Homogeneous data ingestion patterns
Homogeneous relational data ingestion
To build a Modern Data architecture, one of the most common scenarios is where you must move relational data from on-premises to the AWS Cloud. This section focuses on structured relational data where the source may be any relational database, such as Oracle, SQL Server, PostgreSQL, or MySQL and the target relational database engine is also the same. The target databases can be hosted either on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon Relational Database Service (Amazon RDS). The following use cases apply when ingesting relational data in a homogeneous pattern:
-
Migrating on-premises relational database or a portion of a database to AWS Cloud. This may be a one-time activity, with some data sync requirements till the cutover happens.
-
Continuous ingestion of relational data to keep a copy of the data in the cloud for reporting, analytics, or integration purposes.
Some of the most common challenges when migrating relational data from on-premises environments is the size of the data, available bandwidth of the network between on- premises and cloud, and downtime requirements. With a broad breadth of tools and options available to solve these challenges, it can be difficult for a migration team to sift through these options. This section addresses ways to overcome those challenges.
Moving from on-premises relational databases to databases hosted on Amazon EC2 instances and Amazon RDS
The volume of the data and the type of target (that is, Amazon EC2 or Amazon RDS) can affect the overall planning of data movement. Understanding the target type becomes critical as you can approach an Amazon EC2 target just like a server in-house and use the same tools that were used while moving data from on-premises to on-premises. The exception to this scenario is thinking about network connectivity between on-premises and the AWS Cloud. Because you cannot access the operating system (OS) layer of the server hosting the Amazon RDS instance, not all data ingestion tools will work as is. Therefore, it requires careful selection of the ingestion toolset. The following section addresses these ingestion tools.
Initial bulk ingestion tools
Oracle Database as a source and a target
-
Oracle SQL Developer is a graphical Java tool distributed free of charge by Oracle. It is best suited for smaller sized databases. Use this tool if the data size is up to 200 MB. Use the Database Copy command from the Tools menu to copy data from the source database to the target database. The target database can be either Amazon EC2 or Amazon RDS. With any Oracle native tools, make sure to check the database version compatibility especially when moving from a higher to a lower version of the database.
-
Oracle Export and Import utilities help you migrate databases that are smaller than 10 GB and don’t include binary float and double data types. The import process creates the schema objects, so you don’t have to run a script to create them beforehand. This makes the process well-suited for databases that have a large number of small tables. You can use this tool for both Amazon RDS for Oracle and Oracle databases on Amazon EC2.
-
Oracle Data Pump is a long-term replacement for the Oracle Export/Import utilities. You can use Oracle Data Pump for any size database. Up to 20 TB of the data can be ingested using Oracle Data Pump. The target database can be either Amazon EC2 or Amazon RDS.
-
AWS Database Migration Service
(AWS DMS) is a managed service that helps you move data to and from AWS easily and securely. AWS DMS supports most commercial and open-source databases, and facilitates both homogeneous and heterogeneous migrations. AWS DMS offers both one-time full database copy and change data capture (CDC) technology to keep the source and target databases in sync and to minimize downtime during a migration. There is no limit to the source database size. For more information how to create a DMS task, refer to Creating a task. -
Oracle GoldenGate is a tool for replicating data between a source database and one or more destination databases with minimal downtime. You can use it to build high availability architectures, and to perform real-time data integration, transactional change data capture (CDC), replication in heterogeneous environments, and continuous data replication. There is no limit to the source database size.
-
Oracle Data Guard provides a set of services for creating, maintaining, monitoring, and managing Oracle standby databases. You can migrate your entire Oracle database from on-premises to Amazon EC2 with minimal downtime by using Oracle Recovery Manager (RMAN) and Oracle Data Guard. With RMAN, you restore your database to the target standby database on Amazon EC2, using either backup/restore or the duplicate database method. You then configure the target database as a physical standby database with Oracle Data Guard, allowing all the transaction/redo data changes from the primary on- premises database to the standby database. There is no limit to the source database size.
-
AWS Application Migration Service (AWS MGN)– is a highly automated lift- and-shift (rehost) solution that simplifies, expedites, and reduces the cost of migrating applications to AWS. It enables companies to lift-and-shift a large number of physical, virtual, or cloud servers without compatibility issues, performance disruption, or long cutover windows. MGN replicates source servers into your AWS account. When you’re ready, it automatically converts and launches your servers on AWS so you can quickly benefit from the cost savings, productivity, resilience, and agility of the Cloud. Once your applications are running on AWS, you can leverage AWS services and capabilities to quickly and easily re-platform or refactor those applications – which makes lift-and-shift a fast route to modernization.
For more prescriptive guidance, refer to Migrating Oracle databases to the AWS Cloud.
Microsoft SQL Server Database as a source and a target
-
Native SQL Server backup/restore - Using native backup (*.bak) files is the simplest way to back up and restore SQL Server databases. You can use this method to migrate databases to or from Amazon RDS. You can back up and restore single databases instead of entire database (DB) instances. You can also move databases between Amazon RDS for SQL Server DB instances. When you use Amazon RDS, you can store and transfer backup files in Amazon Simple Storage Service (Amazon S3), for an added layer of protection for disaster recovery. You can use this process to back up and restore SQL Server databases to Amazon EC2 as well (refer to the following diagram).
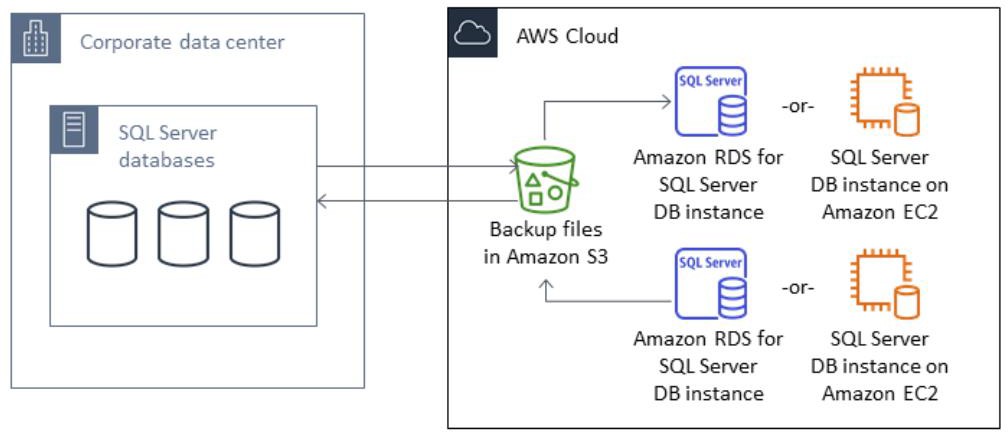
Microsoft SQL Server to Amazon RDS or Amazon EC2
-
Database mirroring — You can use database mirroring to set up a hybrid cloud environment for your SQL Server databases. This option requires SQL Server Enterprise edition. In this scenario, your principal SQL Server database runs on- premises, and you create a warm standby solution in the cloud. You replicate your data asynchronously, and perform a manual failover when you’re ready for cutover.
-
Always On availability groups — SQL Server Always On availability groups is an advanced, enterprise-level feature to provide high availability and disaster recovery solutions. This feature is available if you are using SQL Server 2012 and later versions. You can also use an Always On availability group to migrate your on-premises SQL Server databases to Amazon EC2 on AWS. This approach enables you to migrate your databases either with downtime or with minimal downtime.
-
Distributed availability groups — A distributed availability group spans two separate availability groups. You can think of it as an availability group of availability groups. The underlying availability groups are configured on two different Windows Server Fail over Clustering (WSFC) clusters. The availability groups that participate in a distributed availability group do not need to share the same location. They can be physical or virtual systems. The availability groups in a distributed availability group don’t have to run the same version of SQL Server. The target DB instance can run a later version of SQL Server than the source DB instance.
-
AWS Snowball Edge
- You can use AWS Snowball Edge to migrate very large databases (up to 80 TB in size). Any type of source relational database can use this method when the database size is very large. Snowball has a 10 Gb Ethernet port that you plug into your on-premises server and place all database backups or data on the Snowball device. After the data is copied to Snowball, you send the appliance to AWS for placement in your designated S3 bucket. Data copied to Snowball Edge is automatically encrypted. You can then download the backups from Amazon S3 and restore them on SQL Server on an Amazon EC2 instance, or run the rds_restore_database stored procedure to restore the database to Amazon RDS. You can also use AWS Snowcone for databases up to 8 TB in size. -
AWS DMS – Apart from the above tools, AWS Database Migration Service (AWS DMS) can be used to migrate initial bulk and/or change data capture as well.
For more prescriptive guidance, refer to Homogeneous database migration for SQL Server.
PostgreSQL Database as a source and a target
-
Native PostgreSQL tools —
pg_dump/pg_restore- database migration tools can be used under the following conditions:
-
You have a homogeneous migration, where you are migrating from a database with the same database engine as the target database.
-
You are migrating an entire database.
-
The native tools allow you to migrate your system with minimal downtime.
-
The pg_dump utility uses the
COPYcommand to create a schema and data dump of a PostgreSQL database. The dump script generated bypg_dumploads data into a database with the same name and recreates the tables, indexes, and foreign keys. You can use thepg_restorecommand and the-dparameter to restore the data to a database with a different name. -
AWS DMS
– If native database toolsets cannot be used, performing a database migration using AWS DMS is the best approach. AWS DMS can migrate databases without downtime and, for many database engines, continue ongoing replication until you are ready to switch over to the target database.
For more prescriptive guidance, refer to Importing data into PostgreSQL on Amazon RDS.
MySQL/MariaDB Database as a source and a target
-
Native MySQL tools - mysqldbcopy and mysqldump — You can also import data from an existing MySQL or MariaDB database to a MySQL or MariaDB DB instance. You do so by copying the database with mysqldump
and piping it directly into the MySQL or MariaDB DB instance. The mysqldump command-line utility is commonly used to make backups and transfer data from one MySQL or MariaDB server to another. This utility is included with MySQL and MariaDB client software. -
AWS DMS – You can use AWS DMS as well for the initial ingestion.
Change Data Capture (CDC) tools
To read ongoing changes from the source database, AWS DMS uses engine-specific API actions to read changes from the source engine's transaction logs. The following examples provide more details on how AWS DMS does these reads:
-
For Oracle, AWS DMS uses either the Oracle LogMiner API or binary reader API (
bfileAPI) to read ongoing changes. AWS DMS reads ongoing changes from the online or archive redo logs based on the system change number (SCN). -
For Microsoft SQL Server, AWS DMS uses MS-Replication or MS-CDC to write information to the SQL Server transaction log. It then uses the
fn_dblog()orfn_dump_dblog()function in SQL Server to read the changes in the transaction log based on the log sequence number (LSN). -
For MySQL, AWS DMS reads changes from the row-based binary logs (binlogs) and migrates those changes to the target.
-
For PostgreSQL, AWS DMS sets up logical replication slots and uses the test_decoding plugin to read changes from the source and migrate them to the target.
-
For Amazon RDS as a source, we recommend ensuring that backups are enabled to set up CDC. We also recommend ensuring that the source database is configured to retain change logs for a sufficient time—24 hours is usually enough.
For more prescriptive guidance, refer to Creating tasks for ongoing replication using AWS DMS.
Read-only workloads strategy for a database hosted on an Amazon EC2 instance and Amazon RDS
Every commercial vendor provides native tool sets to achieve read-only standby databases. Common examples include Oracle Active Data guard, Oracle GoldenGate, MS SQL Server Always on availability groups, Hot Standby for PostgreSQL and MySQL. Refer to vendor specific documentation if you are interested in pursuing read- only native scenarios on an Amazon EC2 instance.
Amazon RDS Read Replicas
For the MySQL, MariaDB, PostgreSQL, Oracle, and MS SQL Server database engines, Amazon RDS creates a second DB instance using a snapshot of the source DB instance. It then uses the engines' native asynchronous replication to update the read replica whenever there is a change to the source DB instance. The read replica operates as a DB instance that allows only read-only connections; applications can connect to a read replica just as they would to any DB instance. Amazon RDS replicates all databases in the source DB instance. Check vendor specific licensing before using the read replicas feature in Amazon RDS.

Common OLTP and AWS read replica scenario
Homogeneous data files ingestion
Many organizations use structured or semi-structured files formats to store data. These formats include structured files like CSV, Flat Files, Parquet, and Avro, or semi- structured files like JSON. These formats are also common in the Modern Data architecture and produced as outputs from an existing application or database storage, from processing in big data systems, or from data transfer solutions. Data engineers and developers are already familiar with these formats and use them in building systems for data migration solutions. When data is loaded into the data lake from various source systems, known as an outside-in approach, it may initially be stored as- is, before it is transformed into a standardized format into the data lake.
Or, the files may be transformed into the preferred format when loaded into the data lake. For movement of the data within the Modern Data architecture, known as inside-out use cases, the data lake processing engine outputs data for loading into purpose-built databases for scenarios like machine learning, reporting, business intelligence, and more. In peripheral data movement scenarios, where connection between data sources cannot be established, the data in extracted in common structured formats, placed in S3 storage, and used as intermediary for ETL operation.
Depending upon the use case, they could be classified as homogeneous or heterogeneous data ingestion. When they are ingested into data lake in as-is format, the classification is homogeneous. While if the format is changed or data destination is anything other than file or object storage, it is classified as heterogeneous ingestion. Data ingestions are usually completed as batch processes and may or may not involve any transformations. Further data ingestion mechanisms may also depend upon the slice of data received (for example, delta, full copy).
This section covers the pattern where the format of the files is not changed from its source, nor is any transformation applied when the files are being ingested. This scenario is a fairly common outside-in data movement pattern. This pattern is used for populating a so-called landing area in the data lake where all of the original copies of the ingested data are kept.
If the ingestion must be done only one time, which could be the use case for migration of an on-prem big-data or analytics systems to AWS or a one-off bulk ingestion job, then depending upon the size of the data, the data can be ingested over the wire or using the Snow family of devices.
These options are used when no transformations are required while ingesting the data.
If you determine that the bandwidth you have over the wire is sufficient and data size manageable to meet the SLAs, then following set of tools can be considered for one time or continuous ingestion of files. Note that you need to have the right connectivity between your data center and AWS setup using options such as AWS Direct Connect. For all available connectivity options, refer to the Amazon Virtual Private Cloud Connectivity Options whitepaper.
The following tools can cater to both one-time or continuous file ingestion needs, with some tools catering to other uses cases around backup or disaster recovery (DR) as well.
Integrating on-premises data processing platforms
AWS Storage Gateway
File Gateway can be deployed either as a virtual or hardware appliance. It enables for you to present a NFS such as Server Message Block (SMB) in your on-premises environment, which interfaces with Amazon S3. In Amazon S3, File Gateway preserves file metadata, such as permissions and timestamps for objects it stores in Amazon S3.

File Gateway architecture illustration
Data synchronization between on-premises data platforms and AWS
AWS DataSync
For details on how AWS DataSync can be used to transfer files
from on-premises to AWS securely, refer to
AWS re:Invent recap: Quick and secure data migrations using AWS
DataSync
DataSync provides built-in security capabilities such as encryption of data in-transit, and data integrity verification in-transit and at-rest. It optimizes use of network bandwidth, and automatically recovers from network connectivity failures. In addition, DataSync provides control and monitoring capabilities such as data transfer scheduling and granular visibility into the transfer process through Amazon CloudWatch metrics, logs, and events.
DataSync can copy data between Network File System (NFS) shares, Server Message Block (SMB) shares, self-managed object storage and Amazon Simple Storage Service (Amazon S3) buckets.
It’s simple to use. You deploy the DataSync agent as a virtual
appliance in a network that has access to AWS, where you define
your source, target, and transfer options per transfer task. It
allows for simplified data transfers from your SMB and NFS file
shares, and self-managed object storage, directly to any of the
Amazon S3 storage classes

AWS DataSync architecture
Data synchronization between on-premises environments and AWS
The
AWS Transfer Family
The AWS Transfer Family supports common user authentication systems, including Microsoft Active Directory and Lightweight Directory Access Protocol (LDAP).
Alternatively, you can also choose to store and manage users’ credentials directly within the service. By connecting your existing identity provider to the AWS Transfer Family service, you assure that your external users continue to have the correct, secure level of access to your data resources without disruption.
The AWS Transfer Family enables seamless migration by allowing you to import host keys, use static IP addresses, and use existing hostnames for your servers. With these features, user scripts and applications that use your existing file transfer systems continue working without changes.
AWS Transfer Family is simple to use. You can deploy an AWS Transfer for SFTP endpoint in minutes with a few clicks. Using the service, you simply consume a managed file transfer endpoint from the AWS Transfer Family, configure your users and then configure an Amazon S3 bucket to use as your storage location.
Data copy between on-premises environments and AWS
Additionally, Amazon S3 natively supports
DistCP
hadoop distcp hdfs://source-folder s3a://destination-bucket
For continued file ingestion, you can use a scheduler, such as cron jobs.
Programmatic data transfer using APIs and SDKs
You can also use the Amazon S3 REST APIs using AWS CLI or use your favorite programming languages with AWS SDKs to transfer the files into Amazon S3. Again, you will have to depend upon the schedulers available on the source systems to automate continuous ingestion. Note that the AWS CLI includes two namespaces for S3 – s3 and s3api. The s3 namespace includes the common commands for interfacing with S3, whereas s3api includes a more advanced set of commands. Some of the syntax is different between these two APIs.
Transfer of large data sets from on-premises environments into AWS
If you are dealing with large amounts of data, from terabytes to
even exabytes, then ingesting over the wire may not be ideal. In
this scenario, you can use the
AWS Snow
Family
The AWS Snow Family, comprising AWS Snowcone, AWS Snowball, and AWS Snowmobile, offers a number of physical devices and capacity points. For a feature comparison of each device, refer to AWS Snow Family. When choosing a particular member of the AWS Snow Family, it is important to consider not only the data size but also the supported network interfaces and speeds, device size, portability, job lifetime, and supported APIs. Snow Family devices are owned and managed by AWS and integrate with AWS security, monitoring, storage management, and computing capabilities.
