调整 Aurora PostgreSQL 的内存参数
在 Amazon Aurora PostgreSQL 中,您可以使用多个参数来控制用于各种处理任务的内存量。如果任务占用的内存超过为给定参数设置的内存量,Aurora PostgreSQL 会使用其他资源进行处理,例如写入磁盘。这可能会导致您的 Aurora PostgreSQL 数据库集群变慢或可能停止,并出现内存不足错误。
每个内存参数的原定设置通常可以处理其预期的处理任务。但是,您也可以调整 Aurora PostgreSQL 数据库集群 的内存相关参数。进行此调整是为了确保分配足够的内存来处理您的特定工作负载。
在下文中,您可以了解有关控制内存管理的参数的信息。您还可以学习如何评估内存利用率。
检查和设置参数值
您可以设置的用于管理内存和评估 Aurora PostgreSQL 数据库集群的内存使用情况的参数包括以下各项:
work_mem– 指定 Aurora PostgreSQL 数据库集群在写入临时磁盘文件之前用于内部排序操作和哈希表的内存量。log_temp_files– 记录临时文件创建、文件名和大小。启用此参数后,将为创建的每个临时文件存储一个日志条目。启用此参数可查看您的 Aurora PostgreSQL 数据库集群需要写入磁盘的频率。收集了有关 Aurora PostgreSQL 数据库集群的临时文件生成的信息后,再次将其关闭,以避免过多的日志记录。logical_decoding_work_mem– 指定每个内部重新排序缓冲区在溢出到磁盘之前要使用的内存量(以千字节为单位)。此内存用于逻辑解码,这是用于创建副本的过程。此过程是通过将数据从预写日志(WAL)文件转换为目标所需的逻辑流输出来完成的。此参数的值会创建单个缓冲区,其大小相当于为每个复制连接指定的大小。原定设置情况下,此值为 65536KB。填满该缓冲区后,多余的部分将作为文件写入到磁盘。为了最大限度地减少磁盘活动,可以将该参数的值设置为远高于
work_mem的值。
这些都是动态参数,因此您可以针对当前会话更改它们。为此,请通过 psql 并使用 SET 语句连接到 Aurora PostgreSQL 数据库集群,如下所示。
SET parameter_name TO parameter_value;会话设置只在会话持续时间内有效。当会话结束时,该参数将恢复为其在数据库集群参数组 中的设置。在更改任何参数之前,首先通过查询 pg_settings 表检查当前值,如下所示。
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
例如,要查找 work_mem 参数的值,请连接到 Aurora PostgreSQL 数据库集群的写入器实例,并运行以下查询。
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
要更改参数设置以使其保持不变,需要使用自定义数据库集群参数组 。使用 SET 语句通过这些参数的不同值实施 Aurora PostgreSQL 数据库集群后,您可以创建一个自定义参数组并应用于 Aurora PostgreSQL 数据库集群 。有关更多信息,请参阅 Amazon Aurora 的参数组。
了解工作内存参数
工作内存参数(work_mem)指定 Aurora PostgreSQL 可用于处理复杂查询的最大内存量。复杂查询包括那些涉及排序或分组操作的查询,换句话说,使用以下子句的查询:
ORDER BY
DISTINCT
GROUP BY
JOIN(MERGE 和 HASH)
查询计划程序间接影响您的 Aurora PostgreSQL 数据库集群使用工作内存的方式。查询计划程序生成用于处理 SQL 语句的执行计划。给定的计划可能会将复杂的查询分解为多个可以并行运行的工作单元。在可能的情况下,Aurora PostgreSQL 在为每个并行进程写入磁盘之前,使用在 work_mem 参数中为每个会话指定的内存量。
多个数据库用户同时运行多个操作并且并行生成多个工作单元,可能会耗尽 Aurora PostgreSQL 数据库集群的已分配工作内存。这可能导致过多的临时文件创建和磁盘 I/O,或者更糟糕的是,它可能导致内存不足错误。
识别临时文件使用情况
每当处理查询所需的内存超过在 work_mem 参数中指定的值时,工作数据将卸载到磁盘上的临时文件中。通过开启 log_temp_files 参数,可以查看这种情况发生的频率。原定设置情况下,此参数处于禁用状态(设置为 -1)。要捕获所有临时文件信息,请将此参数设置为 0。将 log_temp_files 设置为任何其他正整数,以捕获等于或大于该数据量(以 KB 为单位)的文件的临时文件信息。在下图中,您可以看到一个来自 AWS 管理控制台的示例。
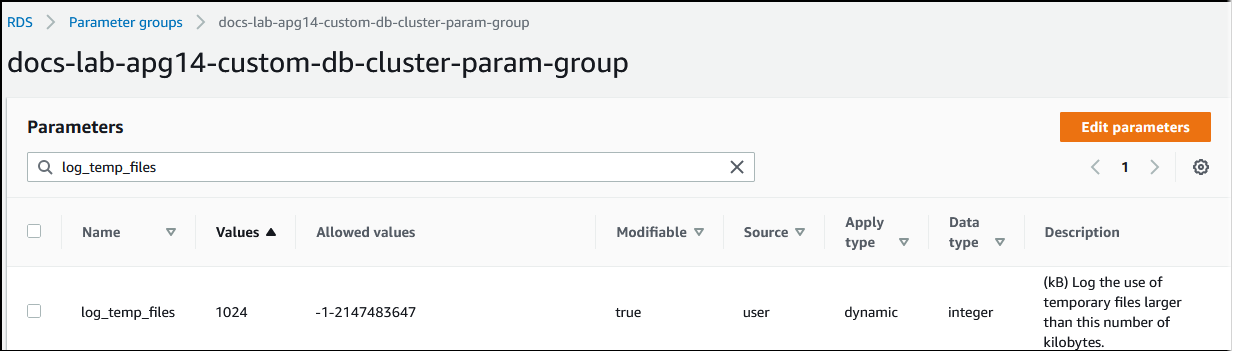
配置临时文件日志记录后,您可以使用自己的工作负载进行测试,看看您的工作内存设置是否足够。您还可以使用 pgbench 来模拟工作负载,pgbench 是一款来自 PostgreSQL 社区的简单基准测试应用程序。
以下示例通过创建运行测试所需的表和行来初始化 (-i) pgbench。在本例中,缩放系数(-s 50)在 labdb 数据库中的 pgbench_branches 表中创建 50 行,在 pgbench_tellers 表中创建 500 行,在 pgbench_accounts 表中创建 5000000 行。
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)初始化环境后,可以针对特定时间(-T)和客户端数量(-c)运行基准测试。此示例还使用 -d 选项,以在 Aurora PostgreSQL 数据库集群处理事务时输出调试信息。
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
有关 pgbench 的更多信息,请参阅 PostgreSQL 文档中的 pgbench
您可以使用 psql 元命令(\d)列出 pgbench 创建的表、视图和索引等关系。
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
如输出中所示,pgbench_accounts 表是按 aid 列编制索引的。为确保此下一个查询使用工作内存,请查询任何非索引列,如以下示例中所示的列。
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
检查日志中是否有临时文件。为此,请打开 AWS 管理控制台,选择 Aurora PostgreSQL 数据库集群实例,然后选择 Logs & Events(日志和事件)选项卡。在控制台中查看这些日志,或下载以供进一步分析。如下图所示,处理查询所需的临时文件的大小表明,您应该考虑增加为 work_mem 参数指定的数量。
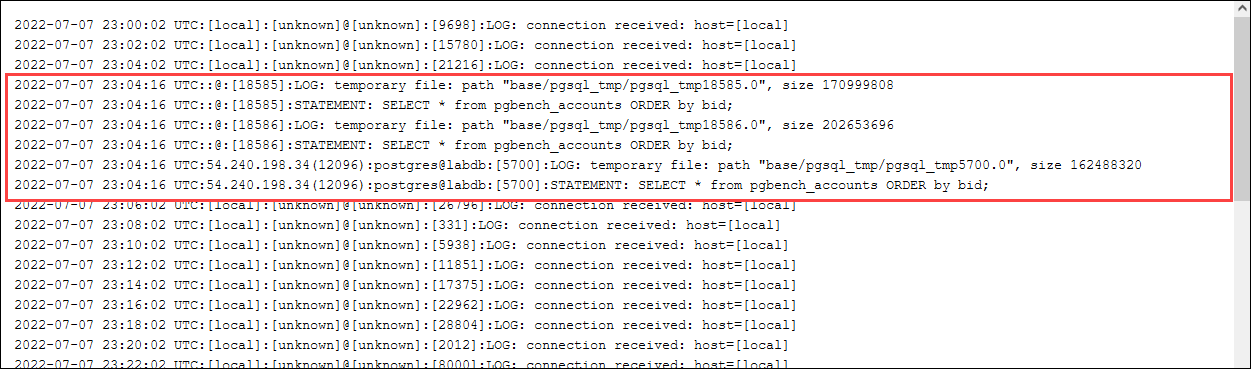
您可以根据您的运营需求为个人和团体配置不同的参数。例如,可以针对名为 dev_team 的角色将 work_mem 参数设置为 8 GB。
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
对 work_mem 使用此设置,将向作为 dev_team 角色成员的任何角色分配最多 8 GB 的工作内存。
使用索引缩短响应时间
如果查询返回结果的时间过长,则可以验证索引是否按预期使用。首先,打开 psql 元命令 \timing,如下所示。
postgres=>\timing on
开启计时后,使用简单的 SELECT 语句。
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
如输出所示,此查询仅用 3 秒就完成了。要缩短响应时间,请为 pgbench_accounts 创建索引,如下所示。
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
重新运行查询,注意响应时间更快。在此示例中,查询的完成速度快了大约 5 倍,大约需要半秒钟。
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
调整工作内存以进行逻辑解码
自从在 PostgreSQL 版本 10 中引入以来,逻辑复制已在所有版本的 Aurora PostgreSQL 中可用。配置逻辑复制时,还可以设置 logical_decoding_work_mem 参数,以指定逻辑解码过程可用于解码和流式传输过程的内存量。
在逻辑解码期间,预写日志(WAL)记录转换为 SQL 语句,然后这些语句将发送到另一个目标以用于逻辑复制或其他任务。当事务写入 WAL 并随后进行转换时,整个事务必须符合为 logical_decoding_work_mem 指定的值。原定设置情况下,该参数设置为 65536KB。任何溢出都将写入磁盘。这意味着,必须先从磁盘中重新读取溢出的数据,然后才能将其发送到目的地,从而减慢了整个过程。
您可以使用 aurora_stat_file 函数评估在特定时间点当前工作负载中的事务溢出量,如下例所示。
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
此查询返回调用该查询时 Aurora PostgreSQL 数据库集群上溢出文件的数量和大小。运行时间较长的工作负载在磁盘上可能没有任何溢出文件。要分析长时间运行的工作负载,我们建议您创建一个表,以便在工作负载运行时捕获溢出文件信息。您可以按如下所示创建表。
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
要查看在逻辑复制期间如何使用溢出文件,请设置发布者和订阅者,然后开始简单复制。有关更多信息,请参阅 为 Aurora PostgreSQL 数据库集群设置逻辑复制。随着复制进行,您可以创建一个任务以从 aurora_stat_file() 溢出文件函数中捕获结果集,如下所示。
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
使用以下 psql 命令每秒运行一次任务。
\watch 0.5
在任务运行时,从另一个 psql 会话连接到写入器实例。使用以下一系列语句运行超出内存配置并导致 Aurora PostgreSQL 创建溢出文件的工作负载。
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
完成这些语句可能需要几分钟时间。完成后,同时按下 Ctrl 键和 C 键以停止监控功能。然后,使用以下命令创建一个表,以保存有关 Aurora PostgreSQL 数据库集群的溢出文件使用情况的信息。
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
输出显示,运行该示例创建了五个使用了 611MB 内存的溢出文件。为了避免写入磁盘,建议将 logical_decoding_work_mem 参数设置为下一个最大内存大小 1024。
