本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在中创建多服务器评估报告 AWS Schema Conversion Tool
要确定整体环境的最佳目标方向,请创建多服务器评估报告。
多服务器评估报告根据您为要评估的每个架构定义提供的输入来评估多台服务器。架构定义包含数据库服务器连接参数和每个架构的全名。评估每个架构后, AWS SCT 生成一份汇总的评估报告,用于跨多台服务器的数据库迁移。该报告显示了每个可能的迁移目标的估计复杂性。
您可以使用 AWS SCT 为以下源数据库和目标数据库创建多服务器评估报告。
| 源数据库 | 目标数据库 |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Azure SQL 数据库 |
Aurora MySQL、Aurora PostgreSQL、MySQL、PostgreSQL |
|
Azure Synapse Analytics |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 for z/OS |
Amazon Aurora MySQL 兼容版(Aurora MySQL)、 Amazon Aurora PostgreSQL 兼容版(Aurora PostgreSQL)、MySQL、PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL、Aurora PostgreSQL、MariaDB、MySQL、PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL、Aurora PostgreSQL、Amazon Redshift、适用于 Aurora PostgreSQL 的 Babelfish、MariaDB、Microsoft SQL Server、MySQL、PostgreSQL |
|
MySQL |
Aurora PostgreSQL、MySQL、PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL、Aurora PostgreSQL、Amazon Redshift、MariaDB、MySQL、Oracle、PostgreSQL |
|
PostgreSQL |
Aurora MySQL、Aurora PostgreSQL、MySQL、PostgreSQL |
|
SAP ASE |
Aurora MySQL、Aurora PostgreSQL、MariaDB、MySQL、PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
执行多服务器评估
使用以下步骤使用执行多服务器评估。 AWS SCT您无需在中创建新项目 AWS SCT 即可执行多服务器评估。在开始之前,请确保您已准备好包含数据库连接参数的逗号分隔值(CSV)文件。此外,请确保已安装所有必需的数据库驱动程序,并在 AWS SCT 设置中设置驱动程序的位置。有关更多信息,请参阅 正在安装 JDBC 驱动程序 AWS Schema Conversion Tool。
执行多服务器评估并创建汇总摘要报告
-
在中 AWS SCT,选择文件、新建多服务器评估。将打开新建多服务器评估对话框。
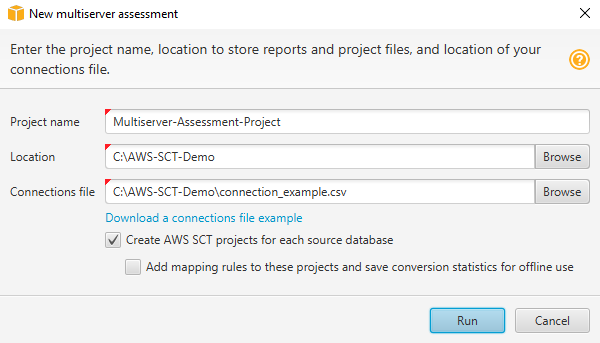
-
选择下载连接文件示例,下载带有数据库连接参数的 CSV 文件的空模板。
-
输入项目名称、位置(用于存储报告)和连接文件(CSV 文件)的值。
-
选择 “为每个源数据库创建 AWS SCT 项目”,以便在生成评估报告后自动创建迁移项目。
-
打开 “为每个源数据库创建 AWS SCT 项目” 后,您可以选择向这些项目添加映射规则并保存转化统计信息以供离线使用。在这种情况下, AWS SCT 将向每个项目添加映射规则,并将源数据库元数据保存在项目中。有关更多信息,请参阅 在中使用离线模式 AWS Schema Conversion Tool。
-
选择运行。
此时将出现一个进度条,指示数据库评估的进度。目标引擎的数量可能会影响评估运行时系统。
-
如果显示以下消息,请选择是:对所有数据库服务器进行全面分析可能需要一些时间。您要继续吗?
多服务器评估报告完成后,会出现一个显示完成的屏幕。
-
选择打开报告以查看汇总摘要评估报告。
默认情况下, AWS SCT 会为所有源数据库生成汇总报告,为源数据库中的每个架构名称生成详细的评估报告。有关更多信息,请参阅 查找和查看报告。
启用 “为每个源数据库创建 AWS SCT 项目” 选项后, AWS SCT 将为每个源数据库创建一个空项目。 AWS SCT 还会如前所述,创建评估报告。在分析了这些评估报告并为每个源数据库选择迁移目标之后,将目标数据库添加到这些空项目中。
启用 “向这些项目添加映射规则并保存转化统计数据以供离线使用” 选项,将为每个源数据库 AWS SCT 创建一个项目。这些项目包括以下信息:
源数据库和虚拟目标数据库平台。有关更多信息,请参阅 在 AWS Schema Conversion Tool 中映射到虚拟目标。
此源-目标对的映射规则。有关更多信息,请参阅 数据类型映射。
此源-目标对的数据库迁移评估报告。
源架构元数据,使您能够在离线模式下使用此 AWS SCT 项目。有关更多信息,请参阅 在中使用离线模式 AWS Schema Conversion Tool。
准备输入 CSV 文件
要提供连接参数作为多服务器评估报告的输入,请使用 CSV 文件,如以下示例中所示。
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
前面的示例使用分号分隔 Sales 数据库的两个架构名称。它还使用分号来分隔 Sales 数据库的两个目标数据库迁移平台。
此外,前面的示例使用 AWS Secrets Manager 连接到Customers数据库并使用 Windows 身份验证来连接到HR数据库。
您可以创建新的 CSV 文件或从 AWS SCT 中下载 CSV 文件的模板并填写所需信息。确保 CSV 文件的第一行包含与前面示例中所示相同的列名。
下载输入 CSV 文件的模板
开始 AWS SCT。
选择文件,然后选择新建多服务器评估。
选择下载连接文件示例。
确保您的 CSV 文件包含模板提供的以下值:
-
名称:帮助识别数据库的文本标签。 AWS SCT 在评估报告中显示此文本标签。
-
描述:一个可选值,您可以在其中提供有关数据库的其他信息。
-
Secret Manager 密钥:将您的数据库凭证存储在 AWS Secrets Manager中的密钥的名称。要使用 Secrets Manager,请确保将 AWS 个人资料存储在中 AWS SCT。有关更多信息,请参阅 AWS Secrets Manager 在中配置 AWS Schema Conversion Tool。
重要
AWS SCT 如果在输入文件中包含服务器 IP、端口、登录名和密码参数,则会忽略 S ecret Manager 密钥参数。
-
服务器 IP:源数据库服务器的域名服务(DNS)名称或 IP 地址。
-
端口:用于连接到源数据库服务器的端口。
-
服务名称:如果您使用服务名连接您的 Oracle 数据库,则为要连接的 Oracle 服务的名称。
-
数据库名称:数据库的名称。对于 Oracle 数据库,使用 Oracle 系统 ID(SID)。
-
BigQuery path — 源 BigQuery 数据库的服务帐号密钥文件的路径。有关创建此文件的更多信息,请参阅 BigQuery 作为来源的权限。
-
源引擎:源数据库的类型。使用下列值之一:
AZURE_MSSQL:适用于 Azure SQL 数据库。
AZURE_SYNAPSE:适用于 Azure Synapse Analytics 数据库。
用于数据库的 GOOGLE_BIGQUERY。 BigQuery
DB2适用于 IBM 数据库的 Db2 的 ZOS。 z/OS
DB2LUW 用于 IBM Db2 LUW 数据库。
GREENPLUM:适用于 Greenplum 数据库。
MSSQL:适用于 Microsoft SQL Server 数据库。
MYSQL:适用于 MySQL 数据库。
NETEZZA:适用于 Netezza 数据库。
ORACLE:适用于 Oracle 数据库。
POSTGRESQL:适用于 PostgreSQL 数据库。
REDSHIFT:适用于 Amazon Redshift 数据库
SNOWFLAKE:适用于 Snowflake 数据库。
SYBASE_ASE:适用于 SAP ASE 数据库。
TERADATA:适用于 Teradata 数据库。
VERTICA:适用于 Vertica 数据库。
-
架构名称:要包含在评估报告中的数据库架构的名称。
对于 Azure SQL 数据库、Azure Synapse Analytics BigQuery、Netezza、Sap ASE、Snowflake 和 SQL Server,请使用以下格式的架构名称:
db_name.schema_name将
db_name将
schema_name用双引号将包含点的数据库或架构名称括起来,如下所示:
"database.name"."schema.name"。使用分号分隔多个架构名称,如下所示:
Schema1;Schema2。数据库和架构名称区分大小写。
使用百分比(
%)作为通配符来替换数据库或架构名称中任意数量的任何符号。前面的示例使用百分比(%)作为通配符,将employees数据库中的所有架构包含在评估报告中。 -
使用 Windows 身份验证:如果您使用 Windows 身份验证连接到 Microsoft SQL Server 数据库,请输入 true。有关更多信息,请参阅 当将 Microsoft SQL Server 用作源时使用 Windows 身份验证。
-
登录名:用于连接到源数据库服务器的用户名。
-
密码:用于连接到源数据库服务器的密码。
-
使用 SSL:如果您使用安全套接字层 (SSL) 连接到源数据库,请输入 true。
-
信任存储 :用于 SSL 连接的信任存储。
-
密钥存储:用于 SSL 连接的密钥存储。
-
SSL 身份验证:如果您使用通过证书进行的 SSL 身份验证,请输入 true。
-
目标引擎:目标数据库平台。使用以下值在评估报告中指定一个或多个目标:
AURORA_MYSQL:适用于 Aurora MySQL 兼容数据库。
AURORA_POSTGRESQL:适用于 Aurora PostgreSQL 兼容数据库
BABELFISH:适用于 Aurora PostgreSQL 的 Babelfish 数据库。
MARIA_DB:适用于 MariaDB 数据库。
MSSQL:适用于 Microsoft SQL Server 数据库。
MYSQL:适用于 MySQL 数据库。
ORACLE:适用于 Oracle 数据库。
POSTGRESQL:适用于 PostgreSQL 数据库。
REDSHIFT:适用于 Amazon Redshift 数据库。
使用分号分隔多个目标,如下所示:
MYSQL;MARIA_DB。目标的数量会影响运行评估所需的时间。
查找和查看报告
多服务器评估生成两种类型的报告:
-
所有源数据库的汇总报告。
-
源数据库中每个架构名称的目标数据库的详细评估报告。
报告存储在您在新建多服务器评估对话框中为位置选择的目录中。
要访问详细报告,您可以浏览子目录,这些子目录按源数据库、架构名称和目标数据库引擎组织。
汇总报告分四列显示有关目标数据库转换复杂性的信息。这些列包含有关代码对象、存储对象、语法元素和转换复杂性的转换的信息。
以下示例显示了将两个 Oracle 数据库架构转换为适用于 PostgreSQL 的 Amazon RDS 的信息。

对于每个指定的其他目标数据库引擎,都会在报告中追加相同的四列。
有关如何阅读这些信息的详细信息,请参阅以下内容。
汇总评估报告的输出
中的聚合多服务器数据库迁移评估报告 AWS Schema Conversion Tool 是一个 CSV 文件,其中包含以下几列:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
要收集信息,请 AWS SCT 运行完整的评估报告,然后按架构汇总报告。
在报告中,以下三个字段显示了基于评估可能自动转换的百分比:
- 代码对象转化率%
-
架构中可以自动转换或只需最少更改 AWS SCT 即可转换的代码对象的百分比。代码对象包括过程、函数、视图等。
- 存储对象转换率%
-
SCT 可以自动转换或只需最少更改即可转换存储对象的百分比。存储对象包括表、索引、约束等。
- 语法元素转换率%
-
SCT 可以自动转换的语法元素的百分比。语法元素包括
SELECT、FROM、DELETE和JOIN子句等。
转换复杂度计算基于操作项的概念。操作项反映了源代码中发现的一种问题,在迁移到特定目标的过程中,您需要手动修复这些问题。一个操作项可以多次出现。
加权量表确定了执行迁移的复杂程度。数字 1 代表最低的复杂度,数字 10 代表最高的复杂度。
