As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Falhas cinzentas
As falhas cinzentas são definidas pela característica da observabilidade diferencial
Observabilidade diferencial
As workloads que você opera normalmente têm dependências. Por exemplo, elas podem ser os serviços de nuvem da AWS que você usa para criar sua workload ou um provedor de identidades (IdP) de terceiros que você usa para federação. Essas dependências quase sempre implementam sua própria observabilidade, registrando métricas sobre erros, disponibilidade e latência, entre outras coisas geradas pelo uso do cliente. Quando alguma dessas métricas ultrapassa um limite, a dependência geralmente toma alguma ação para corrigir isso.
Os serviços dessas dependências geralmente têm vários clientes. Os clientes também implementam sua própria observabilidade e criam métricas e logs sobre suas interações com as dependências, registrando coisas como quanta latência existe nas leituras de disco, quantas solicitações de API falharam ou quanto tempo demorou uma consulta ao banco de dados.
Essas interações e medidas são representadas em um modelo abstrato na figura a seguir.
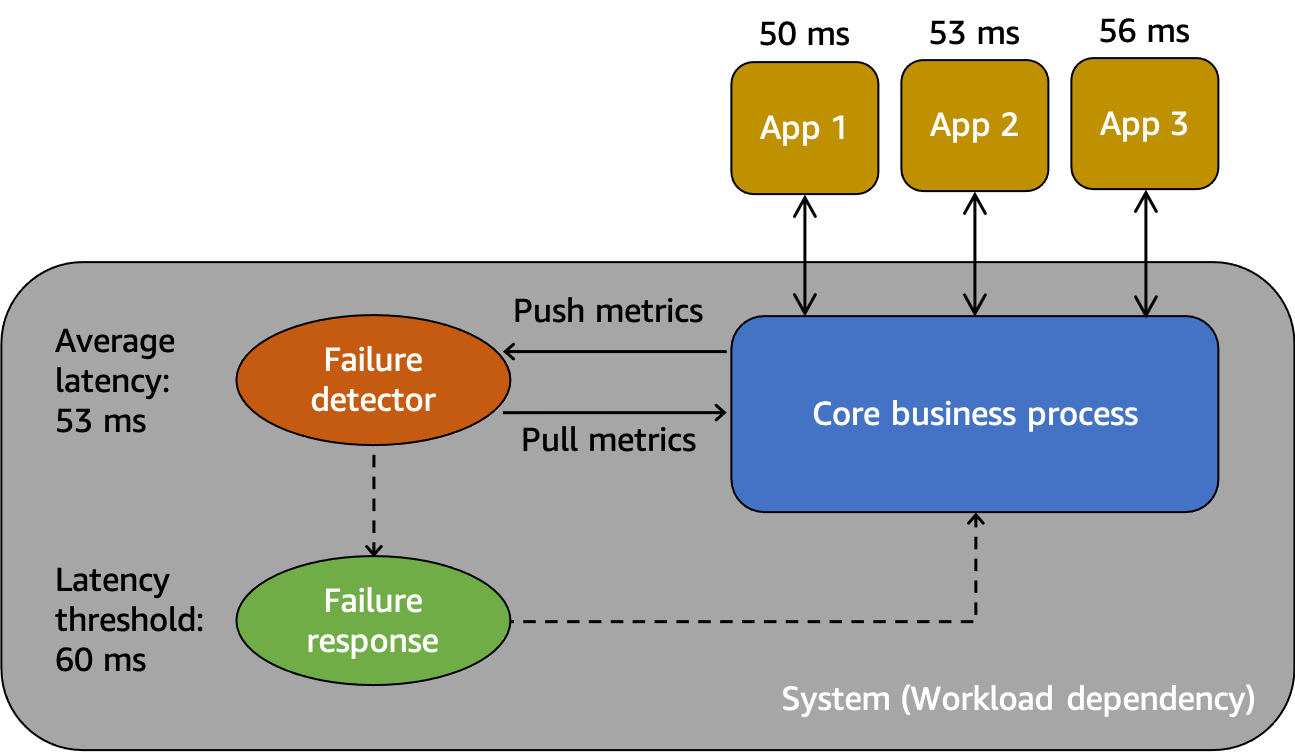
Modelo abstrato para entender as falhas cinzentas
Primeiro, temos o sistema, que é uma dependência dos clientes App 1, App 2 e App 3 neste cenário. O sistema tem um detector de falhas que examina as métricas criadas a partir do processo comercial principal. Ele também tem um mecanismo de resposta a falhas para mitigar ou corrigir problemas observados pelo detector. O sistema tem uma latência média geral de 53 ms e estabeleceu um limite para invocar o mecanismo de resposta a falhas quando a latência média excede 60 ms. App 1, App 2 e App 3 também estão fazendo suas próprias observações sobre suas interações com o sistema, registrando uma latência média de 50 ms, 53 ms e 56 ms, respectivamente.
A observabilidade diferencial acontece quando um dos clientes detecta que o sistema não está íntegro, mas o próprio monitoramento do sistema não detecta o problema ou o impacto não ultrapassa o limite de alarme. Vamos imaginar que o App 1 comece a ter uma latência média de 70 ms, em vez de 50 ms. O App 2 e o App 3 não veem mudança em suas latências médias. Isso aumenta a latência média do sistema subjacente para 59,66 ms, o que não ultrapassa o limite de latência e portanto não ativa o mecanismo de resposta a falhas. No entanto, o App 1 vê um aumento de 40% na latência. Isso pode afetar a disponibilidade ao exceder o tempo limite configurado pelo cliente do App 1, ou pode causar impactos em cascata em uma cadeia mais longa de interações. Do ponto de vista do App 1, o sistema subjacente do qual ele depende não está íntegro, mas do ponto de vista do próprio sistema, bem como do App 2 e do App 3, o sistema está íntegro. A figura a seguir resume essas diferentes perspectivas.
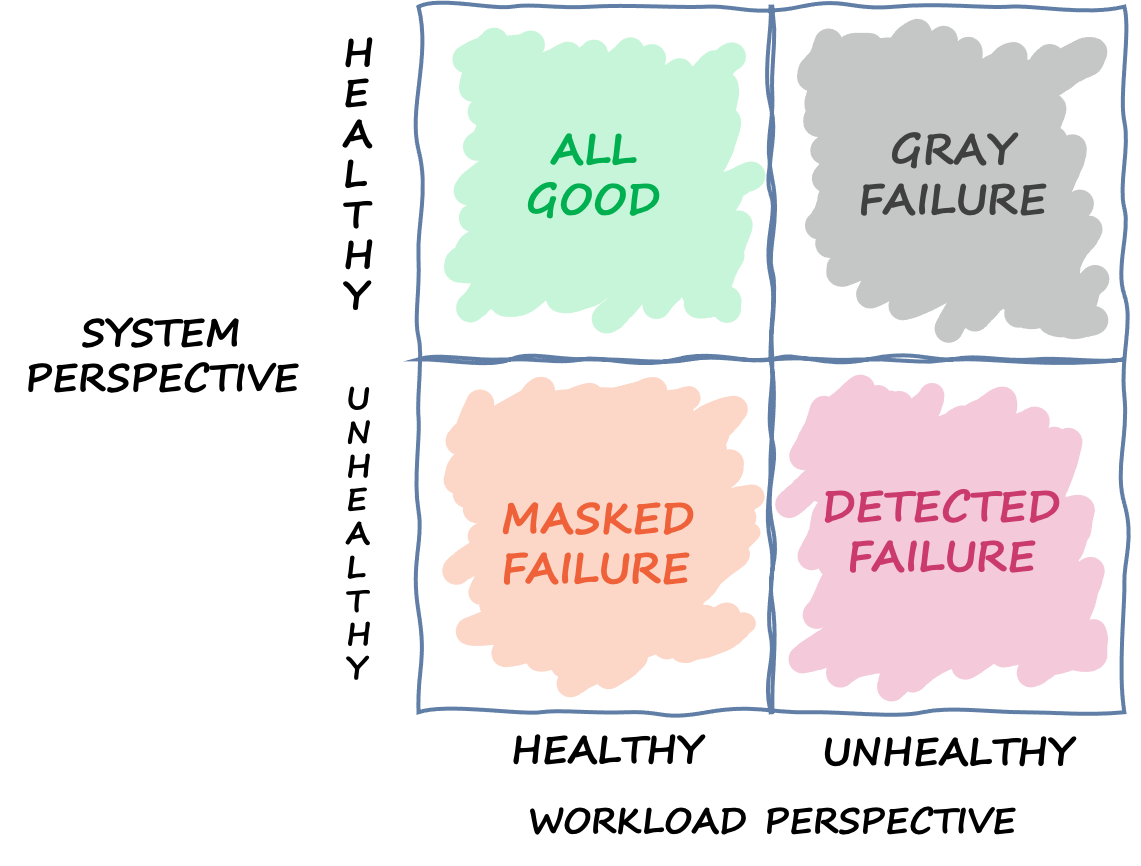
Quadrante definindo os diferentes estados em que um sistema pode estar com base em perspectivas distintas
A falha também pode atravessar esse quadrante. Um evento pode começar como uma falha cinzenta, depois se tornar uma falha detectada, depois passar para uma falha mascarada e, talvez, voltar para uma falha cinzenta. Não há um ciclo definido e quase sempre há chances de recorrência da falha até que a causa raiz seja abordada.
A conclusão que tiramos disso é que workloads nem sempre podem contar com o sistema subjacente para detectar e mitigar falhas. Não importa o quão sofisticado e resiliente seja o sistema subjacente, sempre haverá uma chance de uma falha passar despercebida ou permanecer abaixo do limite de reação. Os clientes desse sistema, como o App 1, precisam estar equipados para detectar e mitigar rapidamente o impacto causado por uma falha cinzenta. Isso requer a construção de mecanismos de observabilidade e recuperação para essas situações.
Exemplo de falha cinzenta
Falhas cinzentas podem ter impacto em sistemas Multi-ZD na AWS. Por exemplo, pegue uma frota de instâncias do Amazon EC2
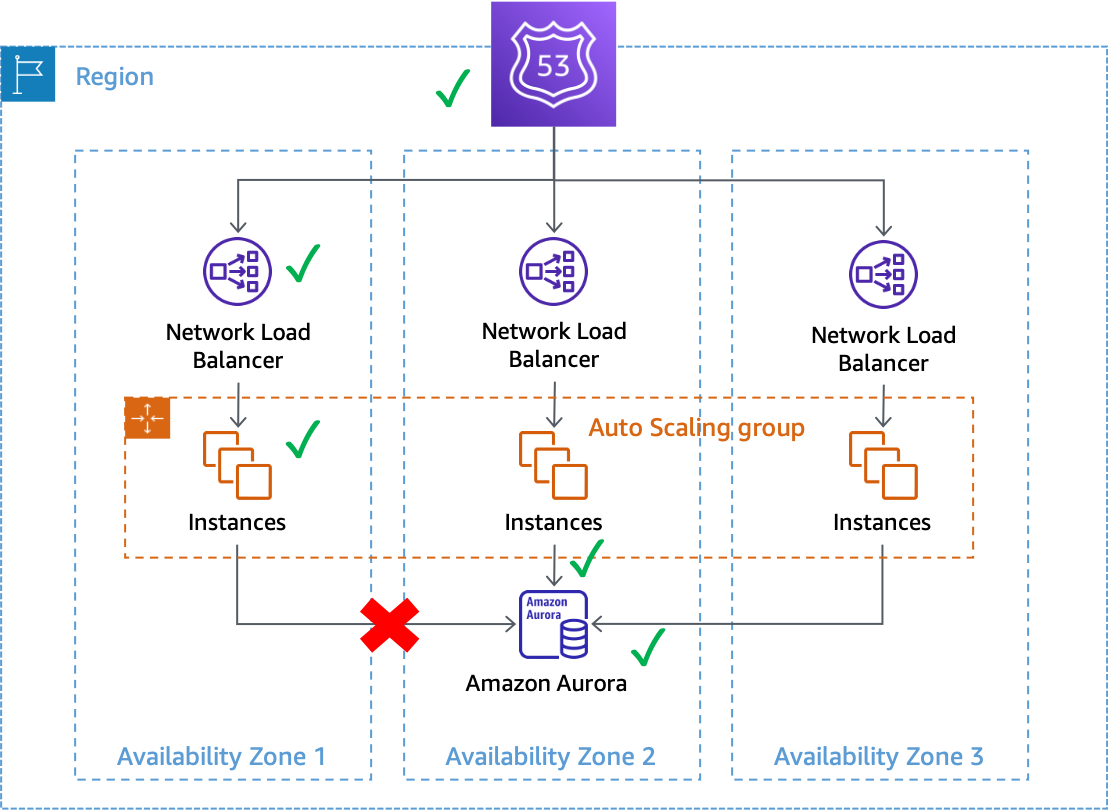
Uma falha cinzenta que afeta as conexões do banco de dados de instâncias na Zona de Disponibilidade 1
Neste exemplo, o Amazon EC2 vê as instâncias na Zona de Disponibilidade 1 como íntegras porque elas continuam passando pelas verificações de status do sistema e da instância. O Amazon EC2 Auto Scaling também não detecta impacto direto em nenhuma Zona de Disponibilidade e continua lançando capacidade nas Zonas configuradas. O Network Load Balancer (NLB) também considera as instâncias por trás dele tão íntegras quanto as verificações de integridade do Route 53 que são realizadas no endpoint de NLB. Da mesma forma, o Amazon Relational Database Service (Amazon RDS) vê o cluster de banco de dados como íntegro e não aciona um failover automático. São muitos serviços diferentes que percebem seus serviços e recursos como íntegros, mas a workload detecta uma falha que afeta a disponibilidade. Isso é uma falha cinzenta.
Como responder a falhas cinzentas
Quando uma falha cinzenta ocorre no seu ambiente da AWS, geralmente há três opções disponíveis:
-
Não fazer nada e esperar o problema passar.
-
Se o problema estiver isolado em uma única Zona de Disponibilidade, evacuar essa Zona.
-
Fazer um failover para outra Região da Região da AWS e usar os benefícios do isolamento regional AWS para mitigar o impacto.
Muitos clientes da AWS se contentam com a primeira opção para a maioria de suas workloads. Eles aceitam ter um objetivo de tempo de recuperação (RTO) possivelmente maior desde que não precisem criar soluções adicionais de observabilidade ou resiliência. Outros clientes optam por implementar a terceira opção, a Recuperação de desastres multirregional
Primeiramente, criar e operar uma arquitetura multirregional pode ser uma tarefa desafiadora, complexa e potencialmente cara. As arquiteturas multirregionais exigem uma análise cuidadosa de qual estratégia de DR será selecionada. Talvez não seja fiscalmente viável implementar uma solução de DR ativa e multirregional apenas para lidar com problemas zonais, enquanto uma estratégia de backup e restauração pode não atender aos seus requisitos de resiliência. Além disso, os failovers multirregionais precisam ser praticados continuamente na produção para que funcionem quando necessário. Tudo isso exige muito tempo e recursos de criação, operação e testagem.
Em segundo lugar, a replicação de dados nas Regiões da AWS usando os serviços da AWS é feita de forma assíncrona hoje. Replicação assíncrona pode ocasionar perda de dados. Isso significa que, durante um failover regional, há uma chance de perda e inconsistência de dados. Sua tolerância à quantidade de perda de dados é definida como seu objetivo de ponto de recuperação (RPO). Os clientes, para quem uma forte consistência de dados é um requisito, precisam criar sistemas de reconciliação para corrigir esses problemas de consistência quando a Região principal estiver disponível novamente. Ou então, precisam criar seus próprios sistemas de replicação síncrona ou de gravação dupla, o que pode ter impactos significativos na latência, no custo e na complexidade da resposta. Eles também tornam a região secundária uma dependência rígida para cada transação, o que pode potencialmente reduzir a disponibilidade do sistema como um todo.
Por fim, para muitas workloads que usam uma abordagem ativa/em espera, é necessário um tempo diferente de zero para realizar o failover em outra Região. Talvez seja necessário reduzir seu portfólio de workloads na Região principal em uma ordem específica, drenar conexões ou interromper processos específicos. Em seguida, talvez seja necessário recuperar os serviços em uma ordem específica. Novos recursos também podem precisar ser provisionados ou exigir tempo para serem aprovados nas verificações de integridade necessárias antes de serem colocados em serviço. Esse processo de failover pode ser um período de total indisponibilidade. É com isso que os RTOs se preocupam.
Dentro de uma Região, muitos serviços da AWS oferecem uma persistência de dados altamente consistente. As implantações Multi-ZD do Amazon RDS usam replicação síncrona. O Amazon Simple Storage Service
A evacuação de uma Zona de Disponibilidade pode ter um RTO menor do que uma estratégia multirregional, porque sua infraestrutura e recursos já estão provisionados nas Zonas de Disponibilidade. Em vez de precisar solicitar cuidadosamente que os serviços sejam desativados e reativados, ou drenar as conexões, as arquiteturas Multi-ZD podem continuar operando de forma estática quando uma Zona de Disponibilidade estiver prejudicada. Em vez de um período de indisponibilidade total que pode ocorrer durante um failover Regional, em uma evacuação da Zona de Disponibilidade, muitos sistemas podem sofrer apenas uma pequena degradação, à medida que o trabalho é transferido para as demais Zonas. Se o sistema tiver sido projetado para ser estaticamente estável
É possível que o comprometimento de uma única Zona de Disponibilidade afete um ou mais serviços regionais da AWS, além de sua workload. Se você observar um impacto Regional, trate o evento como um problema no serviço regional, embora a origem desse impacto seja uma única Zona de Disponibilidade. A evacuação de uma Zona de Disponibilidade não mitigará esse tipo de problema. Use os planos de resposta em vigor para responder a um problema no serviço regional quando isso ocorrer.
O restante deste documento se concentra na segunda opção, evacuar a Zona de Disponibilidade, como forma de obter RTOs e RPOs menores para falhas cinzentas em ZD únicas. Esses padrões podem ajudar a obter melhor valor e eficiência das arquiteturas Multi-ZD e, para a maioria das classes de workload, podem reduzir a necessidade de criar arquiteturas multirregionais para lidar com esses tipos de eventos.
