Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
O que é Timestream para InfluxDB?
O Amazon Timestream for InfluxDB é um mecanismo gerenciado de banco de dados de séries temporais que facilita que desenvolvedores DevOps e equipes de aplicativos executem bancos de dados do InfluxDB para aplicativos de séries temporais AWS em tempo real usando código aberto. APIs Com o Amazon Timestream para InfluxDB é fácil configurar, operar e escalar workloads de séries temporais que podem responder a consultas com tempo de resposta de consulta de um dígito de milissegundos.
O Amazon Timestream para InfluxDB oferece acesso aos recursos da conhecida versão de código aberto do InfluxDB em sua ramificação 2.x. Isso significa que o código, os aplicativos e as ferramentas que você já usa hoje com seus bancos de dados de código aberto do InfluxDB existentes devem funcionar perfeitamente com o Amazon Timestream para InfluxDB. O Amazon Timestream para InfluxDB pode fazer backup automático do seu banco de dados e manter seu software de banco de dados atualizado com a versão mais recente. Além disso, o Amazon Timestream para InfluxDB facilita o uso da replicação para aprimorar a disponibilidade do banco de dados e melhorar a durabilidade dos dados. Como acontece com todos os AWS serviços, não são necessários investimentos iniciais e você paga apenas pelos recursos que usa.
Instâncias de banco de dados
Uma instância de banco de dados é um ambiente de banco de dados isolado em execução na nuvem. É o componente básico do Amazon Timestream para InfluxDB. Uma instância de banco de dados pode conter vários bancos de dados criados pelo usuário (ou organizações e buckets, no caso de bancos de dados InfluxDb 2.x) e pode ser acessada usando as mesmas ferramentas e aplicativos de cliente que você pode usar para acessar uma instância autônoma autogerenciada do InfluxDB. Instâncias de banco de dados são simples de serem criadas e modificadas com as ferramentas da linha de comando da AWS , as operações da API do Amazon Timestream InfluxDB ou o AWS Management Console.
nota
O Amazon Timestream para InfluxDB oferece suporte ao acesso a bancos de dados usando as operações da API Influx e a interface do usuário do Influx. O Amazon Timestream para InfluxDB não permite o acesso direto ao host.
Você pode ter até 40 instâncias do Amazon Timestream para InfluxDB.
Cada instância de banco de dados tem um ID de instância de banco de dados. Esse nome gerado pelo serviço identifica de forma exclusiva a instância de banco de dados ao interagir com os comandos da API e da CLI do Amazon Timestream para InfluxDB. AWS O ID da instância de banco de dados é exclusivo para esse cliente em uma AWS região.
O ID de instância de banco de dados é usado como parte do nome do host DNS alocado à instância pelo Timestream para InfluxDB. Por exemplo, se você especificar influxdb1 como o nome de instância de banco de dados e o serviço gerar um ID de instância c5vasdqn0b, o Timestream alocará automaticamente um endpoint de DNS para a instância. Um exemplo de endpoint é c5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws, onde c5vasdqn0b é o ID da instância. Todas as instâncias criadas antes de 12/09/2024 manterão a estrutura antiga com um endpoint semelhante a: influxdb1-3ksj4dla5nfjhi.us-east-1.timestream-influxdb.amazonaws.com onde influxdb1 é seu nome de instância.
No endpoint de exemploc5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws, a string 3ksj4dla5nfjhi é um identificador de conta exclusivo gerado por AWS. O identificador 3ksj4dla5nfjhi no exemplo não muda para a conta especificada em uma determinada região. Assim, todas as suas instâncias de banco de dados criadas por essa conta compartilham o mesmo identificador fixo na Região. Considere as seguintes características do identificador fixo:
-
Atualmente, o Timestream para InfluxDB não oferece suporte à renomeação de instâncias de banco de dados.
-
Para todas as instâncias criadas após 12/09/2024, se você excluir e recriar sua instância de banco de dados com o mesmo nome de instância de banco de dados, o endpoint mudará, pois um novo ID de instância será atribuído à instância. A instância criada antes da data mencionada acima será atribuída ao mesmo endpoint com base no nome da instância.
-
Se você usar a mesma conta para criar uma instância de banco de dados em uma região diferente, o identificador gerado internamente será diferente porque a região é diferente, como em
zxlasoonhvd.4a3j5du5ks7md2.timestream-influxdb.us-east-1.on.aws.
Cada instância de banco de dados oferece suporte a apenas um Timestream para InfluxDB.
Ao criar uma instância de banco de dados, o InfluxDB exige que um nome de organização seja especificado. Uma instância de banco de dados pode hospedar várias organizações e vários buckets associados a cada organização.
O Amazon Timestream para InfluxDB permite que você crie uma conta de usuário principal e uma senha para sua instância de banco de dados como parte do processo de criação. Este usuário principal tem permissões para criar organizações, buckets e realizar operações de leitura, gravação, exclusão e acréscimo em seus dados. Você também poderá acessar o InfluxUI e recuperar seu token de operador em seu primeiro login. A partir daí, você também poderá gerenciar todos os seus tokens de acesso. É necessário definir a senha de usuário principal ao criar uma instância de banco de dados. Essa senha pode ser alterada a qualquer momento usando a API Influx, Influx CLI ou InfluxUI.
Classes da instância de banco de dados
A classe de instância de banco de dados determina a capacidade de computação e de memória de uma instância de banco de dados do Amazon Timestream para InfluxDB. A classe de instância de banco de dados da qual você precisa depende dos requisitos de memória e potência de processamento.
Uma classe de instância de banco de dados consiste no tipo de classe e no tamanho de instância de banco de dados. Por exemplo, db.influx é um tipo de classe de instância de banco de dados otimizado para memória, adequado aos requisitos de memória de alto desempenho relacionados à execução InfluxDb de cargas de trabalho. No tipo de classe de instância db.influx, db.influx.2xlarge é uma classe de instância de banco de dados. O tamanho dessa classe é 2xlarge.
Para obter mais informações sobre a definição de preço da classe de instância, consulte Definição de Preços do Amazon Timestream para InfluxDB
Tipos de classe de instância de banco de dados
O Amazon Timestream para InfluxDB é compatível com as classes de instância de banco de dados para o seguinte caso de uso otimizado para casos de uso do InfluxDB.
-
db.influx: essas classes de instância são ideais para executar workloads com uso intensivo de memória em bancos de dados de código aberto InfluxDB
Especificações de hardware para classes de instância de banco de dados
A terminologia a seguir descreve as especificações de hardware para instâncias de cluster de banco de dados:
-
vCPU
O número de unidades de processamento central virtual (CPUs). Uma CPU virtual é uma unidade de capacidade que pode ser usada para comparar classes de instância de banco de dados.
-
Memória (GiB)
A memória RAM, em gibibytes, alocada à instância de banco de dados. Geralmente, há uma proporção consistente entre a memória e a vCPU. Por exemplo, considere a classe de instância db.influx, que possui uma proporção entre memória e vCPU semelhante à da classe de instância EC2 r7g.
-
Otimizado para o Influx
A instância de banco de dados usa uma pilha de configuração otimizada e fornece capacidade adicional dedicada para I/O. This optimization provides the best performance by minimizing contention between I/O e outros tráfegos da sua instância.
-
Largura de banda da rede
A velocidade da rede em relação a outras classes de instância de banco de dados. Na tabela a seguir, é possível encontrar detalhes de hardware sobre as classes de instância de banco de dados do Amazon Timestream para InfluxDB.
| Classe de instância | vCPU | Memória (GiB) | Tipo de armazenamento | Largura de banda da rede(Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | Influx IOPS incluído | 10 |
| db.influx.large | 2 | 16 | Influx IOPS incluído | 10 |
| db.influx.xlarge | 4 | 32 | Influx IOPS incluído | 10 |
| db.influx.2xlarge | 8 | 64 | Influx IOPS incluído | 10 |
| db.influx.4xlarge | 16 | 128 | Influx IOPS incluído | 10 |
| db.influx.8xlarge | 32 | 256 | Influx IOPS incluído | 12 |
| db.influx.12xlarge | 48 | 384 | Influx IOPS incluído | 20 |
| db.influx.16xlarge | 64 | 512 | Influx IOPS incluído | 25 |
| db.influx.24xlarge | 96 | 768 | Influx IOPS incluído | 40 |
Armazenamento da instância do InfluxDB
As instâncias de banco de dados do Amazon Timestream para InfluxDB usam volumes incluídos do Influx IOPS para bancos de dados e armazenamento de logs.
Em alguns casos, a workload do banco de dados pode não conseguir alcançar 100% das IOPS provisionadas. Para ter mais informações, consulte Fatores que afetam a performance do armazenamento. Para obter mais informações sobre a definição de preço de armazenamento do Timestream para InfluxDB, consulte Definição de preços do Amazon Timestream.
Tipos de armazenamento do Amazon Timestream para InfluxDB
O Amazon Timestream para InfluxDB fornece suporte para um tipo de armazenamento, o Influx IOPS Included. É possível criar instâncias para o Timestream para InfluxDB com até 16 tebibytes (TiB) de armazenamento.
Aqui está uma breve descrição do tipo de armazenamento disponível:
-
Armazenamento incluído no Influx IO: o desempenho do armazenamento é a combinação de I/O operações por segundo (IOPS) e a rapidez com que o volume de armazenamento pode realizar leituras e gravações (taxa de transferência de armazenamento). Nos volumes de armazenamento incluídos no Influx IOPS, o Amazon Timestream para InfluxDB fornece 3 níveis de armazenamento que vêm pré-configurados com IOPS e throughput ideais para diferentes tipos de workloads.
Dimensionamento de instância do InfluxDB
A configuração ideal de uma instância do Timestream para InfluxDB depende de vários fatores, incluindo taxa de ingestão, tamanhos de lote, cardinalidade de séries temporais, consultas simultâneas e tipos de consulta. Para fornecer recomendações de dimensionamento, vamos considerar um workload exemplar com as seguintes características:
-
Os dados são coletados e gravados por uma frota de agentes do Telegraf que coletam sistema, CPU, memória, disco, I/O etc. de um data center.
Cada solicitação de gravação contém 5000 linhas.
-
As consultas executadas no sistema são categorizadas como consultas de “complexidade moderada”, exibindo as seguintes características:
-
Elas têm várias funções e uma ou duas expressões regulares
-
Podem incluir cláusulas agrupadas por cláusulas ou amostrar um intervalo de tempo de várias semanas.
-
Normalmente levam de algumas centenas de milissegundos a alguns milhares de milissegundos para serem executados.
-
A CPU favorece principalmente o desempenho da consulta.
-
| # máximo de séries | Gravações (linhas por segundo) | Leituras (consultas por segundo) | Classe de instância | Tipo de armazenamento |
|---|---|---|---|---|
| <100K | ~50.000 | <10 | db.influx.large | Influx IO incluído 3K |
| <1 MM | ~150.000 | <25 | db.influx.2xlarge | Influx IO incluído 3K |
| <1 MM | ~200.000 | ~25 | db.influx.4xlarge | Influx IO incluído 3K |
| <5 MM | ~250.000 | ~35 | db.influx.4xlarge | Influx IO incluído 12K |
| <10 MM | ~500.000 | ~50 | db.influx.8xlarge | Influx IO incluído 12K |
| ~ 10 MM | <750.000 | <100 | db.influx.12xlarge | Influx IO incluído 12K |
Regiões da AWS e zonas de disponibilidade
Os recursos de computação em nuvem da Amazon são hospedados em vários locais no mundo todo. Esses locais são compostos por Regiões da AWS e. Cada AWS região é uma área geográfica separada. Cada AWS região tem vários locais isolados conhecidos como zonas de disponibilidade.
nota
Para obter informações sobre como encontrar o para uma AWS região, consulte Regiões e zonas no Guia do usuário do Amazon EC2.
O Amazon Timestream para InfluxDB permite que você coloque recursos, como instâncias de banco de dados, e dados em vários locais.
A Amazon opera state-of-the-art data centers de alta disponibilidade. Embora sejam raras, podem ocorrer falhas que afetam a disponibilidade das instâncias de banco de dados que estiverem no mesmo local. Se você hospeda todas as instâncias de banco de dados em um único local afetado por essa falha, nenhuma delas estará disponível.
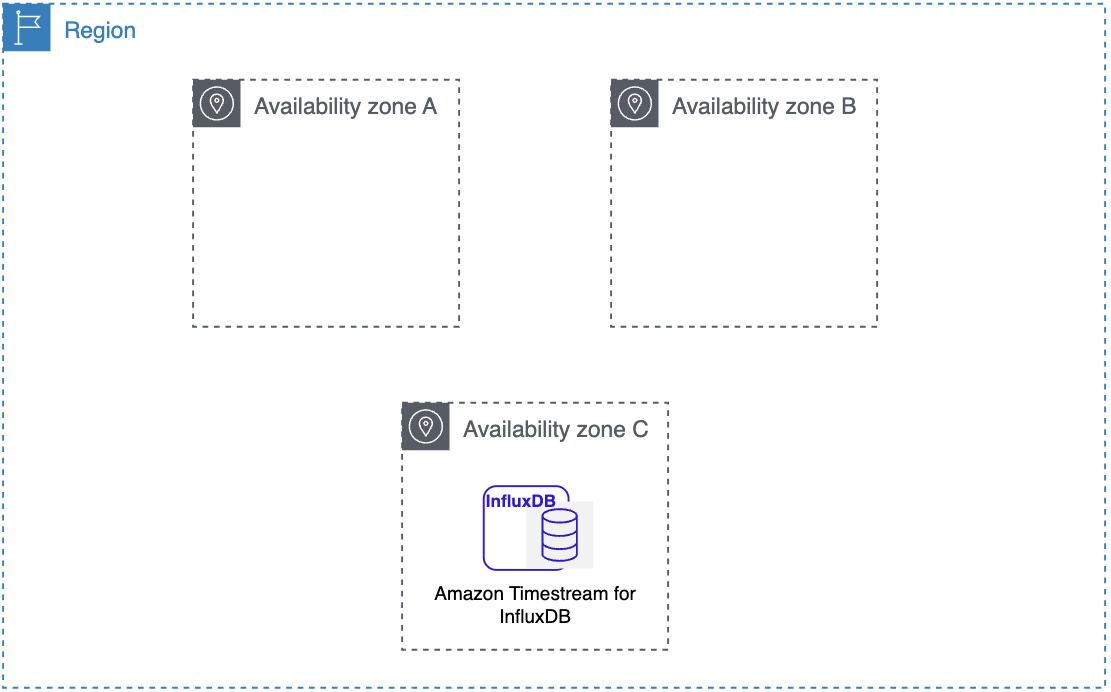
É importante lembrar que cada AWS região é completamente independente. Qualquer atividade do Amazon Timestream para InfluxDB que você iniciar (por exemplo, criar instâncias de banco de dados ou listar instâncias de banco de dados disponíveis) é executada somente em sua região padrão atual. AWS A região da AWS padrão pode ser alterada no console ou definindo a variável de ambiente AWS_DEFAULT_REGION. Ou ele pode ser substituído usando o --region parâmetro com o AWS Command Line Interface ()AWS CLI. Para obter mais informações, consulte Configurando o AWS Command Line Interface, especificamente as seções sobre variáveis de ambiente e opções de linha de comando.
Para criar ou trabalhar com uma instância de bancos de dados do Amazon Timestream para InfluxDB em uma região da AWS específica, use o endpoint de serviço regional correspondente.
AWS Disponibilidade da região
A tabela a seguir mostra as AWS regiões em que o Amazon Timestream for InfluxDB está disponível atualmente e o endpoint para cada região.
| AWS Nome da região | Região | Endpoint | Protocolo |
|---|---|---|---|
| Leste dos EUA (Norte da Virgínia) | us-east-1 | timestream-influxdb.us-east-1.amazonaws.com | HTTPS |
| Leste dos EUA (Ohio) | us-east-2 | timestream-influxdb.us-east-2.amazonaws.com | HTTPS |
| Oeste dos EUA (Oregon) | us-west-2 | timestream-influxdb.us-west-2.amazonaws.com | HTTPS |
| Ásia-Pacífico (Mumbai) | ap-south-1 | timestream-influxdb.ap-south-1.amazonaws.com | HTTPS |
| Ásia-Pacífico (Singapura) | ap-southeast-1 | timestream-influxdb.ap-southeast-1.amazonaws.com | HTTPS |
| Ásia-Pacífico (Sydney) | ap-southeast-2 | timestream-influxdb.ap-southeast-2.amazonaws.com | HTTPS |
| Ásia-Pacífico (Tóquio) | ap-northeast-1 | timestream-influxdb.ap-northeast-1.amazonaws.com | HTTPS |
| Europa (Frankfurt) | eu-central-1 | timestream-influxdb.eu-central-1.amazonaws.com | HTTPS |
| Europa (Irlanda) | eu-west-1 | timestream-influxdb.eu-west-1.amazonaws.com | HTTPS |
| Europa (Estocolmo) | eu-north-1 | timestream-influxdb.eu-north-1.amazonaws.com | HTTPS |
| Canadá (Central) | ca-central-1 | timestream-influxdb.ca-central-1.amazonaws.com | HTTPS |
| Europa (Londres) | eu-west-2 | timestream-influxdb.eu-west-2.amazonaws.com | HTTPS |
| Europa (Paris) | eu-west-3 | timestream-influxdb.eu-west-3.amazonaws.com | HTTPS |
| Ásia-Pacífico (Jacarta) | ap-southeast-3 | timestream-influxdb.ap-southeast-3.amazonaws.com | HTTPS |
| Europa (Milão) | eu-south-1 | timestream-influxdb.eu-south-1.amazonaws.com | HTTPS |
| Europa (Espanha) | eu-south-2 | timestream-influxdb.eu-south-2.amazonaws.com | HTTPS |
| Oriente Médio (Emirados Árabes Unidos) | me-central-1 | timestream-influxdb.me-central-1.amazonaws.com | HTTPS |
| China (Pequim) | cn-north-1 | timestream-influxdb---cn-north-1---on.amazonwebservices.com.rproxy.goskope.com.cn | HTTPS |
| China (Ningxia) | cn-northwest-1 | timestream-influxdb---cn-northwest-1---on.amazonwebservices.com.rproxy.goskope.com.cn | HTTPS |
AWS Design de regiões
Cada AWS região foi projetada para ser isolada das outras AWS regiões. Esse design proporciona o máximo de tolerância a falhas e estabilidade possível.
Ao visualizar seus recursos, você vê somente os recursos vinculados à AWS região que você especificou. Isso ocorre porque AWS as regiões estão isoladas umas das outras e não replicamos automaticamente os recursos entre AWS regiões.
AWS Zonas de disponibilidade
Quando você cria uma instância de banco de dados, o Amazon Timestream para InfluxDB escolhe uma para você de forma aleatória com base na configuração da sub-rede. Uma zona de disponibilidade é representada por um código de AWS região seguido por um identificador de letra (por exemplo,us-east-1a).
Use o comando describe-availability-zones do Amazon EC2 da seguinte maneira para descrever as dentro da região especificada que estão disponíveis para sua conta.
aws ec2 describe-availability-zones --region region-name
Por exemplo, para descrever as da região Leste dos EUA (Norte da Virgínia) (us-east-1) ativado para sua conta, execute o seguinte comando:
aws ec2 describe-availability-zones --regionus-east-1
Você não pode escolher as para as instâncias de banco de dados primária e secundária em uma implantação de banco de dados multi-AZ. Elas são escolhidas para você pelo Amazon Timestream para InfluxDB aleatoriamente. Para ter mais informações sobre implantações Multi-AZ, consulte Configurar e gerenciar uma implantação multi-AZ.
Faturamento de instância de banco de dados para o Amazon Timestream para InfluxDB
As instâncias do Amazon Timestream para InfluxDB são faturadas com base nos seguintes componentes:
-
Horas de instância de banco de dados (por hora): com base na classe da instância de banco de dados, por exemplo: db.influx.large. A definição de preço está listada em uma base por hora, mas é calculada em segundos e mostra o tempo no formato decimal. O uso do Amazon Timestream para InfluxDB é faturado em incrementos de um segundo, com um mínimo de dez minutos. Para obter mais informações, consulte Classes da instância de banco de dadosClasses de instância de banco de dados.
-
Armazenamento (por GiB por mês): a capacidade de armazenamento provisionado para a sua instância de banco de dados. Para obter mais informações, consulte Armazenamento da instância do InfluxDB.
-
Transferência de dados (por GB) — Transferência de dados para dentro e para fora da sua instância de banco de dados de ou para a Internet e outras AWS regiões.
Para obter informações sobre preços do Amazon Timestream para InfluxDB, consulte a página de preços do Amazon Timestream para InfluxDB
Configuração do Amazon Timestream para InfluxDB
Antes de usar o Amazon Timestream para InfluxDB pela primeira vez, conclua as seguintes tarefas:
Se você já tem uma AWS conta, conheça seus requisitos do Amazon Timestream para InfluxDB e prefira usar os padrões para IAM e Amazon VPC. Conceitos básicos do Timestream para InfluxDB
Cadastre-se para uma AWS conta
Se você não tiver uma AWS conta, conclua as etapas a seguir para criar uma.
Para se cadastrar em uma conta da AWS
-
Vá para a página de login da AWS
. -
Escolha Criar nova conta e siga as instruções.
nota
Parte do procedimento de inscrição envolve receber uma chamada telefônica e inserir um código de verificação no teclado do telefone.
Quando você se inscreve AWS em uma conta, um usuário raiz da AWS conta é criado. O usuário root tem acesso a todos os AWS serviços e recursos da conta. Como prática recomendada de segurança, atribua acesso administrativo a um usuário administrativo e use somente o usuário raiz para realizar as tarefas que exigem acesso do usuário raiz.
AWS envia um e-mail de confirmação após a conclusão do processo de inscrição. A qualquer momento, você pode visualizar a atividade atual da sua conta e gerenciar sua conta acessando https://aws.amazon.com/e
Gerenciamento de usuários
Criar um usuário administrativo
Criar um usuário administrador
Depois de se inscrever AWS em uma conta, crie um usuário administrativo para não usar o usuário root nas tarefas diárias.
Proteja o usuário root da sua AWS conta
Faça login AWS Management Console como proprietário da conta escolhendo Usuário raiz e inserindo o endereço de e-mail AWS da sua conta. Na próxima página, insira a senha. Para obter ajuda ao fazer login usando o usuário-raiz, consulte Fazer login como usuário-raiz no Guia do usuário da AWS
Habilite a autenticação multifator (MFA) para o usuário-raiz. Para obter instruções, consulte Habilitar um dispositivo virtual de MFA para o usuário raiz AWS da sua conta (console) no Guia do usuário do IAM.
Conceder acesso programático
Os usuários precisam de acesso programático se quiserem interagir com pessoas AWS fora do AWS Management Console. A forma de conceder acesso programático depende do tipo de usuário que está acessando a AWS.
Para conceder acesso programático aos usuários, selecione uma das seguintes opções:
| Qual usuário precisa de acesso programático? | Para | Por |
|---|---|---|
| Identidade da força de trabalho (Usuários gerenciados no IAM Identity Center) | Use credenciais temporárias para assinar solicitações programáticas na AWS CLI, ou. AWS SDKs AWS APIs |
Siga as instruções da interface que deseja utilizar. Para saber mais AWS CLI, consulte Como configurar a autenticação do IAM Identity Center com o AWS CLI no Guia do AWS Command Line Interface usuário. Para AWS SDKs, ferramentas e AWS APIs, consulte Como usar o IAM Identity Center para autenticar o AWS SDK e as ferramentas no Guia de referência de ferramentas AWS SDKs e ferramentas. |
| IAM | Use credenciais temporárias para assinar solicitações programáticas para a AWS CLI, e. SDKs APIs | Siga as instruções em Usar credenciais temporárias com AWS recursos no Guia do AWS Identity and Access Management usuário. |
| IAM | (Não recomendado) Use credenciais de longo prazo para assinar solicitações programáticas para a AWS CLI, e. SDKs APIs |
Siga as instruções da interface que deseja utilizar. Para o AWS CLI, consulte Autenticação usando credenciais de usuário do IAM AWS CLI no Guia do AWS Command Line Interface usuário. Para ferramentas AWS SDKs e ferramentas, consulte Uso de credenciais de longo prazo para autenticação AWS SDKs e ferramentas no Guia de referência de ferramentas AWS SDKs e ferramentas. Para AWS APIs isso, consulte Gerenciamento de chaves de acesso para usuários do IAM no Guia AWS Identity and Access Management do usuário. |
Determinar requisitos
O componente básico do Amazon Timestream para InfluxDB é a instância do banco de dados. Em uma instância de banco de dados, você cria seus buckets. Uma instância de banco de dados fornece um endereço de rede chamado de endpoint. Seus aplicativos usam o endpoint para se conectar à instância de banco de dados. Você também acessará seu InfluxUI usando esse mesmo endpoint do seu navegador. Ao criar a instância de banco de dados, você especifica detalhes como armazenamento, memória, mecanismo e versão de banco de dados, configuração de rede e segurança. Você controla o acesso de rede a uma instância de banco de dados por meio de um grupo de segurança.
Antes de criar uma instância de banco de dados e um grupo de segurança, você precisa conhecer as necessidades de sua instância de banco de dados e de sua rede. Veja aqui alguns fatores importantes a considerar:
-
Requisitos de recurso: quais são os requisitos de memória e processador de seu aplicativo ou serviço? Você usa essas configurações para ajudá-lo a determinar que classe de instância de banco de dados deve usar. Para conhecer especificações sobre as classes de instâncias de bancos de dados, consulte Classes de instância de banco de dados.
-
VPC e grupo de segurança: é mais provável que sua instância de banco de dados esteja uma nuvem privada virtual (VPC). Para se conectar à sua instância de banco de dados, você precisa definir regras de grupo de segurança. Essas regras são definidas diferentemente, dependendo do tipo de VPC que você usa e como a usa. Por exemplo, você pode usar: uma VPC padrão ou uma VPC definida pelo usuário.
A lista a seguir descreve as regras para cada opção da VPC:
-
VPC padrão — Se sua AWS conta tem uma VPC padrão na região atual AWS , essa VPC está configurada para oferecer suporte a instâncias de banco de dados. Se você especificar a VPC padrão ao criar a instância de banco de dados, você deve criar um grupo de segurança da VPC que autorize conexões do aplicativo ou serviço para a instância de banco de dados do Amazon Timestream para InfluxDB. Use a opção Grupo de segurança no console da VPC ou na AWS CLI para criar grupos de segurança da VPC. Para mais informações, consulte Etapa 3: criar um grupo de segurança da VPC.
-
-
VPC definida pelo usuário: se quiser especificar uma VPC definida pelo usuário ao criar uma instância de banco de dados, esteja ciente do seguinte:
-
Certifique-se de criar um grupo de segurança da VPC que autorize conexões da aplicação ou serviço para a instância de banco de dados do Amazon Timestream para InfluxDB. Use a opção Grupo de segurança no console da VPC ou na AWS CLI para criar grupos de segurança da VPC. Para informações, consulte Etapa 3: criar um grupo de segurança da VPC.
-
A VPC deve atender a certos requisitos para hospedar instâncias de bancos de dados, como ter pelo menos duas sub-redes, cada uma em uma zona de disponibilidade separada. Para informações, consulte Amazon VPC e Amazon Timestream para InfluxDB.
-
-
Alta disponibilidade: você precisa de suporte a failover? No Amazon Timestream para InfluxDB, uma implantação multi-AZ cria uma instância de banco de dados primária e uma instância de banco de dados em espera (secundária) em outra zona de disponibilidade para suporte de failover. Para manter a alta disponibilidade, recomendamos as implantações multi-AZ para cargas de trabalho de produção. Para fins de desenvolvimento e teste, você pode usar uma implantação que não seja multi-AZ. Para obter mais informações, consulte Implantações de instâncias de banco de dados Multi-AZ.
-
Políticas do IAM — Sua AWS conta tem políticas que concedem as permissões necessárias para realizar operações do Amazon Timestream para o InfluxDB? Se você estiver se conectando AWS usando credenciais do IAM, sua conta do IAM deve ter políticas do IAM que concedam as permissões necessárias para realizar as operações do plano de controle do Amazon Timestream para o InfluxDB. Para obter mais informações, consulte Gerenciamento de identidade e acesso para o Amazon Timestream para InfluxDB.
-
Portas abertas — Em qual TCP/IP porta seu banco de dados escuta? O firewall de algumas empresas pode bloquear conexões com a porta padrão para o seu mecanismo de banco de dados. O padrão para Timestream para InfluxDB é 8086.
-
AWS Região — Em qual AWS região você deseja seu banco de dados? Ter o banco de dados próximo do aplicativo ou do serviço Web pode reduzir a latência da rede. Para obter mais informações, consulte Regiões da AWS e zonas de disponibilidade.
-
Subsistema de disco de banco de dados: quais são suas necessidades de armazenamento? O Amazon Timestream para InfluxDB oferece três configurações para seu tipo de armazenamento incluído no Influx IOPS:
-
Influx Io Included 3k IOPS (SSD)
-
Influx Io Included 12k IOPS (SSD)
-
Influx Io Included 16k IOPS (SSD)
Para obter mais informações sobre o armazenamento do Amazon Timestream para InfluxDB, consulte o armazenamento de instâncias de banco de dados do Amazon Timestream para InfluxDB. Quando você tiver as informações necessárias para criar o grupo de segurança e a instância de banco de dados, continue na próxima etapa.
-
Fornecer acesso à instância de banco de dados na VPC criando um grupo de segurança
Os grupo de segurança de VPC oferecem acesso a instância de banco de dados em uma VPC. Eles atuam como um firewall para a instância de banco de dados associada, controlando o tráfego de entrada e de saída no nível da instância de banco de dados. As instâncias de bancos de dados são criadas por padrão com um firewall e um grupo de segurança padrão que protege a instância de banco de dados.
Para conseguir se conectar à sua instância de banco de dados, você deve adicionar regras a um grupo de segurança que permita que você se conecte. Use suas informações de rede e configuração para criar regras e permitir acesso à sua instância de banco de dados.
Por exemplo, suponhamos que você tenha um aplicativo que acesse um banco de dados na sua instância de banco de dados em uma VPC. Neste caso, você deve adicionar uma regra TCP personalizada que especifique o intervalo da porta e os endereços IP que seu aplicativo usa para acessar o banco de dados. Se tiver um aplicativo uma instância do Amazon EC2, você poderá usar o grupo de segurança configurado para a instância do Amazon EC2.
Criar um grupo de segurança para acesso à VPC
Para criar um grupo de segurança de VPC, faça login no AWS Management Console e escolha VPC.
nota
Verifique se você está no console da VPC, não no console do Amazon Timesteam para InfluxDB.
-
No canto superior direito do AWS Management Console, escolha a AWS região em que você deseja criar seu grupo de segurança de VPC e sua instância de banco de dados. Na lista de recursos da Amazon VPC para essa AWS região, você deve ver pelo menos uma VPC e várias sub-redes. Caso contrário, você não tem uma VPC padrão nessa AWS região. .
-
No painel de navegação, escolha Grupos de segurança.
-
Escolha Criar grupo de segurança.
-
Na seção Detalhes básicos da página do grupo de segurança, insira o Nome do grupo de segurança e a Descrição. Para VPC escolha a VPC na qual você deseja criar sua instância de banco de dados.
-
Em Inbound rules (Regras de entrada), escolha Add rule (Adicionar regra).
-
Em Type (Tipo), escolha Custom TCP (TCP personalizada).
-
Em Origem, selecione um Nome de grupo de segurança ou digite o Intervalo de endereços IP (valor CIDR) de onde você acessará a instância de banco de dados. Se você selecionar My IP (Meu IP), isso concederá acesso à instância de banco de dados do endereço IP detectado no navegador.
Em Source (Origem), selecione um nome de grupo de segurança ou digite o intervalo de endereços IP (valor CIDR) de onde você acessará a instância. Se você selecionar My IP (Meu IP), isso concederá acesso à instância de banco de dados do endereço IP detectado no navegador.
-
-
(Opcional) Em Outbound rules (Regras de saída), adicione regras para o tráfego de saída. Por padrão, todo tráfego de saída é permitido.
-
Escolha Create grupo de segurança (Criar grupo de segurança).
Você pode usar esse grupo de segurança de VPC como o grupo de segurança de sua instância de banco de dados quando a criar.
nota
Se usar uma VPC padrão, será criada para você um grupo de sub-redes padrão distribuídas por todas as sub-redes da VPC. Quando cria uma instância de banco de dados, você pode selecionar default eiifccntf VPC e escolher default para o Grupo de sub-redes de banco de dados.
Assim que completar os requisitos de configuração, você poderá criar uma instância de banco de dados usando seus requisitos e grupo de segurança. Para isso, siga as declarações em Criar uma instância de banco de dados.
Práticas recomendadas de segurança para o Timestream para InfluxDB
Otimizar gravações no InfluxDB
Como qualquer outro banco de dados de séries temporais, o InfluxDB foi criado para poder ingerir e processar dados em tempo real. Para manter o melhor desempenho do sistema, recomendamos as seguintes otimizações ao gravar dados no InfluxDB:
Gravações em lote: ao gravar dados no InfluxDB, grave dados em lotes para minimizar a sobrecarga da rede relacionada a cada solicitação de gravação. O tamanho ideal do lote é de 5.000 linhas de protocolo de linha por solicitação de gravação. Para escrever várias linhas em uma solicitação, cada linha do protocolo de linha deve ser delimitada por uma nova linha (\n).
Classificar tags por chave: antes de gravar pontos de dados no InfluxDB, classifique as tags por chave em ordem lexicográfica.
measurement,tagC=therefore,tagE=am,tagA=i,tagD=i,tagB=think fieldKey=fieldValue 1562020262 # Optimized line protocol example with tags sorted by key measurement,tagA=i,tagB=think,tagC=therefore,tagD=i,tagE=am fieldKey=fieldValue 1562020262Usar maior precisão de tempo possível: o InfluxDB grava dados com precisão de nanossegundos, porém, se seus dados não forem coletados em nanossegundos, não há necessidade de gravar com essa precisão. Para um melhor desempenho, use a maior precisão possível para registros de data e hora. Você pode especificar a precisão de gravação quando:
Ao usar o SDK, você pode especificar o atributo de hora WritePrecision ao definir o atributo de hora do seu ponto. Para obter mais informações sobre as bibliotecas de cliente do InfluxDB, consulte a Documentação do InfluxDB
. Ao usar o Telegraf, você configura a precisão do tempo na configuração do agente Telegraf. A precisão é especificada como um intervalo de um inteiro + uma unidade (por exemplo, 0s,10ms,2us,4s). As unidades de tempo válidas são “ns”, “us”, “ms” e “s”.
[agent] interval ="10s" metric_batch_size="5000" precision = "0s"
Usar a compressão gzip: use a compressão gzip para acelerar as gravações no InfluxDB e reduzir a largura de banda da rede. Os benchmarks mostraram uma melhoria de velocidade de até 5x quando os dados são compactados.
Ao usar o Telegraf, na configuração do plug-in de saída InfluxDB_v2 em seu telegraf.conf, defina a opção content_encoding como gzip:
[[outputs.influxdb_v2]] urls = ["http://localhost:8086"] # ... content_encoding = "gzip"Ao usar bibliotecas de cliente, cada Biblioteca do cliente do InfluxDB
fornece opções para compactar solicitações de gravação ou impõe a compactação por padrão. O método para ativar a compactação é diferente para cada biblioteca. Para obter instruções específicas, consulte a Documentação do InfluxDB Ao usar o endpoint
/api/v2/writeda API InfluxDB para gravar dados, compacte os dados com gzip e defina o cabeçalho Content-Encoding como gzip.
Projetar para desempenho
Crie seu esquema para consultas mais simples e de maior desempenho. As diretrizes a seguir vão garantir que seu esquema seja fácil de consultar e maximizar o desempenho da consulta:
Design a consultar: escolha medidas
, chaves de tag e chaves de campo que sejam fáceis de consultar. Para fazer isso, siga estes princípios: Use medidas que tenham um nome simples e descrevam o esquema com precisão.
Evite usar o mesmo nome para uma chave de tag
e uma chave de campo dentro do mesmo esquema. Evite usar palavras-chave reservadas do Flux
e caracteres especiais nas teclas de tag e campo. As tags armazenam metadados que descrevem os campos e são comuns em muitos pontos de dados.
Os campos armazenam dados exclusivos ou altamente variáveis, geralmente pontos de dados numéricos.
As medições e chaves não devem conter dados, mas devem ser usadas para agregar ou descrever dados. Os dados serão armazenados em valores de tag e campo.
Mantenha a cardinalidade da série temporal sob controle A alta cardinalidade da série é uma das principais causas da diminuição do desempenho de gravação e leitura no InfluxDB. No contexto do InfluxDB, a alta cardinalidade se refere à presença de um número muito grande de valores de tag exclusivos. Os valores das tags são indexados no InfluxDB, o que significa que um número muito alto de valores exclusivos gerará um índice maior que pode diminuir a ingestão de dados e o desempenho da consulta.
Para entender melhor e resolver possíveis problemas relacionados à alta cardinalidade, você pode seguir estas etapas:
Entender as causas da alta cardinalidade
Medir a cardinalidade de seus buckets
Tomar medidas para resolver a alta cardinalidade
Causas da alta cardinalidade de série O InfluxDB indexa os dados com base em medições e tags para acelerar as leituras de dados. Cada conjunto de elementos de dados indexados forma uma chave de série
. Tags contendo informações altamente variáveis, como strings exclusivas IDs, hashes e aleatórias, levam a um grande número de séries , também conhecido como alta cardinalidade de série . A alta cardinalidade de série é o principal fator de alto uso de memória no InfluxDB. Medindo a cardinalidade da série Se você tiver lentidão no desempenho ou observar um uso cada vez maior de memória em sua instância do Timestream para InfluxDB, recomendamos medir a cardinalidade da série de seus buckets.
O InfluxDB fornece funções que permitem medir a cardinalidade da série tanto no Flux quanto no InfluxQL.
No Flux, use a função
influxdb.cardinality()No FluxQL, use o comando
SHOW SERIES CARDINALITY
Em ambos os casos, o mecanismo retornará o número de chaves de série exclusivas em seus dados. Lembre-se de que não é recomendável ter mais de 10 milhões de chaves de série em nenhuma de suas instâncias do Timestream para InfluxDB.
Causas da alta cardinalidade de série Se você descobrir que algum de seus buckets tem alta cardinalidade, há algumas etapas de correção que você pode seguir para corrigi-lo:
Analise suas tags: garanta que seus workloads não gerem casos em que as tags tenham valores exclusivos para a maioria das entradas. Isso pode acontecer nos casos em que o número de valores de tag exclusivos sempre aumenta com o tempo ou se mensagens do tipo log estão sendo gravadas no banco de dados, onde cada mensagem teria uma combinação exclusiva de registro de data e hora, tags etc. Você pode usar o seguinte código Flux para ajudar a descobrir quais tags estão contribuindo mais para seus problemas de alta cardinalidade:
// Count unique values for each tag in a bucketimport "influxdata/influxdb/schema" cardinalityByTag = (bucket) => schema.tagKeys(bucket: bucket) |> map( fn: (r) => ({ tag: r._value, _value: if contains(set: ["_stop", "_start"], value: r._value) then 0 else (schema.tagValues(bucket: bucket, tag: r._value) |> count() |> findRecord(fn: (key) => true, idx: 0))._value, }), ) |> group(columns: ["tag"]) |> sum() cardinalityByTag(bucket: "amzn-s3-demo-bucket")Se você estiver enfrentando uma cardinalidade muito alta, a consulta acima pode expirar. Se você tiver um tempo limite, execute as consultas abaixo, mas uma de cada vez.
Gerar uma lista de tags:
// Generate a list of tagsimport "influxdata/influxdb/schema" schema.tagKeys(bucket: "amzn-s3-demo-bucket")Contar valores de tag exclusivos para cada tag:
// Run the following for each tag to count the number of unique tag valuesimport "influxdata/influxdb/schema" tag = "example-tag-key" schema.tagValues(bucket: "amzn-s3-demo-bucket1", tag: tag) |> count()Recomendamos que você execute esses comandos em momentos diferentes para identificar qual tag está crescendo mais rápido.
Melhore seu esquema: siga as recomendações de modelagem discutidas em nossoPráticas recomendadas de segurança para o Timestream para InfluxDB.
Remova ou agregue dados antigos para reduzir a cardinalidade: considere se seus casos de uso precisam ou não de todos os dados que estão causando seus problemas de alta cardinalidade. Se esses dados não forem mais necessários ou acessados com frequência, você poderá agregá-los, excluí-los ou exportá-los para outro mecanismo, como o Timestream for Live Analytics, para armazenamento e análise de longo prazo.
