向源 Aurora 数据库集群中添加数据并查询数据
要完成创建将数据从 Amazon Aurora 复制到 Amazon Redshift 的零 ETL 集成,您必须在目标目的地中创建数据库。
要连接 Amazon Redshift,请连接到您的 Amazon Redshift 集群或工作组,并创建一个引用集成标识符的数据库。然后,您可以向源 Aurora 数据库集群中添加数据,并在 Amazon Redshift 或 Amazon SageMaker 中查看复制的数据。
主题
创建目标数据库
在开始将数据复制到 Amazon Redshift 中之前,创建集成后,您必须在目标数据仓库中创建一个数据库。此数据库必须包含对集成标识符的引用。您可以使用 Amazon Redshift 控制台或查询编辑器 v2 来创建数据库。
有关创建目标数据库的说明,请参阅在 Amazon Redshift 中创建目标数据库。
向源数据库集群中添加数据
在配置集成后,可以使用要复制到数据仓库中的数据填充源 Aurora 数据库集群。
注意
Amazon Aurora 与目标分析仓库中的数据类型存在差异。有关数据类型映射的表,请参阅Aurora 和 Amazon Redshift 数据库之间的数据类型差异。
首先,使用您选择的 MySQL 或 PostgreSQL 客户端连接到源数据库集群。有关说明,请参阅。连接到 Amazon Aurora 数据库集群
然后,创建一个表并插入一行示例数据。
重要
确保该表有主键。否则,它无法复制到目标数据仓库。
pg_dump 和 pg_restore PostgreSQL 实用程序最初创建没有主键的表,然后添加主键。如果您使用其中一个实用程序,我们建议您先创建一个架构,然后在单独的命令中加载数据。
MySQL
以下示例使用 MySQL Workbench 实用程序
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
PostgreSQL
以下示例使用 psql PostgreSQL 交互式终端。连接到集群时,请包括您在创建集成时指定的命名数据库。
psql -hmycluster.cluster-123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
在 Amazon Redshift 中查询您的 Aurora 数据
将数据添加到 Aurora 数据库集群后,数据会复制到目标数据库并准备好供查询。
查询复制的数据
-
导航到 Amazon Redshift 控制台,然后从左侧导航窗格中选择查询编辑器 v2。
-
连接到您的集群或工作组,然后从下拉菜单中选择您通过集成创建的目标数据库(本示例中为 destination_database)。有关创建目标数据库的说明,请参阅在 Amazon Redshift 中创建目标数据库。
-
使用 SELECT 语句来查询您的数据。在本例中,您可以运行以下命令,从您在源 Aurora 数据库集群中创建的表中选择所有数据:
SELECT * frommy_db."books_table";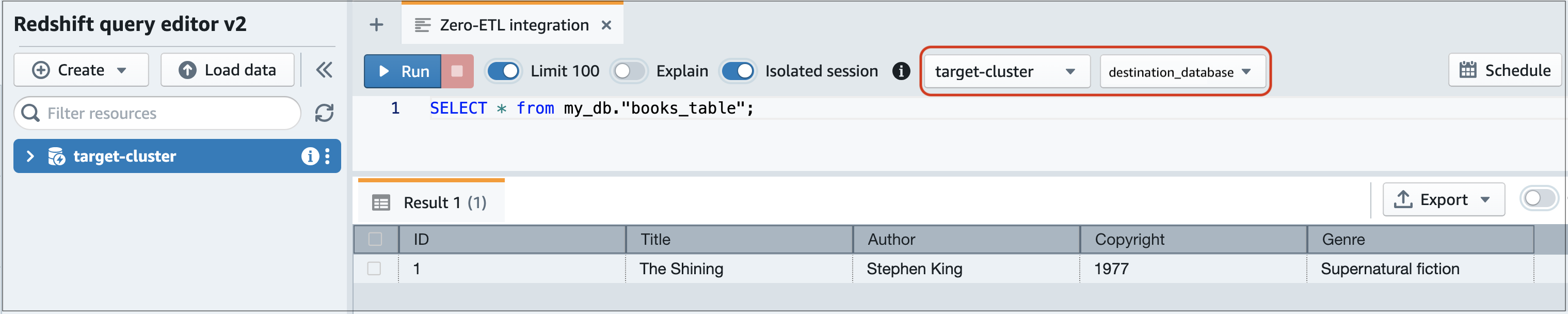
-
my_db -
books_table
-
也可以使用命令行客户端查询数据。例如:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
注意
为了区分大小写,请对架构、表和列名使用双引号(" ")。有关更多信息,请参阅 enable_case_sensitive_identifier。
Aurora 和 Amazon Redshift 数据库之间的数据类型差异
下面的表显示 Aurora MySQL 和 Aurora PostgreSQL 数据类型与相应目标数据类型的映射。Amazon Aurora 目前仅支持将这些数据类型用于零 ETL 集成。
如果源数据库集群中的表包含不受支持的数据类型,则该表将不同步并且目的地目标无法使用该表。从源到目标的流式传输仍在继续,但数据类型不受支持的表不可用。要修复该表并使其在目标目的地中可用,您必须手动恢复重大更改,然后通过运行 ALTER DATABASE...INTEGRATION
REFRESH 来刷新集成。
注意
您无法刷新与 Amazon SageMaker 智能湖仓的零 ETL 集成。而是应删除并尝试重新创建集成。
Aurora MySQL
| Aurora MySQL 数据类型 | 目标数据类型 | 说明 | 限制 |
|---|---|---|---|
| INT | INTEGER | 有符号的四字节整数 | 无 |
| SMALLINT | SMALLINT | 有符号的二字节整数 | 无 |
| TINYINT | SMALLINT | 有符号的二字节整数 | 无 |
| MEDIUMINT | INTEGER | 有符号的四字节整数 | 无 |
| BIGINT | BIGINT | 有符号的八字节整数 | 无 |
| INT UNSIGNED | BIGINT | 有符号的八字节整数 | 无 |
| TINYINT UNSIGNED | SMALLINT | 有符号的二字节整数 | 无 |
| MEDIUMINT UNSIGNED | INTEGER | 有符号的四字节整数 | 无 |
| BIGINT UNSIGNED | DECIMAL(20,0) | 可选精度的精确数字 | 无 |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL (p,s) | 可选精度的精确数字 |
不支持精度大于 38 和比例大于 37 |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL (p,s) | 可选精度的精确数字 |
不支持精度大于 38 和比例大于 37 |
| FLOAT4/REAL | REAL | 单精度浮点数 | 无 |
| FLOAT4/REAL UNSIGNED | REAL | 单精度浮点数 | 无 |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | 双精度浮点数 | 无 |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | 双精度浮点数 | 无 |
| BIT(n) | VARBYTE(8) | 长度可变的二进制值 | 无 |
| BINARY(n) | VARBYTE(n) | 长度可变的二进制值 | 无 |
| VARBINARY (n) | VARBYTE(n) | 长度可变的二进制值 | 无 |
| CHAR (n) | VARCHAR (n) | 长度可变的字符串值 | 无 |
| VARCHAR (n) | VARCHAR (n) | 长度可变的字符串值 | 无 |
| TEXT | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| TINYTEXT | VARCHAR(255) | 长度可变、最多 255 个字符的字符串值 | 无 |
| MEDIUMTEXT | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| LONGTEXT | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| ENUM | VARCHAR(1020) | 长度可变、最多 1020 个字符的字符串值 | 无 |
| SET | VARCHAR(1020) | 长度可变、最多 1020 个字符的字符串值 | 无 |
| DATE | DATE | 日历日期(年、月、日) | 无 |
| DATETIME | TIMESTAMP | 日期和时间(没有时区) | 无 |
| TIMESTAMP(p) | TIMESTAMP | 日期和时间(没有时区) | 无 |
| TIME | VARCHAR(18) | 长度可变、最多 18 个字符的字符串值 | 无 |
| YEAR | VARCHAR(4) | 长度可变、最多 4 个字符的字符串值 | 无 |
| JSON | SUPER | 作为值的半结构化数据或文档 | 无 |
Aurora PostgreSQL
Aurora PostgreSQL 的零 ETL 集成不支持自定义数据类型或由扩展创建的数据类型。
| Aurora PostgreSQL 数据类型 | Amazon Redshift 数据类型 | 说明 | 限制 |
|---|---|---|---|
| 数组 | SUPER | 作为值的半结构化数据或文档 | 无 |
| bigint | BIGINT | 有符号的八字节整数 | 无 |
| bigserial | BIGINT | 有符号的八字节整数 | 无 |
| bit varying(n) | VARBYTE(n) | 长度可变、最多 16,777,216 字节的二进制值 | 无 |
| bit(n) | VARBYTE(n) | 长度可变、最多 16,777,216 字节的二进制值 | 无 |
| bit、bit varying | VARBYTE(16777216) | 长度可变、最多 16,777,216 字节的二进制值 | 无 |
| 布尔值 | BOOLEAN | 逻辑布尔值(true/false) | 无 |
| bytea | VARBYTE(16777216) | 长度可变、最多 16,777,216 字节的二进制值 | 无 |
| char(n) | CHAR (n) | 长度固定、最多 65,535 字节的字符串值 | 无 |
| char varying(n) | VARCHAR(65535) | 长度可变、最多 65,535 个字符的字符串值 | 无 |
| cid | BIGINT |
有符号的八字节整数 |
无 |
| cidr |
VARCHAR(19) |
长度可变、最多 19 个字符的字符串值 |
无 |
| date | DATE | 日历日期(年、月、日) |
不支持大于 294276 A.D. 的值 |
| double precision | DOUBLE PRECISION | 双精度浮点数 | 不完全支持亚正常值 |
|
gtsvector |
VARCHAR(65535) |
长度可变、最多 65535 个字符的字符串值 |
无 |
| inet |
VARCHAR(19) |
长度可变、最多 19 个字符的字符串值 |
无 |
| 整数 | INTEGER | 有符号的四字节整数 | 无 |
|
int2vector |
SUPER | 作为值的半结构化数据或文档。 | 无 |
| interval | INTERVAL | 持续时间 | 仅支持指定年至月或日至秒限定符的 INTERVAL 类型。 |
| json | SUPER | 作为值的半结构化数据或文档 | 无 |
| jsonb | SUPER | 作为值的半结构化数据或文档 | 无 |
| jsonpath | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
|
macaddr |
VARCHAR(17) | 长度可变、最多 17 个字符的字符串值 | 无 |
|
macaddr8 |
VARCHAR(23) | 长度可变、最多 23 个字符的字符串值 | 无 |
| money | DECIMAL(20,3) | 货币金额 | 无 |
| name | VARCHAR(64) | 长度可变、最多 64 个字符的字符串值 | 无 |
| numeric(p,s) | DECIMAL (p,s) | 用户定义的固定精度值 |
|
| oid | BIGINT | 有符号的八字节整数 | 无 |
| oidvector | SUPER | 作为值的半结构化数据或文档。 | 无 |
| pg_brin_bloom_summary | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| pg_dependencies | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| pg_lsn | VARCHAR(17) | 长度可变、最多 17 个字符的字符串值 | 无 |
| pg_mcv_list | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| pg_ndistinct | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| pg_node_tree | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| pg_snapshot | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| real | REAL | 单精度浮点数 | 不完全支持亚正常值 |
| refcursor | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| smallint | SMALLINT | 有符号的二字节整数 | 无 |
| smallserial | SMALLINT | 有符号的二字节整数 | 无 |
| Serial | INTEGER | 有符号的四字节整数 | 无 |
| 文本 | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| tid | VARCHAR(23) | 长度可变、最多 23 个字符的字符串值 | 无 |
| 不带时区的 time [(p)] | VARCHAR(19) | 长度可变、最多 19 个字符的字符串值 | 不支持 Infinity 和 -Infinity 值 |
| 有时区的 time [(p)] | VARCHAR(22) | 长度可变、最多 22 个字符的字符串值 | 不支持 Infinity 和 -Infinity 值 |
| 不带时区的 timestamp [(p)] | TIMESTAMP | 日期和时间(没有时区) |
|
| 有时区的 timestamp [(p)] | TIMESTAMPTZ | 日期和时间(有时区) |
|
| tsquery | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| tsvector | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| txid_snapshot | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
| uuid | VARCHAR(36) | 长度可变的 36 个字符的字符串 | 无 |
| xid | BIGINT | 有符号的八字节整数 | 无 |
| xid8 | DECIMAL(20, 0) | 固定精度小数 | 无 |
| xml | VARCHAR(65535) | 长度可变、最多 65535 个字符的字符串值 | 无 |
适用于 Aurora PostgreSQL 的 DDL 操作
Amazon Redshift 源自 PostgreSQL,由于具有共同的 PostgreSQL 架构,因此它与 Aurora PostgreSQL 共享多项功能。零 ETL 集成利用这些相似之处来简化从 Aurora PostgreSQL 到 Amazon Redshift 的数据复制,从而按名称映射数据库并利用共享的数据库、架构和表结构。
管理 Aurora PostgreSQL 零 ETL 集成时应考虑以下几点:
-
隔离是在数据库级别进行管理。
-
复制发生在数据库级别。
-
Aurora PostgreSQL 数据库按名称映射到 Amazon Redshift 数据库,如果原始 Redshift 数据库被重命名,则数据将流向相应的已重命名的数据库。
尽管 Amazon Redshift 和 Aurora PostgreSQL 有相似之处,但也存在重大差异。以下各节概述了 Amazon Redshift 系统对常见 DDL 操作的响应。
数据库操作
下表显示了系统对数据库 DDL 操作的响应。
| DDL 操作 | Redshift 系统响应 |
|---|---|
CREATE DATABASE |
无操作 |
DROP DATABASE |
Amazon Redshift 删除目标 Redshift 数据库中的所有数据。 |
RENAME DATABASE |
Amazon Redshift 会删除原始目标数据库中的所有数据,然后重新同步新目标数据库中的数据。如果新数据库不存在,您必须手动创建一个。有关说明,请参阅在 Amazon Redshift 中创建目标数据库。 |
架构操作
下表显示了系统对架构 DDL 操作的响应。
| DDL 操作 | Redshift 系统响应 |
|---|---|
CREATE SCHEMA |
无操作 |
DROP SCHEMA |
Amazon Redshift 会删除原始架构。 |
RENAME SCHEMA |
Amazon Redshift 会删除原始架构,然后重新同步新架构中的数据。 |
表操作
下表显示了系统对表 DDL 操作的响应。
| DDL 操作 | Redshift 系统响应 |
|---|---|
CREATE TABLE |
Amazon Redshift 会创建表。 某些操作会导致表创建失败,例如创建没有主键的表或执行声明式分区。有关更多信息,请参阅限制和Aurora 零 ETL 集成故障排除。 |
DROP TABLE |
Amazon Redshift 会删除表。 |
TRUNCATE TABLE |
Amazon Redshift 会截断表。 |
ALTER TABLE
(RENAME...) |
Amazon Redshift 会重命名表或列。 |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift 会删除原始架构中的表,然后重新同步新架构中的表。 |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift 会添加主键并重新同步表。 |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift 会向表中添加列。 |
ALTER TABLE (DROP
COLUMN) |
如果不是主键列,则 Amazon Redshift 会删除该列。否则,它会重新同步表。 |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
如果您将表更改为已记录,Amazon Redshift 会重新同步该表。如果您将表更改为未记录,Amazon Redshift 会删除该表。 |
