As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Identificação de idioma com trabalhos de transcrição em lote
Use a identificação de idioma em lote para identificar automaticamente um ou mais idiomas no arquivo de mídia.
Se a mídia tiver apenas um idioma, você poderá habilitar a identificação de um único idioma, que identifica o idioma dominante falado no arquivo de mídia e cria a transcrição usando somente esse idioma.
Se a mídia contiver mais de um idioma, você poderá habilitar a identificação de vários idiomas, que identifica todos os idiomas falados no arquivo de mídia e cria a transcrição usando cada idioma identificado. Observe que uma transcrição de vários idiomas é produzida. Você pode usar outros serviços Amazon Translate, como traduzir sua transcrição.
Consulte na tabela de idiomas compatíveis uma lista completa dos idiomas compatíveis e os códigos de idioma associados.
Para conseguir melhores resultados, o arquivo de mídia deve ter pelo menos 30 segundos de fala.
Para exemplos de uso com o AWS Management Console, AWS CLI, e o SDK do AWS Python, consulte. Usar a identificação de idioma com transcrições em lote
Identificar idiomas em áudio com vários idiomas
A identificação de vários idiomas é destinada a arquivos de mídia com vários idiomas e fornece uma transcrição que reflete todos os idiomas compatíveis falados na mídia. Isso significa que, se os locutores mudarem de idioma no meio da conversa ou se cada participante falar um idioma diferente, a saída de transcrição detectará e transcreverá cada idioma corretamente. Por exemplo, se a mídia contiver um locutor bilíngue que esteja alternando entre inglês americano (en-US) e hindi (hi-IN), a identificação de vários idiomas poderá identificar e transcrever o inglês americano falado como en-US e o hindi falado como hi-IN.
Isso difere da identificação de um único idioma, em que apenas um idioma dominante é usado para criar uma transcrição. Nesse caso, qualquer idioma falado que não seja o dominante é transcrito incorretamente.
nota
No momento, não é possível usar edição e modelos de idioma personalizados com a identificação de vários idiomas.
nota
Atualmente, os seguintes idiomas são suportados com identificação em vários idiomas: en-AB, en-AU, en-GB, en-IE, en-IN, en-NZ, en-US, en-WL, en-ZA, es-ES, es-US, fr-CA, fr-FR, zh-CN, zh-TW, pt-BR, pt-PT, de-CH, de-DE, af-za, ar-AE, da-DK, He-il, Hi-in, Identificação, Fa-ir, It-it, Ja-jp, Ko-KR, MS-my, NL-nl, Ru-ru, Ta-in, Te-in, Th-th, Tr-tr
As transcrições de vários idiomas fornecem um resumo dos idiomas detectados e o tempo total em que cada idioma é falado na mídia. Veja um exemplo abaixo:
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
Melhorar a precisão da identificação de idiomas
Com a identificação de idioma, você tem a opção de incluir uma lista de idiomas que você acha que podem estar presentes na mídia. A inclusão de opções de idioma (LanguageOptions) restringe Amazon Transcribe o uso somente dos idiomas que você especifica ao combinar seu áudio com o idioma correto, o que pode acelerar a identificação do idioma e melhorar a precisão associada à atribuição do dialeto correto do idioma.
Se você optar por incluir códigos de idioma, deverá especificar, pelo menos, dois. Não há limite para o número de códigos de idioma que você pode incluir, mas recomendamos usar entre dois e cinco para otimizar a eficiência e a precisão.
nota
Se você incluir códigos de idioma em sua solicitação e nenhum dos códigos de idioma fornecidos corresponder ao idioma ou idiomas identificados em seu áudio, Amazon Transcribe selecionará a correspondência de idioma mais próxima dos códigos de idioma especificados. Em seguida, ele produz uma transcrição nesse idioma. Por exemplo, se sua mídia estiver em inglês dos EUA (en-US) e você Amazon Transcribe fornecer os códigos de idiomazh-CN, e fr-FRde-DE, Amazon Transcribe provavelmente corresponderá sua mídia ao alemão (de-DE) e produzirá uma transcrição em alemão. A incompatibilidade entre códigos de idioma e idiomas falados pode resultar em uma transcrição imprecisa; portanto, recomendamos cautela ao incluir códigos de idioma.
Utilizar a identificação de idioma com outros recursos do Amazon Transcribe
Você pode usar a identificação de idioma em lote com qualquer outro recurso do Amazon Transcribe . Ao combinar a identificação de idioma com outros recursos, você se limitará aos idiomas compatíveis com esses recursos. Por exemplo, se estiver usando a identificação de idioma com a redação de conteúdo, você estará limitado ao inglês dos EUA (en-US) ou ao espanhol dos EUA (es-US), pois esse é o único idioma disponível para redação. Consulte Idiomas oferecidos e recursos específicos do idioma para obter mais informações.
Importante
Se você estiver usando a identificação automática de idioma com a redação de conteúdo ativada e seu áudio contiver outros idiomas além do inglês dos EUA (en-US) ou do espanhol dos EUA (es-US), somente o conteúdo em inglês dos EUA ou espanhol dos EUA será redigido na sua transcrição. Outros idiomas não podem ser editados e não há avisos ou falhas no trabalho.
Modelos de idioma personalizados, vocabulários personalizados e filtros de vocabulário personalizados
Se você quiser adicionar um ou mais modelos de idioma personalizados, vocabulários personalizados ou filtros de vocabulário personalizados à solicitação de identificação de idioma, inclua o parâmetro LanguageIdSettings. Depois, é possível especificar um código de idioma com um modelo de idioma personalizado, vocabulário personalizado e filtro de vocabulário personalizado correspondentes. Observe que a identificação de vários idiomas não é compatível com modelos de idioma personalizados.
É recomendável que você inclua LanguageOptions ao usar LanguageIdSettings para garantir que o dialeto correto do idioma seja identificado. Por exemplo, se você especificar um vocabulário en-US personalizado, mas Amazon Transcribe determinar qual é o idioma falado em sua mídiaen-AU, seu vocabulário personalizado não será aplicado à sua transcrição. Se você incluir LanguageOptions e especificar en-US como o único dialeto do idioma inglês, o vocabulário personalizado será aplicado à transcrição.
Para ver exemplos de LanguageIdSettings em uma solicitação, consulte a Opção 2 da AWS CLI e os painéis suspensos de SDKs da AWS na seção Usar a identificação de idioma com transcrições em lote.
Usar a identificação de idioma com transcrições em lote
Você pode usar a identificação automática de idioma em um trabalho de transcrição em lote usando o AWS Management Console, a AWS CLI ou os SDKs da AWS ; veja os exemplos a seguir:
-
Faça login no AWS Management Console
. -
No painel de navegação, escolha Tarefas de transcrição e selecione Criar tarefa (no canto superior direito). Isso abre a página Especificar os detalhes da tarefa.
-
No painel Configurações de tarefa, encontre a seção Configurações de idioma e selecione Identificação automática de idioma ou Identificação automática de vários idiomas.
Você pode selecionar várias opções de idioma (na caixa suspensa Selecionar idiomas) caso saiba quais idiomas estão presentes no arquivo de áudio. Fornecer opções de idioma pode melhorar a precisão, mas não é obrigatório.
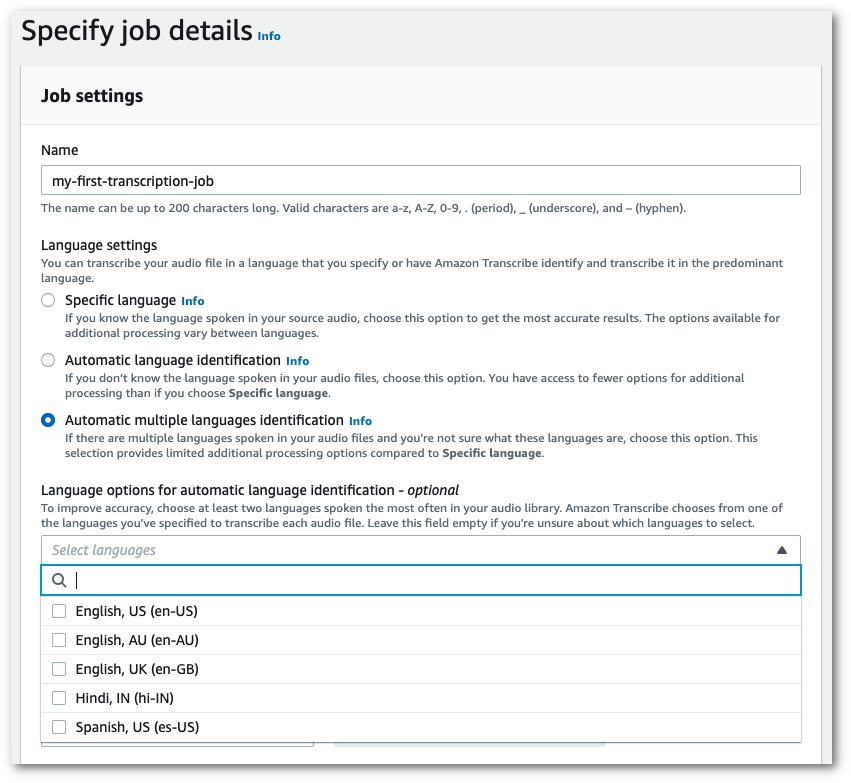
-
Preencha os outros campos que deseja incluir na página Especificar os detalhes da tarefa e selecione Próximo. Isso leva você à página Configurar tarefa - opcional.
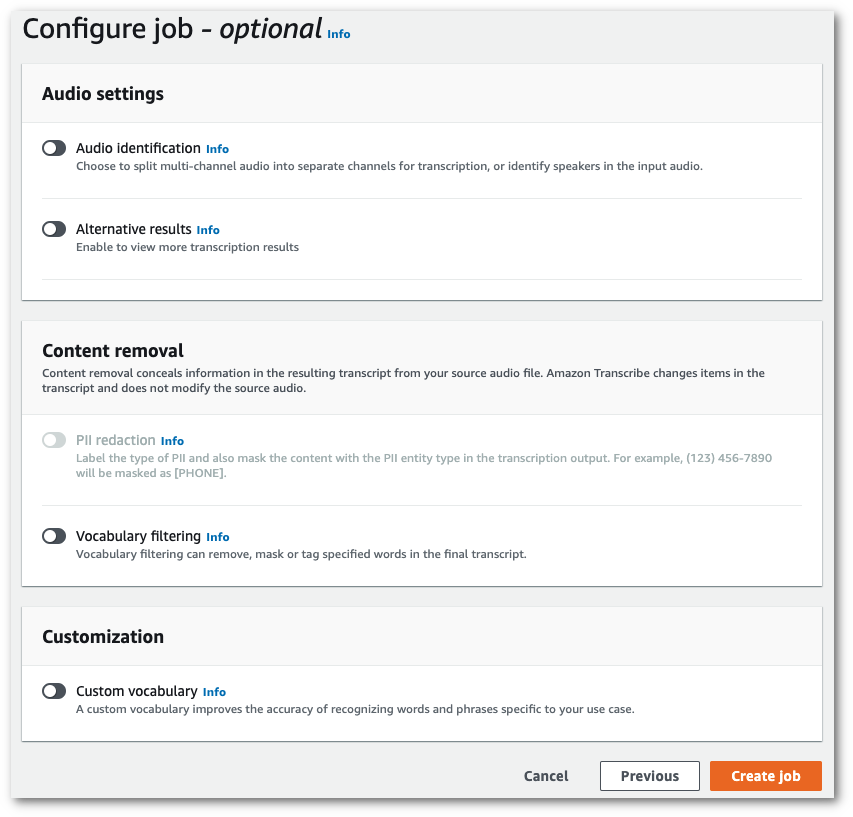
-
Selecione Criar tarefa para executar a tarefa de transcrição.
Este exemplo usa o start-transcription-jobIdentifyLanguage parâmetro. Para obter mais informações, consulte StartTranscriptionJob e LanguageIdSettings.
Opção 1: sem o parâmetro language-id-settings. Use essa opção se você não estiver incluindo um modelo de idioma personalizado, vocabulário personalizado ou filtro de vocabulário personalizado em na solicitação. language-options é opcional, mas recomendado.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
Opção 1: com o parâmetro language-id-settings. Use essa opção se estiver incluindo um modelo de idioma personalizado, um vocabulário personalizado ou um filtro de vocabulário personalizado na solicitação.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
Aqui está outro exemplo usando o start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
O arquivo my-first-language-id-job.json contém o corpo da solicitação a seguir.
Opção 1: sem o parâmetro LanguageIdSettings. Use essa opção se você não estiver incluindo um modelo de idioma personalizado, vocabulário personalizado ou filtro de vocabulário personalizado em na solicitação. LanguageOptions é opcional, mas recomendado.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
Opção 1: com o parâmetro LanguageIdSettings. Use essa opção se estiver incluindo um modelo de idioma personalizado, um vocabulário personalizado ou um filtro de vocabulário personalizado na solicitação.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
Este exemplo usa o AWS SDK for Python (Boto3) para identificar o idioma do seu arquivo usando o IdentifyLanguage argumento do método start_transcription_jobStartTranscriptionJob e LanguageIdSettings.
Para ver exemplos adicionais de uso dos AWS SDKs, incluindo exemplos específicos de recursos, cenários e entre serviços, consulte o capítulo. Exemplos de código para o Amazon Transcribe usando AWS SDKs
Opção 1: sem o parâmetro LanguageIdSettings. Use essa opção se você não estiver incluindo um modelo de idioma personalizado, vocabulário personalizado ou filtro de vocabulário personalizado em na solicitação. LanguageOptions é opcional, mas recomendado.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Opção 1: com o parâmetro LanguageIdSettings. Use essa opção se estiver incluindo um modelo de idioma personalizado, um vocabulário personalizado ou um filtro de vocabulário personalizado na solicitação.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
