Understand the options for deploying models and getting inferences in Amazon SageMaker AI
To help you get started with SageMaker AI Inference, see the following sections which explain your options for deploying your model in SageMaker AI and getting inferences. The Inference options in Amazon SageMaker AI section can help you determine which feature best fits your use case for inference.
You can refer to the Resources section for more troubleshooting and reference information, blogs and examples to help you get started, and common FAQs.
Topics
Before you begin
These topics assume that you have built and trained one or more machine learning models and are ready to deploy them. You don't need to train your model in SageMaker AI in order to deploy your model in SageMaker AI and get inferences. If you don't have your own model, you can also use SageMaker AI’s built-in algorithms or pre-trained models.
If you are new to SageMaker AI and haven't picked out a model to deploy, work through the steps in the Get Started with Amazon SageMaker AI tutorial. Use the tutorial to get familiar with how SageMaker AI manages the data science process and how it handles model deployment. For more information about training a model, see Train Models.
For additional information, reference, and examples, see the Resources.
Steps for model deployment
For inference endpoints, the general workflow consists of the following:
Create a model in SageMaker AI Inference by pointing to model artifacts stored in Amazon S3 and a container image.
Select an inference option. For more information, see Inference options in Amazon SageMaker AI.
Create a SageMaker AI Inference endpoint configuration by choosing the instance type and number of instances you need behind the endpoint. You can use Amazon SageMaker Inference Recommender to get recommendations for instance types. For Serverless Inference, you only need to provide the memory configuration you need based on your model size.
Create a SageMaker AI Inference endpoint.
Invoke your endpoint to receive an inference as a response.
The following diagram shows the preceding workflow.
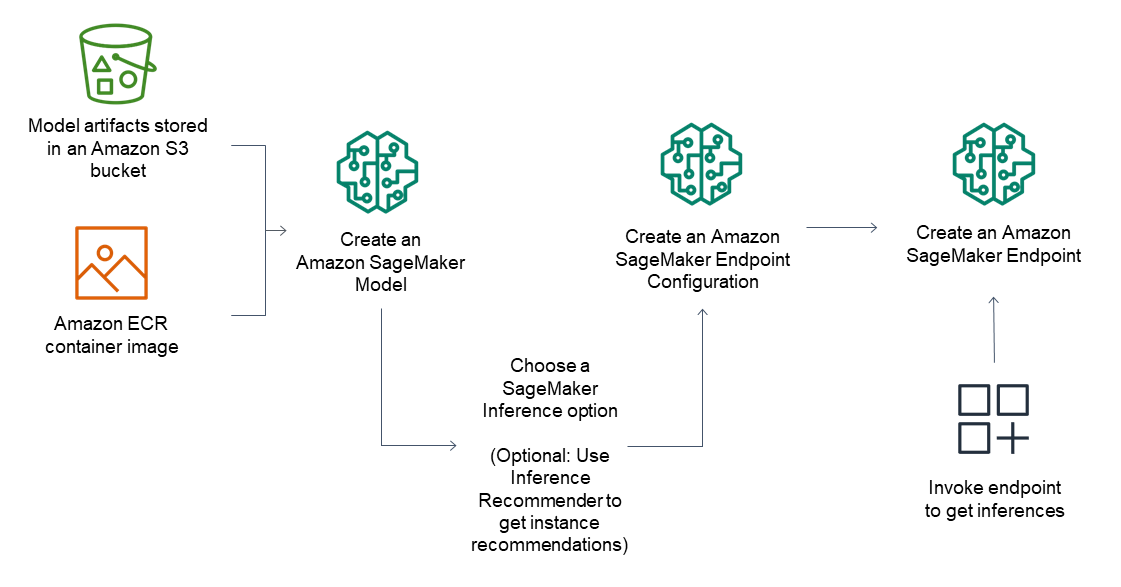
You can perform these actions using the AWS console, the AWS SDKs, the SageMaker Python SDK, AWS CloudFormation or the AWS CLI.
For batch inference with batch transform, point to your model artifacts and input data and create a batch inference job. Instead of hosting an endpoint for inference, SageMaker AI outputs your inferences to an Amazon S3 location of your choice.
