This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Availability Zone independence
To achieve the first outcome, to stop sending work to the impacted Availability Zone,
evacuation requires that you implement Availability Zone
Independence
In a request/response type workload, implementing AZI requires you to disable cross-zone load balancing for Application Load Balancers (ALB), Classic Load Balancers (CLB), and Network Load Balancers (NLB) (cross-zone load balancing is disabled by default for NLBs). Disabling cross-zone load balancing has a few tradeoffs. When you disable cross-zone load balancing, traffic is evenly split between each Availability Zone regardless of how many instances are in each one. If you have unbalanced resources or Auto Scaling groups, this could put additional load on resources in an Availability Zone that has fewer resources than others. This is shown in the following figure where two instances in Availability Zone 1 are each receiving 25% of the load and the five instances in Availability Zone 2 are each receiving 10% of the load.

The effect of disabling cross-zone load balancing with unbalanced instances
Other zonal services that you use will also need to be implemented using AZI patterns to support effective Availability Zone evacuation. For example, interface VPC endpoints provide specific DNS names for each Availability Zone the interface endpoint is made available in.
One challenge with implementing AZI is with databases, especially because most relational databases only support a single primary writer at any time. When communicating with the primary instance, you may need to cross an Availability Zone boundary. Many AWS database services support a user-defined Multi-AZ configuration and have a built-in multi-AZ failover feature, such as Amazon RDS or Amazon Aurora. In many failure scenarios, the service can detect the impact and automatically failover the database to a different Availability Zone when a problem occurs. However, during a gray failure, the service may not detect the impact that is affecting your workload, or the impact may not be related to the database at all. In these cases, once you detect impact in an Availability Zone, you can manually invoke a failover to move the primary database. This allows you to effectively react to a single Availability Zone impairment.
If you are using read replicas with those databases, you may also want to implement AZI for those because you cannot failover a read replica to a different Availability Zone like you can the primary database. If you have a single read replica in Availability Zone 1, and instances across three Availability Zones are configured to use it, an impairment impacting Availability Zone 1 will also impact operations in the other two Availability Zones. That’s the impact you want to prevent.
For RDS instances, you receive a DNS endpoint to access the replica in a specific
Availability Zone. To achieve AZI, you would need a read replica per Availability Zone and a
way for your application to know which replica endpoint to use for the Availability Zone it’s
in. One approach you can take is to use the Availability Zone ID as part of the database
identifier, something like
use1-az1-read-replica.cbkdgoeute4n.us-east-1.rds.amazonaws.com. You can also do
this using service discovery (such as with AWS Cloud Map

Discovering RDS endpoint DNS names for each Availability Zone
Amazon Aurora’s default configuration is to provide a single reader endpoint that load balances requests across available read replicas.
In order to implement AZI using Aurora, you can use a custom endpoint for each read replica using the ANY type (so you can
promote a read replica if required). Name the custom endpoint based on the Availability Zone
ID where the replica is deployed. Then, you can use the DNS name provided by the custom
endpoint to connect to a specific read replica in a specific Availability Zone, which is shown
in the following figure.
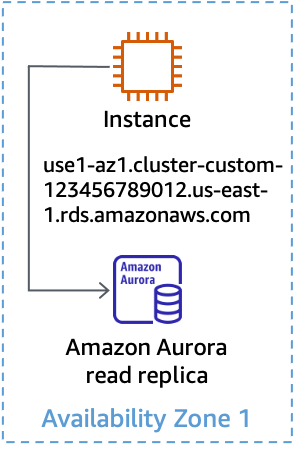
Using a custom endpoint for an Aurora read replica
When your system is architected this way, it makes Availability Zone evacuation a much simpler task. For example, in the following figure when there is an impairment affecting Availability Zone 3, both read and write operations in Availability Zones 1 and 2 are not affected.

Using AZI to prevent impact with Amazon Aurora read replicas
Alternatively, if Availability Zone 2 was impacted, read operations would still succeed in Availability Zones 1 and 3. Then, if Amazon Aurora hasn’t automatically failed over the primary database, you can manually invoke a failover to a different Availability Zone to restore the capability for processing writes. This approach prevents needing to make any configuration changes in your database connections when you need to evacuate an Availability Zone. Minimizing the required changes and keeping the process as simple as possible will make it more reliable.
