões de partições. Partições individuais não se comunicam diretamente entre si e não compartilham nenhum dado (arquitetura sem compartilhamento). Em vez disso, o particionamento de uma tabela é rastreado por meio de um serviço de indexação e rastreamento de partições altamente disponível. Isso fornece outra separação de preocupações projetadas especificamente para minimizar o efeito das falhas no sistema e tornar as falhas correlacionadas muito menos prováveis.
Arquitetura de armazenamento
Quando os dados são armazenados no Timestream para Live Analytics, os dados são organizados em ordem temporal e ao longo do tempo, com base nos atributos de contexto gravados com os dados. Ter um esquema de particionamento que divide o “espaço” além do tempo é importante para escalar massivamente um sistema de séries temporais. Isso ocorre porque a maioria dos dados de séries temporais é gravado na hora atual ou perto dela. Como resultado, o particionamento apenas por tempo não faz um bom trabalho ao distribuir o tráfego de gravação ou permitir a remoção eficaz dos dados no momento da consulta. Isso é importante para o processamento de séries temporais em escala extrema e permitiu que o Timestream para Live Analytics escalasse ordens de magnitude mais altas do que os outros sistemas líderes do mercado atualmente com tecnologia sem servidor. As partições resultantes são chamadas de “blocos” porque representam divisões de um espaço bidimensional (projetadas para serem de tamanho semelhante). As tabelas do Timestream para Live Analytics começam como uma única partição (bloco) e depois são divididas na dimensão espacial conforme o throughput exigido. Quando os blocos atingem um determinado tamanho, eles se dividem na dimensão do tempo para obter um melhor paralelismo de leitura à medida que o tamanho dos dados aumenta.
O Timestream para Live Analytics foi projetado para gerenciar automaticamente o ciclo de vida dos dados de séries temporais. O Timestream para Live Analytics oferece dois armazenamentos de dados: um armazenamento na memória e um armazenamento magnético econômico. Ele também oferece suporte à configuração de políticas em nível de tabela para transferir dados automaticamente entre armazenamentos. As gravações de dados de alto throughput recebidas chegam ao armazenamento na memória, onde os dados são otimizados para gravações, bem como as leituras realizadas no horário atual para alimentar consultas do tipo painel e alertas. Quando o prazo principal para as necessidades de gravação, alertas e painéis tiver passado, permitindo que os dados fluam automaticamente do armazenamento na memória para o armazenamento magnético para otimizar os custos. O Timestream para Live Analytics permite definir uma política de retenção de dados no armazenamento na memória para essa finalidade. As gravações de dados para dados de chegada tardia são gravadas diretamente no armazenamento magnético.
Quando os dados estão disponíveis no armazenamento magnético (devido à expiração do período de retenção do armazenamento na memória ou devido a gravações diretas no armazenamento magnético), eles são reorganizados em um formato altamente otimizado para leituras de dados de grande volume. O armazenamento magnético também tem uma política de retenção de dados que pode ser configurada se houver um limite de tempo em que os dados percam sua utilidade. Quando os dados excedem o intervalo de tempo definido para a política de retenção do armazenamento magnético, eles são removidos automaticamente. Portanto, com o Timestream para Live Analytics, além da necessidade de algumas configurações, o gerenciamento do ciclo de vida dos dados ocorre perfeitamente nos bastidores.
Arquitetura de consultas
As consultas do Timestream para Live Analytics são expressas em uma gramática SQL que tem extensões para suporte específico de séries temporais (tipos e funções de dados específicos de séries temporais), portanto, a curva de aprendizado é fácil para desenvolvedores que já estão familiarizados com SQL. Em seguida, as consultas são processadas por um mecanismo de consulta distribuído e adaptável que usa metadados do serviço de rastreamento e indexação de blocos para acessar e combinar facilmente os dados entre os armazenamentos de dados no momento em que a consulta é emitida. Isso proporciona uma experiência que ressoa bem com os clientes, pois reúne muitas das complexidades de Rube Goldberg em uma abstração de banco de dados simples e familiar.
As consultas são executadas por uma frota dedicada de trabalhadores, em que o número de trabalhadores chamados para executar uma determinada consulta é determinado pela complexidade da consulta e pelo tamanho dos dados. O desempenho de consultas complexas em grandes conjuntos de dados é obtido por meio de um paralelismo massivo, tanto na frota de runtime, de consultas quanto nas frotas de armazenamento do sistema. A capacidade de analisar grandes quantidades de dados com rapidez e eficiência é um dos maiores pontos fortes do Timestream para Live Analytics. Uma única consulta que executa mais de terabytes ou mesmo petabytes de dados pode ter milhares de máquinas trabalhando nela ao mesmo tempo.
Arquitetura celular
Para garantir que o Timestream para Live Analytics possa oferecer uma escala praticamente infinita para seus aplicativos e, ao mesmo tempo, garantir 99,99% de disponibilidade, o sistema também foi projetado usando uma arquitetura celular. Em vez de escalar o sistema como um todo, o Timestream para Live Analytics segmenta em várias cópias menores de si mesmo, chamadas de células. Isso permite que as células sejam testadas em grande escala e evita que um problema no sistema em uma célula afete a atividade em qualquer outra célula em uma determinada região. Embora o Timestream para Live Analytics tenha sido projetado para oferecer suporte a várias células por região, considere o seguinte cenário fictício, no qual há 2 células em uma região.
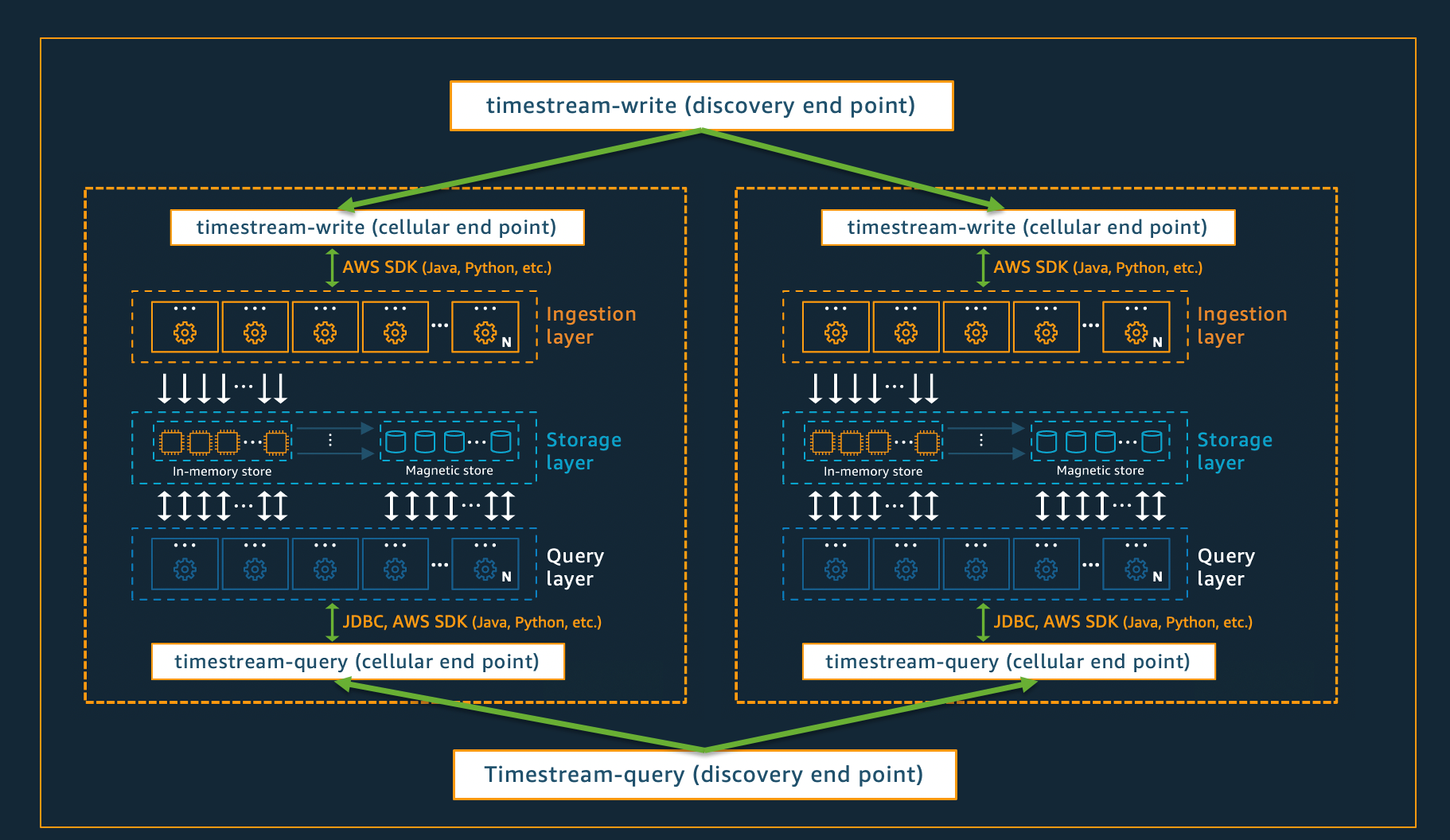
No cenário descrito acima, a ingestão de dados e as solicitações de consulta são processadas primeiro pelo endpoint de descoberta para ingestão e consulta de dados, respectivamente. Em seguida, o endpoint de descoberta identifica a célula que contém os dados do cliente e direciona a solicitação para o endpoint de ingestão ou consulta apropriado para essa célula. Ao usar o SDKs, essas tarefas de gerenciamento de endpoints são tratadas de forma transparente para você.
nota
Ao usar os endpoints da VPC com o Timestream para Live Analytics ou acessar diretamente as operações da API REST para o Timestream para Live Analytics, você precisará interagir diretamente com os endpoints celulares. Para obter orientação sobre como fazer isso, consulte Endpoints da VPC para obter instruções sobre como configurar os endpoints da VPC e Padrão de descoberta de Endpoint para obter instruções sobre a invocação direta das operações da API REST.
