As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Serviços globais
Além dos AWS serviços regionais e zonais, há um pequeno conjunto de AWS serviços cujos planos de controle e planos de dados não existem de forma independente em cada região. Como seus recursos não são específicos da região, eles são comumente chamados de globais. AWS Os serviços globais ainda seguem o padrão de AWS projeto convencional de separar o plano de controle e o plano de dados para obter estabilidade estática. A diferença significativa para a maioria dos serviços globais é que seu plano de controle é hospedado em um único plano Região da AWS, enquanto seu plano de dados é distribuído globalmente. Há três tipos diferentes de serviços globais e um conjunto de serviços que podem parecer globais com base na configuração selecionada.
As seções a seguir identificarão cada tipo de serviço global e como seus planos de controle e planos de dados são separados. Você pode usar essas informações para orientar como criar mecanismos confiáveis de alta disponibilidade (HA) e recuperação de desastres (DR) sem precisar depender de um plano de controle de serviço global. Essa abordagem ajuda a remover pontos únicos de falha em sua arquitetura e evita possíveis impactos entre regiões, mesmo quando você está operando em uma região diferente de onde o plano de controle de serviço global está hospedado. Também ajuda você a implementar com segurança mecanismos de failover que não dependem de planos de controle de serviço global.
Serviços globais que são exclusivos por partição
Alguns AWS serviços globais existem em cada partição (referidos neste paper como serviços particionais). Os serviços particionais fornecem seu plano de controle em um único Região da AWS. Alguns serviços particionais, como o AWS Network Manager, são somente do plano de controle e orquestram o plano de dados de outros serviços. Outros serviços particionais, comoIAM, têm seu próprio plano de dados, isolado e distribuído em todos os da Regiões da AWS partição. Falhas em um serviço particional não afetam outras partições. Na aws partição, o plano de controle do IAM serviço está na us-east-1 Região, com planos de dados isolados em cada Região da partição. Os serviços particionais também têm planos de controle e planos de dados independentes nas aws-cn partições aws-us-gov e. A separação do plano de controle e do plano de dados para IAM é mostrada no diagrama a seguir.
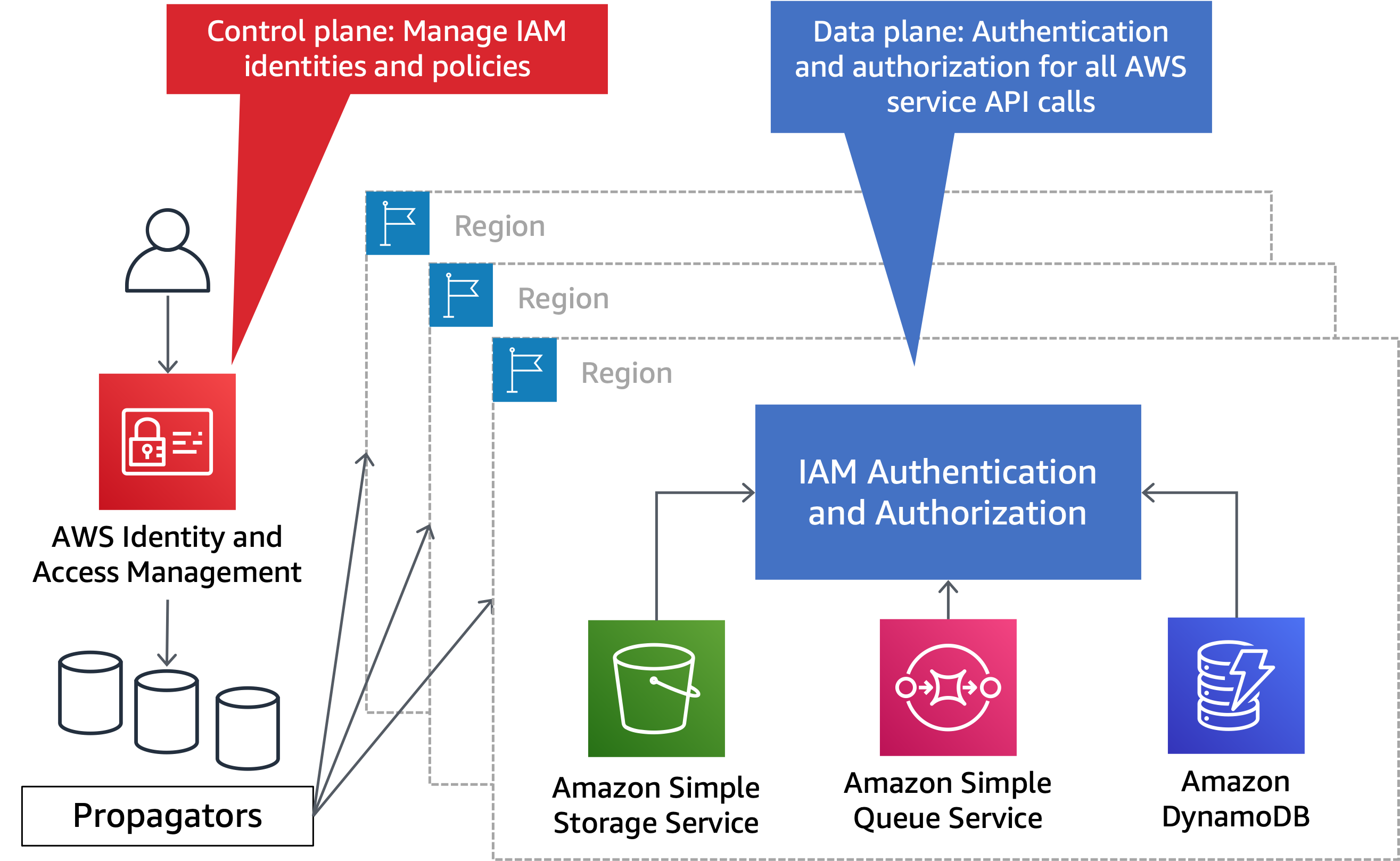
IAMtem um único plano de controle e um plano de dados regionalizado
A seguir estão os serviços particionais e sua localização no plano de controle na aws partição:
-
AWS IAM (
us-east-1) -
AWS Organizations (
us-east-1) -
AWS Gerenciamento de contas (
us-east-1) -
Controlador de recuperação de aplicativos do Route 53 (ARC
us-west-2) () - Este serviço está presente apenas naawspartição -
AWS Gerente de rede (
us-west-2) -
Rota 53 Privada DNS (1
us-east-1)
Se algum desses planos de controle de serviço tiver um evento que afete a disponibilidade, talvez você não consiga usar as operações do CRUDL tipo -fornecidas por esses serviços. Portanto, se sua estratégia de recuperação depender dessas operações, um impacto na disponibilidade do plano de controle ou na região que hospeda o plano de controle reduzirá suas chances de recuperação bem-sucedida. Apêndice A - Orientação de serviço particionalfornece estratégias para remover dependências em planos de controle de serviços globais durante a recuperação.
Recomendação
Não confie nos planos de controle dos serviços particionais em seu caminho de recuperação. Em vez disso, confie nas operações do plano de dados desses serviços. Consulte Apêndice A - Orientação de serviço particional para obter detalhes adicionais sobre como você deve projetar serviços particionais.
Serviços globais na rede de ponta
O próximo conjunto de AWS serviços globais tem um plano de controle na aws partição e hospeda seus planos de dados na infraestrutura de pontos de presença globais (PoP) (e potencialmente Regiões da AWS também). Os planos de dados hospedados PoPs podem ser acessados a partir de recursos em qualquer partição, bem como na Internet. Por exemplo, o Route 53 opera seu plano de controle na us-east-1 região, mas seu plano de dados é distribuído em centenas de PoPs países, bem como em cada um deles Região da AWS (para oferecer suporte ao Route 53 público e privado na DNS região). As verificações de integridade do Route 53 também fazem parte do plano de dados e são executadas a partir de oito Regiões da AWS na aws partição. Os clientes podem resolver DNS usando zonas hospedadas públicas do Route 53 de qualquer lugar na Internet, incluindo outras partições GovCloud, como, bem como de uma nuvem privada AWS
virtual (VPC). A seguir estão os serviços de rede de borda global e sua localização no plano de controle na aws partição:
-
Rota 53 Pública DNS (1
us-east-1) -
Amazon CloudFront (
us-east-1) -
AWS WAF Clássico para CloudFront (
us-east-1) -
AWS WAF para CloudFront (
us-east-1) -
Amazon Certificate Manager (ACM) para CloudFront (
us-east-1) -
AWSAcelerador global (AGA) (
us-west-2) -
AWS Shield Advanced (
us-east-1)
Se você usa verificações de AGA saúde para EC2 instâncias ou endereços IP elásticos, eles usam verificações de saúde do Route 53. Criar ou atualizar verificações de AGA saúde dependeria do plano de controle do Route 53 emus-east-1. A execução das verificações de AGA saúde utiliza o plano de dados de verificação de saúde do Route 53.
Durante uma falha afetando a região que hospeda os planos de controle desses serviços, ou uma falha afetando o próprio plano de controle, talvez você não consiga usar as operações do CRUDL tipo -fornecidas por esses serviços. Se você depender dessas operações em sua estratégia de recuperação, essa estratégia pode ter menos probabilidade de sucesso do que se você confiasse apenas no plano de dados desses serviços.
Recomendação
Não confie no plano de controle dos serviços de rede de ponta em seu caminho de recuperação. Em vez disso, confie nas operações do plano de dados desses serviços. Consulte Apêndice B - Orientação de serviço global da rede Edge para obter detalhes adicionais sobre como projetar serviços globais na rede de borda.
Operações globais em uma única região
A categoria final é composta por operações específicas do plano de controle dentro de um serviço que tem um escopo de impacto global, não por serviços inteiros, como nas categorias anteriores. Enquanto você interage com serviços zonais e regionais na região especificada, determinadas operações têm uma dependência subjacente em uma única região que é diferente de onde o recurso está localizado. Eles são diferentes dos serviços fornecidos somente em uma única região; consulte Apêndice C - Serviços de região única para obter uma lista desses serviços.
Durante uma falha que afeta a dependência global subjacente, talvez você não consiga usar as ações do CRUDL tipo -das operações dependentes. Se você depender dessas operações em sua estratégia de recuperação, essa estratégia pode ter menos probabilidade de sucesso do que se você confiasse apenas no plano de dados desses serviços. Você deve evitar dependências dessas operações para sua estratégia de recuperação.
A seguir está uma lista de serviços dos quais outros serviços podem depender, que têm escopo global:
-
Rota 53
Vários AWS serviços criam recursos que fornecem DNS nomes específicos para o recurso. Por exemplo, quando você provisiona um Elastic Load Balancer (ELB), o serviço cria DNS registros públicos e verificações de saúde no Route 53 para o. ELB Isso depende do plano de controle do Route 53 em
us-east-1. Outros serviços que você usa também podem precisar provisionar umELB, criar DNS registros públicos do Route 53 ou criar verificações de integridade do Route 53 como parte de seus fluxos de trabalho do plano de controle. Por exemplo, provisionar um REST API recurso do Amazon API Gateway, um banco de dados do Amazon Relational Database Service (AmazonRDS) ou um domínio do Amazon OpenSearch Service resultam na criação de DNS registros no Route 53. A seguir está uma lista de serviços cujo plano de controle depende do plano de controle do Route 53us-east-1para criar, atualizar ou excluir DNS registros, zonas hospedadas e/ou criar verificações de saúde do Route 53. Essa lista não é exaustiva; ela serve para destacar alguns dos serviços mais usados, cujas ações do plano de controle para criar, atualizar ou excluir recursos dependem do plano de controle do Route 53:-
Amazon API Gateway REST e HTTP APIs
-
RDSInstâncias da Amazon
-
Bancos de dados Amazon Aurora
-
ELBBalanceadores de carga da Amazon
-
AWS PrivateLink VPCendpoints
-
AWS Lambda URLs
-
Amazon ElastiCache
-
OpenSearch Serviço Amazon
-
Amazon CloudFront
-
Amazon MemoryDB
-
Amazon Neptune
-
Acelerador do Amazon DynamoDB () DAX
-
AGA
-
Amazon Elastic Container Service (AmazonECS) com Service Discovery DNS baseado (que usa o AWS Cloud Map API para gerenciar o Route 53DNS)
-
Plano de controle EKS do Amazon Kubernetes
É importante observar que os nomes de host do VPC DNS serviço, por EC2 exemplo, existem de forma independente em cada um Região da AWS e não dependem do plano de controle do Route 53. Registros AWS criados para EC2 instâncias no VPC DNS serviço, como
ip-10-0-10.ec2.internal,ip-10-0-1-5.compute.us-west-2.compute.internali-0123456789abcdef.ec2.internal, ei-0123456789abcdef.us-west-2.compute.internal, não dependem do plano de controle do Route 53 emus-east-1.Recomendação
Não confie na criação, atualização ou exclusão de recursos que exijam a criação, atualização ou exclusão de registros de recursos, zonas hospedadas ou verificações de saúde do Route 53 em seu caminho de recuperação. Pré-provisione esses recursos, por exemploELBs, para evitar uma dependência do plano de controle do Route 53 em seu caminho de recuperação.
-
-
Amazon S3
As seguintes operações do plano de controle do Amazon S3 têm uma dependência subjacente
us-east-1na partição.awsUma falha afetando o Amazon S3 ou outros serviçosus-east-1em pode fazer com que essas ações dos planos de controle sejam prejudicadas em outras regiões:PutBucketCorsDeleteBucketCorsPutAccelerateConfigurationPutBucketRequestPaymentPutBucketObjectLockConfigurationPutBucketTaggingDeleteBucketTaggingPutBucketReplicationDeleteBucketReplicationPutBucketEncryptionDeleteBucketEncryptionPutBucketLifecycleDeleteBucketLifecyclePutBucketNotificationPutBucketLoggingDeleteBucketLoggingPutBucketVersioningPutBucketPolicyDeleteBucketPolicyPutBucketOwnershipControlsDeleteBucketOwnershipControlsPutBucketAclPutBucketPublicAccessBlockDeleteBucketPublicAccessBlockO plano de controle dos pontos de acesso multirregionais do Amazon S3 (MRAP) é hospedado somente em
us-west-2e as solicitações de criação, atualização ou exclusão são MRAPs direcionadas diretamente a essa região. O plano de controle do MRAP também tem dependências subjacentes AGA em inus-west-2, Route 53 emus-east-1e ACM em cada região de onde MRAP está configurado para veicular conteúdo. Você não deve depender da disponibilidade do plano de MRAP controle em seu caminho de recuperação ou nos planos de dados de seus próprios sistemas. Isso é diferente dos controles de MRAP failover que são usados para especificar o status de roteamento ativo ou passivo para cada um dos seus buckets no. MRAP Eles APIs são hospedados em cinco Regiões da AWS e podem ser usados para mudar efetivamente o tráfego usando o plano de dados do serviço.Além disso, os nomes de bucket do Amazon S3 são globalmente exclusivos e todas as chamadas para o
CreateBucketeDeleteBucketAPIs dependemus-east-1, naawspartição, para garantir a exclusividade do nome, mesmo que a API chamada seja direcionada à região específica na qual você deseja criar o bucket. Por fim, se você tiver fluxos de trabalho críticos de criação de intervalos, não deverá depender da disponibilidade de nenhuma grafia específica do nome de um intervalo, especialmente aqueles que seguem um padrão perceptível.Recomendação
Não confie na exclusão ou criação de novos buckets do S3 nem na atualização das configurações do bucket do S3 como parte do seu caminho de recuperação. Pré-provisione todos os buckets S3 necessários com as configurações necessárias para que você não precise fazer alterações para se recuperar de uma falha. Essa abordagem também MRAPs se aplica a.
-
CloudFront
O Amazon API Gateway fornece endpoints otimizados para bordas API. A criação desses endpoints depende do plano CloudFront de controle
us-east-1para criar a distribuição na frente do endpoint do gateway.Recomendação
Não confie na criação de novos endpoints de API gateway otimizados para bordas como parte de seu caminho de recuperação. Pré-provisione todos os endpoints de API Gateway necessários.
Todas as dependências discutidas nesta seção são ações do plano de controle, não ações do plano de dados. Se suas cargas de trabalho estiverem configuradas para serem estaticamente estáveis, essas dependências não devem afetar seu caminho de recuperação, lembrando que a estabilidade estática exige trabalho ou serviços adicionais para ser implementada.
Serviços que usam endpoints globais padrão
Em alguns casos, os AWS serviços fornecem um endpoint global padrão, como o AWS Security Token Service (AWS STS). Outros serviços podem usar esse endpoint global padrão em sua configuração padrão. Isso significa que um serviço regional que você está usando pode ter uma dependência global de um único Região da AWS. Os detalhes a seguir explicam como remover dependências não intencionais em endpoints globais padrão que ajudarão você a usar o serviço de forma regional.
AWS STS: STS é um serviço web que permite que você solicite credenciais temporárias com privilégios limitados para IAM usuários ou para usuários que você autentica (usuários federados). STSo uso do kit de desenvolvimento de AWS software (SDK) e da interface de linha de comando (CLI) é padronizado como. us-east-1 O STS serviço também fornece endpoints regionais. Esses endpoints são ativados por padrão em regiões que também são ativadas por padrão. Você pode tirar proveito deles a qualquer momento configurando SDK ou CLI seguindo estas instruções: Endpoints AWS STSregionalizados. O uso do SIGv4a também requer credenciais temporárias solicitadas de um endpoint regional. STS Você não pode usar o STS endpoint global para essa operação.
Recomendação
Atualize sua CLI configuração SDK e para usar os STS endpoints regionais.
Login da Security Assertion Markup Language (SAML): os SAML serviços existem em todos. Regiões da AWS Para usar esse serviço, escolha o SAML endpoint regional apropriado, como https://us-west-2.signin.aws.amazon.com/saml
Se você estiver usando um IdP que também esteja hospedado AWS, existe o risco de que ele também seja afetado durante um AWS evento de falha. Isso pode fazer com que você não consiga atualizar sua configuração de IdP ou talvez não consiga federar totalmente. Você deve pré-provisionar usuários “quebra-vidro” caso seu IdP esteja comprometido ou indisponível. Consulte Apêndice A - Orientação de serviço particional para obter detalhes sobre como criar usuários de quebra-vidros de uma forma estaticamente estável.
Recomendação
Atualize suas políticas de confiança de IAM funções para aceitar SAML logins de várias regiões. Durante uma falha, atualize sua configuração de IdP para usar um endpoint regional diferente se seu SAML endpoint preferencial estiver comprometido. Crie um (s) usuário (s) inovador (s) caso seu IdP esteja comprometido ou indisponível.
AWS IAMIdentity Center: O Identity Center é um serviço baseado em nuvem que facilita o gerenciamento centralizado do acesso de login único aos aplicativos do cliente e da nuvem. Contas da AWS O Identity Center deve ser implantado em uma única região de sua escolha. No entanto, o comportamento padrão do serviço é usar o SAML endpoint global (https://signin.aws.amazon.com/samlus-east-1. Se você implantou o Identity Center em outro Região da AWS, você deve atualizar o estado de retransmissão URL de cada conjunto de permissões para atingir o mesmo endpoint de console regional da implantação do Identity Center. Por exemplo, se você implantou o Identity Center emus-west-2, você deve atualizar o estado de retransmissão dos seus conjuntos de permissões para usar https://us-west-2---console---aws.amazon.com.rproxy.goskope.com.us-east-1 da sua implantação do Identity Center.
Além disso, como o IAM Identity Center só pode ser implantado em uma única região, você deve pré-provisionar usuários “inovadores” caso sua implantação seja prejudicada. Consulte Apêndice A - Orientação de serviço particional para obter detalhes sobre como criar usuários de quebra-vidros de uma forma estaticamente estável.
Recomendação
Defina o estado URL de retransmissão de seus conjuntos de permissões no IAM Identity Center para corresponder à região em que você tem o serviço implantado. Crie um (s) usuário (s) inovador (s) caso sua implantação do IAM Identity Center não esteja disponível.
Lente de armazenamento Amazon S3: o Storage Lens fornece um painel padrão chamado. default-account-dashboard A configuração do painel e suas métricas associadas são armazenadas emus-east-1. Você pode criar painéis adicionais em outras regiões especificando a região de origem para a configuração do painel e os dados métricos.
Recomendação
Se você precisar de dados do painel padrão do S3 Storage Lens durante uma falha que afeta o serviçous-east-1, crie um painel adicional em uma região de origem alternativa. Você também pode duplicar qualquer outro painel personalizado criado em regiões adicionais.
Resumo dos serviços globais
Os planos de dados para serviços globais aplicam princípios de isolamento e independência semelhantes aos AWS serviços regionais. Uma falha afetando o plano de dados IAM de uma região não afeta a operação do plano de IAM dados em outra Região da AWS. Da mesma forma, uma falha afetando o plano de dados do Route 53 em um PoP não afeta a operação do plano de dados do Route 53 no resto do PoPs. Portanto, o que devemos considerar são os eventos de disponibilidade de serviços que afetam a região onde o plano de controle opera ou afetam o próprio plano de controle. Como há apenas um único plano de controle para cada serviço global, uma falha que afeta esse plano de controle pode ter efeitos entre regiões nas operações do CRUDL tipo -( que são as operações de configuração normalmente usadas para instalar ou configurar um serviço, em oposição ao uso direto do serviço).
A maneira mais eficaz de arquitetar cargas de trabalho para usar serviços globais de forma resiliente é usar a estabilidade estática. Durante um cenário de falha, projete sua carga de trabalho para não precisar fazer alterações em um plano de controle para mitigar o impacto ou o failover em um local diferente. Consulte Apêndice A - Orientação de serviço particional e obtenha Apêndice B - Orientação de serviço global da rede Edge orientações prescritivas sobre como utilizar esses tipos de serviços globais para remover dependências do plano de controle e eliminar pontos únicos de falha. Se você precisar dos dados de uma operação do plano de controle para recuperação, armazene esses dados em um armazenamento de dados que possa ser acessado por meio de seu plano de dados, como um parâmetro do AWS Systems ManagerDescribeCluster API operação.
A seguir está um resumo de algumas das configurações incorretas ou antipadrões mais comuns que introduzem dependências nos planos de controle dos serviços globais:
-
Fazer alterações nos registros do Route 53, como atualizar o valor de um registro A ou alterar os pesos de um conjunto de registros ponderados, para realizar o failover.
-
Criação ou atualização de IAM recursos, incluindo IAM funções e políticas, durante um failover. Normalmente, isso não é intencional, mas pode ser resultado de um plano de failover não testado.
-
Contando com o IAM Identity Center para que os operadores tenham acesso aos ambientes de produção durante um evento de falha.
-
Contando com a configuração padrão do IAM Identity Center para utilizar o console
us-east-1quando você tiver implantado o Identity Center em uma região diferente. -
Fazer alterações nos pesos de discagem de AGA tráfego para realizar manualmente um failover regional.
-
Atualizar a configuração de origem de uma CloudFront distribuição para evitar uma origem danificada.
-
Provisionamento de recursos de recuperação de desastres (DR), como ELBs RDS instâncias durante um evento de falha, que dependem da criação de DNS registros no Route 53.
A seguir está um resumo das recomendações fornecidas nesta seção para o uso de serviços globais de forma resiliente que ajudaria a evitar os antipadrões comuns anteriores.
Resumo da recomendação
Não confie nos planos de controle dos serviços particionais em seu caminho de recuperação. Em vez disso, confie nas operações do plano de dados desses serviços. Consulte Apêndice A - Orientação de serviço particional para obter detalhes adicionais sobre como você deve projetar serviços particionais.
Não confie no plano de controle dos serviços de rede de ponta em seu caminho de recuperação. Em vez disso, confie nas operações do plano de dados desses serviços. Consulte Apêndice B - Orientação de serviço global da rede Edge para obter detalhes adicionais sobre como projetar serviços globais na rede de borda.
Não confie na criação, atualização ou exclusão de recursos que exijam a criação, atualização ou exclusão de registros de recursos, zonas hospedadas ou verificações de saúde do Route 53 em seu caminho de recuperação. Pré-provisione esses recursos, por exemploELBs, para evitar uma dependência do plano de controle do Route 53 em seu caminho de recuperação.
Não confie na exclusão ou criação de novos buckets do S3 nem na atualização das configurações do bucket do S3 como parte do seu caminho de recuperação. Pré-provisione todos os buckets S3 necessários com as configurações necessárias para que você não precise fazer alterações para se recuperar de uma falha. Essa abordagem também MRAPs se aplica a.
Não confie na criação de novos endpoints de API gateway otimizados para bordas como parte de seu caminho de recuperação. Pré-provisione todos os endpoints de API Gateway necessários.
Atualize sua CLI configuração SDK e para usar os STS endpoints regionais.
Atualize suas políticas de confiança de IAM funções para aceitar SAML logins de várias regiões. Durante uma falha, atualize sua configuração de IdP para usar um endpoint regional diferente se seu SAML endpoint preferencial estiver comprometido. Crie usuários incomparáveis caso seu IdP esteja comprometido ou indisponível.
Defina o estado URL de retransmissão de seus conjuntos de permissões no IAM Identity Center para corresponder à região em que você tem o serviço implantado. Crie um (s) usuário (s) inovador (s) caso sua implantação do Identity Center não esteja disponível.
Se você precisar de dados do painel padrão do S3 Storage Lens durante uma falha que afeta o serviçous-east-1, crie um painel adicional em uma região de origem alternativa. Você também pode duplicar qualquer outro painel personalizado criado em regiões adicionais.
