Availability with redundancy
When a workload utilizes multiple, independent, and redundant subsystems, it can achieve a higher level of theoretical availability than by using a single subsystem. For example, consider a workload composed of two identical subsystems. It can be completely operational if either subsystem one or subsystem two is operational. For the whole system to be down, both subsystems must be down at the same time.
If one subsystem's probability of failure is 1 − α, then the probability that two redundant subsystems being down at the same time is the product of each subsystem's probability of failure, F = (1−α1) × (1−α2). For a workload with two redundant subsystems, using Equation (3), this gives an availability defined as:

Equation 5
So, for two subsystems whose availability is 99%, the probability that one fails is 1% and the probability that they both fail is (1−99%) × (1−99%) = .01%. This makes the availability using two redundant subsystems 99.99%.
This can be generalized to incorporate additional redundant spares, s, as well. In Equation (5) we only assumed a single spare, but a workload might have two, three, or more spares so that it can survive the simultaneous loss of multiple subsystems without impacting availability. If a workload has three subsystems and two are spares, the probability that all three subsystems fail at the same time is (1−α) × (1−α) × (1−α) or (1−α)3. In general, a workload with s spares will only fail if s + 1 subsystems fail.
For a workload with n subsystems and s spares, f is the number of failure modes or the ways that s + 1 subsystems can fail out of n.
This is effectively the binomial theorem, the combinatorial math of choosing k elements from a set of n, or “n choose k”. In this case, k is s + 1.

Equation 6
We can then produce a generalized availability approximation that incorporates the number
of failure modes and sparing. (To understand why this in an approximation, refer to Appendix 2
of Highleyman, et al. Breaking the Availability Barrier
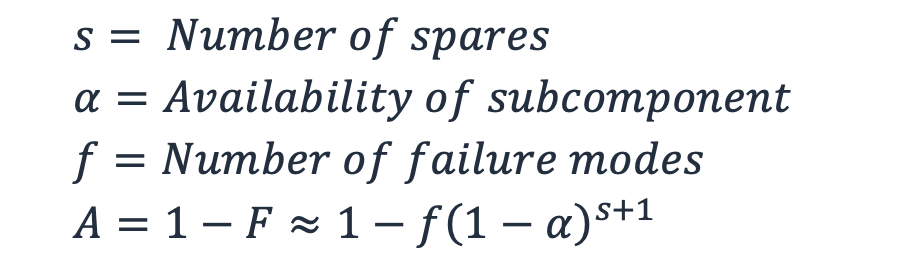
Equation 7
Sparing can be applied to any dependency that provides resources that fail independently. Amazon EC2 instances in different AZs or Amazon S3 buckets in different AWS Regions are examples of this. Using spares helps that dependency achieve a higher total availability to support the workload’s availability goals.
Rule 5
Use sparing to increase the availability of dependencies in a workload.
However, sparing comes at a cost. Each additional spare costs the same as the original module, driving cost at least linearly. Building a workload that can use spares also increases its complexity. It must know how to identify dependency failure, weight work away from it to a healthy resource, and manage overall capacity of the workload.
Redundancy is an optimization problem. Too few spares, and the workload can fail more frequently than desired, too many spares and the workload costs too much to run. There is a threshold at which adding more spares will cost more than the additional availability they achieve warrants.
Using our general availability with spares formula, Equation (7), for a subsystem that has a 99.5% availability, with two spares the workload’s availability is A ≈ 1 − (1)(1−.995)3 = 99.9999875% (approximately 3.94 seconds of downtime a year), and with 10 spares we get A ≈ 1 − (1)(1−.995)11 = 25.5 9′s (the approximate downtime would be 1.26252 × 10−15ms per year, effectively 0). In comparing these two workloads, we've incurred a 5X increase in the cost of sparing to achieve four seconds less downtime a year. For most workloads, the increase in cost would be unwarranted for this increase in availability. The following figure shows this relationship.

Diminishing returns from increased sparing
At three spares and beyond, the result is fractions of a second of expected downtime a year, meaning that after this point you reach the area of diminishing returns. There might be an urge to “just add more” to achieve higher levels of availability, but in reality, the cost benefit disappears very quickly. Using more than three spares does not provide material, noticeable gain for almost all workloads when the subsystem itself has at least a 99% availability.
Rule 6
There is an upper bound to the cost efficiency of sparing. Utilize the fewest spares necessary to achieve the required availability.
You should consider the unit of failure when selecting the correct number of spares. For example, let's examine a workload that requires 10 EC2 instances to handle peak capacity and they are deployed in a single AZ.
Because AZs are designed to be fault isolation boundaries, the unit of failure is not only a single EC2 instance, because an entire AZ worth of EC2 instances can fail together. In this case, you will want to add redundancy with another AZ, deploying 10 additional EC2 instances to handle the load in case of an AZ failure, for a total of 20 EC2 instances (following the pattern of static stability).
While this appears to be 10 spare EC2 instances, it is really just a single spare AZ, so we haven't exceeded the point of diminishing returns. However, you can be even more cost efficient while also increasing your availability by utilizing three AZs and deploying five EC2 instances per AZ.
This provides one spare AZ with a total of 15 EC2 instances (versus two AZs with 20 instances), still providing the required 10 total instances to serve peak capacity during an event impacting a single AZ. Thus, you should build in sparing to be fault tolerant across all fault isolation boundaries used by the workload (instance, cell, AZ, and Region).
