本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用以下命令将数据从本地数据仓库迁移到 Amazon Redshift AWS Schema Conversion Tool
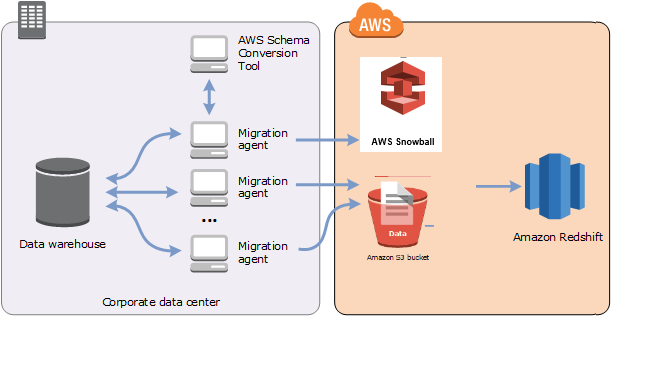
您可以使用 AWS SCT 代理从本地数据仓库中提取数据并将其迁移到 Amazon Redshift。代理会提取您的数据并将数据上传到 Amazon S3,或者如果要进行大规模迁移,则上传到 AWS Snowball Edge Edge 设备。然后,您可以使用 AWS SCT 代理将数据复制到亚马逊 Redshift。
或者,您可以使用 AWS Database Migration Service (AWS DMS) 将数据迁移到亚马逊 Redshift。 AWS DMS 的优点是支持持续复制(更改数据捕获)。但是,要提高数据迁移的速度,可以并行使用多个 AWS SCT 代理。根据我们的测试, AWS SCT 代理迁移数据的速度超过 AWS DMS 15-35%。速度的差异是由于数据压缩、支持并行迁移表分区以及不同的配置设置造成的。有关更多信息,请参阅将 Amazon Redshift 数据库用作 AWS Database Migration Service的目标。
Amazon S3 是一种存储和检索服务。要将数据元存储到 Amazon S3 中,请将要存储的文件上传到 Amazon S3 存储桶中。在上传文件时,您可以设置对象以及任何元数据的权限。
大规模迁移
大规模的数据迁移可能包括许多 TB 的信息,并且可能会因为网络性能和必须移动的数据量庞大而减慢。 AWS Snowball Edge Edge 是一项 AWS 服务,您可以使用 AWS自有设备将数据 faster-than-network快速传输到云端。一台 AWS Snowball Edge Edge 设备最多可以容纳 100 TB 的数据。它使用 256 位加密和行业标准的可信平台模块 (TPM),以确保您的数据既安全又完整 chain-of-custody。 AWS SCT 适用于边 AWS Snowball Edge 缘设备。
当您使用 AWS SCT 和 AWS Snowball Edge Edge 设备时,您可以分两个阶段迁移数据。首先,您可以使用 AWS SCT 在本地处理数据,然后将该数据移至 AWS Snowball Edge Edge 设备。然后,您可以 AWS 使用 AWS Snowball Edge Edge 流程将设备发送到,然后 AWS 自动将数据加载到 Amazon S3 存储桶中。接下来,当数据在 Amazon S3 上可用时,您可以使用将数据迁移 AWS SCT 到 Amazon Redshift。关闭时 AWS SCT ,数据提取代理可以在后台运行。
下图显示了支持的方案。
以下源数据仓库当前支持数据提取代理:
Azure Synapse Analytics
BigQuery
Greenplum 数据库(版本 4.3)
Microsoft SQL Server(版本 2008 及更高版本)
Netezza(版本 7.0.3 及更高版本)
Oracle(版本 10 及更高版本)
Snowflake(版本 3)
Teradata(版本 13 及更高版本)
Vertica(版本 7.2.2 及更高版本)
如果您需要符合联邦信息处理标准(FIPS)安全要求,则可以连接到 Amazon Redshift 的 FIPS 端点。FIPS 终端节点可在以下 AWS 区域使用:
美国东部(弗吉尼亚州北部)区域(redshift-fips.us-east-1.amazonaws.com)
美国东部(俄亥俄州)区域(redshift-fips.us-east-2.amazonaws.com)
美国西部(北加利福尼亚)区域(redshift-fips.us-west-1.amazonaws.com)
美国西部(俄勒冈州)区域(redshift-fips.us-west-2.amazonaws.com)
使用以下主题中的信息了解如何使用数据提取代理。
主题
使用数据提取代理的先决条件
在使用数据提取代理之前,请为 Amazon Redshift 用户添加作为目标的 Amazon Redshift 所需的权限。有关更多信息,请参阅 将 Amazon Redshift 作为目标的权限。
然后,存储 Amazon S3 存储桶信息并设置安全套接字层 (SSL) 信任和密钥存储。
Amazon S3 设置
当代理提取数据后,它们会将其上传到 Amazon S3 存储桶。在继续操作之前,您必须提供凭证才能连接到您的 AWS 账户和 Amazon S3 存储桶。您将凭证和存储桶信息存储在全局应用程序设置的配置文件中,然后将该配置文件与您的 AWS SCT 项目关联。如有必要,请选择全局设置即可创建新的配置文件。有关更多信息,请参阅 在中管理个人资料 AWS Schema Conversion Tool。
要将数据迁移到您的目标 Amazon Redshift 数据库, AWS SCT 数据提取代理需要获得代表您访问 Amazon S3 存储桶的权限。要提供此权限,请使用以下策略创建一个 AWS Identity and Access Management (IAM) 用户。
在上面示例中,请将 bucket_name111122223333:user/DataExtractionAgentName
假定 IAM 角色
为了提高安全性,您可以使用 AWS Identity and Access Management (IAM) 角色访问您的 Amazon S3 存储桶。为此,请在没有任何权限的情况下为数据提取代理创建一个 IAM 用户。然后,创建一个启用 Amazon S3 访问权限的 IAM 角色,并指定服务和可以担任此角色的用户列表。有关更多信息,请参阅《IAM 用户指南》中的 IAM 角色。
配置 IAM 角色以访问 Amazon S3 存储桶
-
创建新的 IAM 用户 对于用户凭证,请选择编程访问类型。
-
配置主机环境,以便您的数据提取代理可以扮演 AWS SCT 提供的角色。确保您在上一步中配置的用户允许数据提取代理使用凭证提供程序链。有关更多信息,请参阅《适用于 Java 的 AWS SDK 开发人员指南》中的使用凭证。
-
创建一个有 Amazon S3 存储桶访问权限的新 IAM 角色。
-
修改此角色的“信任”部分,以信任您之前创建的担任该角色的用户。在以下示例中,将
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
将此角色的信任部分修改为信任
redshift.amazonaws.com以担任该角色。{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
将此角色附加到 Amazon Redshift 集群。
现在,您可以在 AWS SCT中运行数据提取代理。
当您使用 IAM 角色代入时,数据迁移的工作方式如下。数据提取代理启动并使用凭证提供程序链获取用户凭证。接下来,在中创建数据迁移任务 AWS SCT,然后指定数据提取代理要担任的 IAM 角色,然后启动任务。 AWS Security Token Service (AWS STS) 生成用于访问 Amazon S3 的临时证书。数据提取代理使用这些凭证将数据上传到 Amazon S3。
然后,为 Amazon Redshift AWS SCT 提供 IAM 角色。反过来,亚马逊 Redshift 会从中获得访问亚马逊 S AWS STS 3 的新临时证书。Amazon Redshift 使用这些凭证将数据从 Amazon S3 复制到 Amazon Redshift 表。
安全设置
AWS Schema Conversion Tool 和提取代理可以通过安全套接字层 (SSL) 进行通信。要启用 SSL,请设置信任存储和密钥存储。
建立与提取代理的安全通信
-
启动 AWS Schema Conversion Tool.
-
打开设置菜单,然后选择全局设置。此时显示 Global settings 对话框。
-
选择安全性。
-
选择生成信任存储和密钥存储,或选择选择现有信任存储。
如果您选择生成信任存储和密钥存储,则可为信任存储和密钥存储指定名称和密码,并为生成的文件指定位置路径。您会在后面的步骤中用到这些文件。
如果选择选择现有信任存储,则为信任存储和密钥存储指定密码和文件名。您会在后面的步骤中用到这些文件。
-
指定信任存储和密钥存储后,请选择确定以关闭全局设置对话框。
配置数据提取代理环境
可以在一台主机上安装多个数据提取代理。但是,建议您在一台主机上运行一个数据提取代理。
要运行数据提取代理,请确保使用的主机至少有 4 v CPUs 和 32 GB 内存。此外,将可用的最小内存设置为 AWS SCT 至少 4 GB。有关更多信息,请参阅 配置额外的内存。
代理主机的最佳配置和数量取决于每个客户的具体情况。请务必考虑诸如要迁移的数据量、网络带宽、提取数据的时间等因素。您可以先执行概念验证(PoC),然后根据此 PoC 的结果配置数据提取代理和主机。
安装提取代理
我们建议您将多个提取代理安装在不同的计算机上,与运行 AWS Schema Conversion Tool的计算机分开。
以下操作系统当前支持提取代理:
Microsoft Windows
Red Hat Enterprise Linux (RHEL) 6.0
Ubuntu Linux(版本 14.04 及更高版本)
使用以下过程安装提取代理。对每台要安装提取代理的计算机重复此过程。
安装提取代理
-
如果您尚未下载 AWS SCT 安装程序文件,请按照中的说明安装和配置 AWS Schema Conversion Tool进行下载。包含 AWS SCT 安装程序文件的.zip 文件还包含解压缩代理安装程序文件。
-
下载并安装最新版本的 Amazon Corretto 11。有关更多信息,请参阅《Amazon Corretto 11 用户指南》中适用于 Amazon Corretto 11 的下载内容。。
-
在一个名为 agents 的子文件夹中查找提取代理的安装程序文件。对于每个计算机操作系统,用于安装提取代理的正确文件如下所示。
操作系统 文件名 Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
通过将安装程序文件复制到新计算机上,在另一台计算机上安装提取代理。
-
运行安装程序文件。使用适合您的操作系统的说明,如下所示。
操作系统 安装说明 Microsoft Windows
双击该文件以运行安装程序。
RHEL
在下载或存储该文件的文件夹中运行以下命令:
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
在下载或存储该文件的文件夹中运行以下命令:
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
选择下一步,接受许可协议,然后选择下一步。
-
输入 AWS SCT 数据提取代理的安装路径,然后选择下一步。
-
选择安装以安装您的数据提取代理。
AWS SCT 安装您的数据提取代理。要完成安装,请配置您的数据提取代理。 AWS SCT 自动启动配置设置程序。有关更多信息,请参阅 配置提取代理。
-
配置数据提取代理后,选择完成以关闭安装向导。
配置提取代理
使用以下过程配置提取代理。对每台已安装提取代理的计算机重复此过程。
配置提取代理
-
启动配置设置程序:
-
在 Windows 中,在安装数据提取代理的过程中自动 AWS SCT 启动配置设置程序。
根据需要,您可以手动启动设置程序。为此,请在 Windows 中运行
ConfigAgent.bat文件。可以在安装代理的文件夹中找到此文件。 -
在 RHEL 和 Ubuntu 中,从安装代理的位置运行
sct-extractor-setup.sh文件。
设置程序会提示您输入信息。对于每个提示,系统会显示默认值。
-
-
在每次提示时接受默认值,或输入新值。
指定以下信息:
对于侦听端口,请输入代理将要侦听的端口号。
对于添加源供应商,输入是,然后输入您的源数据仓库平台。
对于 JDBC 驱动程序,输入安装了 JDBC 驱动程序的位置。
在 “工作文件夹” 中,输入 AWS SCT 数据提取代理存储提取数据的路径。工作文件夹可能与代理分别位于不同的计算机,且单个工作文件夹可由不同计算机上的多个代理共享。
对于启用 SSL 通信,请输入是。
对于密钥存储,请输入密钥存储文件的位置。
对于秘钥存储密码,请输入密钥存储的密码。
对于启用客户端 SSL 身份验证,请输入是。
对于信任存储,请输入信任存储文件的位置。
对于信任存储密码,请输入信任存储的密码。
设置程序将更新提取代理的设置文件。设置文件名为 settings.properties,位于安装了提取代理的位置。
下面是一个设置文件示例。
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFF要更改配置设置,可以使用文本编辑器编辑 settings.properties 文件或再次运行代理配置。
使用专用的复制代理安装和配置提取代理
可以在具有共享存储空间和专用复制代理的配置中安装提取代理。下图阐明了此方案。
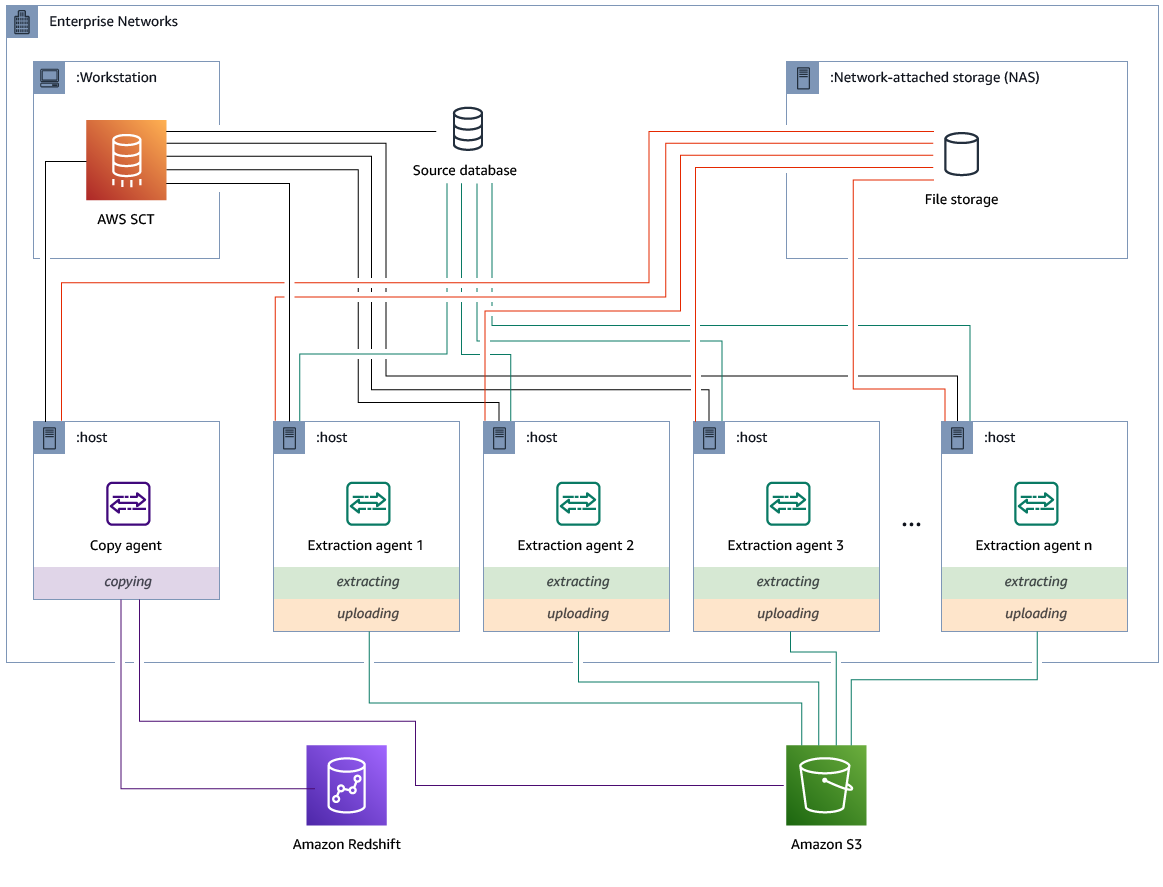
当源数据库服务器支持多达 120 个连接且您的网络连接了充足的存储空间时,该配置可能很有用。使用以下过程配置具有专用复制代理的提取代理。
安装和配置提取代理和专用复制代理
启动提取代理
使用以下过程启动提取代理。对每台已安装提取代理的计算机重复此过程。
提取代理充当侦听器。通过此过程启动代理时,代理将启动侦听以获得指示。在后面的部分中,您将发送代理指示,以从数据仓库提取数据。
启动提取代理
-
在安装了提取代理的计算机上,运行下列适用于您的操作系统的命令。
操作系统 启动命令 Microsoft Windows
双击
StartAgent.bat批处理文件。RHEL
在安装了代理的文件夹的路径中运行以下命令:
sudo initctlstartsct-extractorUbuntu Linux
在安装了代理的文件夹的路径中运行以下命令。使用适合您的 Ubuntu 版本的命令。
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 及更高版本:
sudo systemctlstartsct-extractor
要检查代理的状态,请运行同一命令,但将 start 替换为 status。
要停止代理,请运行同一命令,但将 start 替换为 stop。
在中注册提取剂 AWS Schema Conversion Tool
您可以通过使用来管理提取剂 AWS SCT。提取代理充当侦听器。当他们收到来自的指令时 AWS SCT,他们会从您的数据仓库中提取数据。
使用以下步骤在您的 AWS SCT 项目中注册提取剂。
注册提取代理
-
启动 AWS Schema Conversion Tool,然后打开一个项目。
-
打开视图菜单,然后选择数据迁移视图(其他)。此时显示 Agents 选项卡。如果您之前注册过代理,则 AWS SCT 会在选项卡顶部的网格中显示这些代理。
-
选择注册。
在项目中注册代理后,您无法在其他 AWS SCT 项目中注册同一个代理。如果您不再在 AWS SCT 项目中使用代理,则可以取消注册。然后,您可以将其注册到其他项目。
-
选择 Redshift 数据代理,然后选择确定。
-
请在对话框的连接选项卡上输入您的信息:
-
对于描述,请输入代理的描述。
-
对于主机名称,请输入代理计算机的主机名称或 IP 地址。
-
对于端口,请输入代理将要侦听的端口号。
-
选择 “注册” 以在您的 AWS SCT 项目中注册代理。
-
-
重复上述步骤,向您的 AWS SCT 项目注册多个代理。
隐藏和恢复 AWS SCT 代理的信息
AWS SCT 代理会加密大量信息,例如用户密钥信任存储的密码、数据库帐户、 AWS 帐户信息以及类似项目。它使用一个名为 seed.dat 的特殊文件来进行加密。默认情况下,该代理将在首先配置该代理的用户的工作文件夹中创建此文件。
由于不同的用户可以配置和运行该代理,因此指向 seed.dat 的路径存储在 {extractor.private.folder} 文件的 settings.properties 参数中。当该代理启动时,它可以使用此路径来查找 seed.dat 文件以访问要操作的数据库的密钥-信任存储信息。
在下列情况下,您可能需要恢复代理已存储的密码:
如果用户丢失了
seed.dat文件并且 AWS SCT 代理的位置和端口没有改变。如果用户丢失
seed.dat文件并且 AWS SCT 代理的位置和端口已更改。在这种情况下,变化通常是由于该代理迁移到其他主机或端口而导致的,seed.dat文件中的信息将不再有效。
在这些情况下,如果代理在启动时没有使用 SSL,则它会启动并访问以前创建的代理存储。然后,它会进入 Waiting for recovery (等待恢复) 状态。
但是,在这些情况下,如果代理在启动时使用了 SSL,则无法重新启动它。这是因为代理无法解密存储在 settings.properties 文件中的证书的密码。对于这种类型的启动,该代理将无法启动。在日志中将会写入类似下面这样的错误:“The agent could not start with SSL mode enabled。Please reconfigure the agent。Reason: The password for keystore is incorrect.”(代理无法在启用 SSL 模式的情况下启动。请重新配置代理。原因: 密钥存储中的密钥不正确。)
要修复此问题,请创建一个新代理并将其配置为使用现有密码来访问 SSL 证书。为此,请使用以下过程。
执行此过程后,代理应运行并进入 “等待恢复” 状态。 AWS SCT 自动将所需的密码发送给处于 “等待恢复” 状态的代理。当代理获得密码之后,它将重新启动所有任务。 AWS SCT 端不需要任何进一步的用户操作。
重新配置代理并还原用于访问 SSL 证书的密码
安装新的 AWS SCT 代理并运行配置。
将
agent.name文件中的instance.properties属性更改为创建的存储所用于的代理的名称,以便将新的代理用于现有的代理存储。instance.properties文件存储在代理的私有文件夹中,该文件夹使用以下命名约定:{。output.folder}\dmt\{hostName}_{portNumber}\将
{的名称更改为以前的代理的输出文件夹的名称。output.folder}此时, AWS SCT 仍在尝试访问旧主机和端口上的旧提取器。结果,无法访问的提取器将获得“失败”状态。然后,您可以更改主机和端口。
通过使用 Modify 命令来修改旧代理的主机或/和端口,从而将请求流重定向到新代理。
当 AWS SCT 能 ping 新代理时, AWS SCT 会收到等待代理恢复的状态。 AWS SCT 然后自动恢复代理的密码。
使用代理存储的每个代理将更新一个名为 storage.lck 的、位于 { 的特殊文件。该文件包含代理的网络 ID 和存储锁定的结束时间。当代理使用代理存储时,它每 5 分钟便会更新 output.folder}\{agentName}\storage\storage.lck 文件并将存储的租约延长 10 分钟。在租约过期之前,任何其他实例将无法使用此代理存储。
在中创建数据迁移规则 AWS SCT
在使用提取数据之前 AWS Schema Conversion Tool,您可以设置筛选器来减少提取的数据量。您可以使用 WHERE 子句创建数据迁移前规则,以减少提取的数据量。例如,您可以编写一个 WHERE 子句,以从单个表中选择数据。
您可以创建数据迁移规则,并将筛选条件另存为项目的一部分。打开项目,使用以下过程创建数据迁移规则。
创建数据迁移规则
-
打开视图菜单,然后选择数据迁移视图(其他)。
-
选择数据迁移规则,然后选择添加新规则。
-
配置数据迁移规则:
-
对于名称,请为数据迁移规则输入一个名称。
-
对于架构名称类似于,请输入要应用于架构的筛选条件。在此筛选器中,通过使用
WHERE子句对LIKE子句进行评估。要选择一个架构,请输入确切的架构名称。要选择多个架构,请使用“%”字符作为通配符来匹配架构名称中任意数量的字符。 -
对于表名称类似于,请输入要应用于表的筛选条件。在此筛选器中,通过使用
WHERE子句对LIKE子句进行评估。要选择一张表,请输入一个确切的名称。要选择多个表,请使用“%”字符作为通配符来匹配表名中任意数量的字符。 -
对于 Where 子句,请输入一个
WHERE子句以筛选数据。
-
-
配置完筛选器后,请选择 Save 以保存您的筛选器,或选择 Cancel 以取消您的更改。
-
添加、编辑和删除筛选条件后,选择全部保存以保存您的所有更改。
要关闭筛选器而不删除它,请使用“切换”图标。要复制现有的筛选器,请使用“复制”图标。要删除现有筛选器,请使用“删除”图标。要保存对筛选条件所做的所有更改,请选择全部保存。
从项目设置中更改提取器和复制设置
在的 “项目设置” 窗口中 AWS SCT,您可以为数据提取代理和 Amazon Redshift COPY 命令选择设置。
要选择这些设置,请选择设置、项目设置,然后选择数据迁移。在这里,您可以编辑提取设置、Amazon S3 设置和复制设置。
按照下表中的说明提供有关提取设置的信息。
| 对于此参数 | 请执行该操作 |
|---|---|
压缩格式 |
指定输入文件的压缩格式。选择以下选项之一:GZIP、BZIP2、ZSTD 或不压缩。 |
分隔符字符 |
指定用于分隔输入文件中字段的 ASCII 字符。不支持非打印字符。 |
NULL 值作为字符串 |
如果您的数据包含 null 终止符,请启用此选项。如果关闭此选项,Amazon Redshift |
排序策略 |
使用排序从故障点重新开始提取。选择以下排序策略之一:在第一次失败后使用排序(推荐)、尽可能使用排序或绝不使用排序。有关更多信息,请参阅 在迁移之前使用对数据进行排序 AWS SCT。 |
源临时架构 |
输入源数据库中架构的名称,其中提取代理可以创建临时对象。 |
输出文件大小(MB) |
输入已上传到 Amazon S3 的文件大小(MB)。 |
Snowball 输出文件大小(MB) |
输入上传到的文件的大小(以 MB 为单位) AWS Snowball Edge。文件的大小可以是 1-1000 MB。 |
使用自动分区。对于 Greenplum 和 Netezza,请输入支持的表格的最小大小(兆字节) |
启用此选项以使用表分区,然后输入 Greenplum 和 Netezza 源数据库要分区的表的大小。对于 Oracle 到 Amazon Redshift 的迁移,您可以将此字段保留为空,因为 AWS SCT 会为所有分区表创建子任务。 |
提取 LOBs |
启用此选项可从源数据库中提取大型对象 (LOBs)。 LOBs 包括 BLOBs、 CLOBs、 NCLOBs、XML 文件等。对于每个 LOB, AWS SCT 提取代理都会创建一个数据文件。 |
亚马逊 S3 存储桶 LOBs 文件夹 |
输入 AWS SCT 提取剂的存储位置 LOBs。 |
将 RTRIM 应用于字符串列 |
启用此选项可从提取的字符串的末尾剪裁指定的一组字符。 |
将文件上传到 Amazon S3 后将文件保存在本地 |
启用此选项可在数据提取代理将文件上传到 Amazon S3 后将其保留在本地计算机上。 |
按照下表中的说明提供 Amazon S3 设置的信息。
| 对于此参数 | 请执行该操作 |
|---|---|
使用代理 |
启用此选项可使用代理服务器将数据上传到 Amazon S3。然后选择数据传输协议,输入主机名称、端口、用户名称和密码。 |
端点类型 |
选择 FIPS 以使用美国联邦信息处理标准(FIPS)端点 选择 VPCE 以使用虚拟私有云(VPC)端点。然后,对于 VPC 端点,输入 VPC 端点的域名系统(DNS)。 |
将文件复制到 Amazon Redshift 后将其保存在 Amazon S3 上 |
启用此选项可在将提取的文件复制到 Amazon Redshift 后将其保存在 Amazon S3 上。 |
按照下表中的说明提供复制设置信息。
| 对于此参数 | 请执行该操作 |
|---|---|
最大错误计数 |
输入加载错误的数量。操作达到此限制后, AWS SCT 数据提取代理将结束数据加载过程。默认值为 0,这意味着无论出现何种故障, AWS SCT 数据提取代理都会继续加载数据。 |
替换无效的 UTF-8 字符 |
启用此选项可将无效的 UTF-8 字符替换为指定字符并继续数据加载操作。 |
空白作为空值 |
启用此选项可将由空格字符组成的空白字段加载为空。 |
空作为空值 |
启用此选项可将空 |
截断列 |
启用此选项可截断列中的数据以符合数据类型规范。 |
自动压缩 |
启用此选项可在复制操作期间应用压缩编码。 |
自动刷新统计数据 |
启用此选项可在复制操作结束时刷新统计数据。 |
加载前检查文件 |
启用此选项可在将数据文件加载到 Amazon Redshift 之前对其进行验证。 |
在迁移之前使用对数据进行排序 AWS SCT
在迁移之前使用对数据进行排 AWS SCT 序有一些好处。如果先对数据进行排序,则 AWS SCT 可以在失败后在最后保存的位置重新启动提取代理。此外,如果您要将数据迁移到 Amazon Redshift 并先对数据进行排序,则 AWS SCT 可以更快地将数据插入到 Amazon Redshift 中。
这些好处与如何 AWS SCT 创建数据提取查询有关。在某些情况下,会在这些查询中 AWS SCT 使用 DENSE_RANK 分析函数。但是,DENSE_RANK 会使用大量时间和服务器资源对提取结果的数据集进行排序,因此,如果没有它 AWS SCT 可以工作,它就可以了。
要在迁移之前使用对数据进行排序 AWS SCT
打开一个 AWS SCT 项目。
打开该对象的上下文 (右键单击) 菜单,然后选择创建本地任务。
选择高级选项卡,然后,对于排序策略,选择选项:
绝不使用排序:提取代理不会使用 DENSE_RANK 分析功能,且如果发生故障,它将重新启动。
尽可能使用排序:如果表有主键或唯一约束,提取代理将使用 DENSE_RANK。
在首次失败后使用排序(推荐):提取代理首先尝试在不使用 DENSE_RANK 的情况下获取数据。如果首次尝试失败,提取代理将使用 DENSE_RANK 重新构建查询并在发生故障时保留查询的位置。
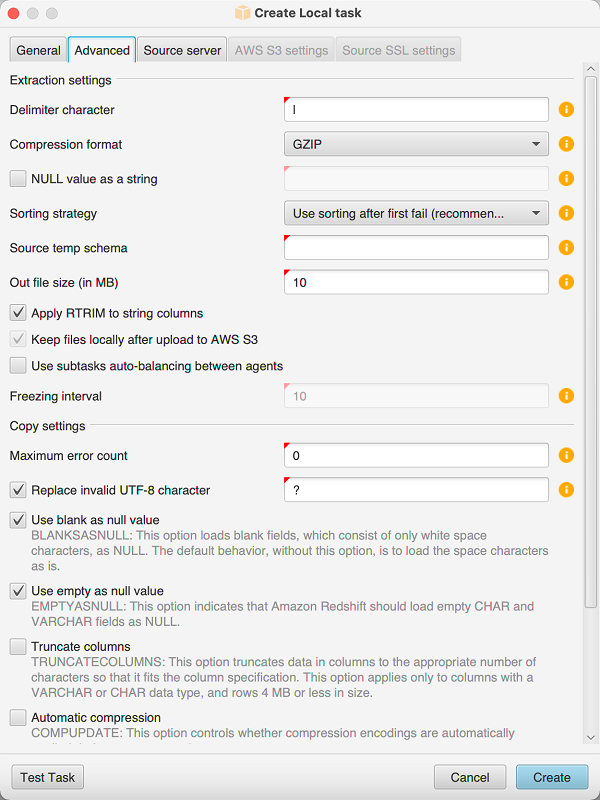
按下面所示设置其他参数,然后选择 Create 以创建您的数据提取任务。
创建、运行和监控 AWS SCT 数据提取任务
使用以下过程创建、运行和监控数据提取任务。
将任务分配给代理并迁移数据
-
在中 AWS Schema Conversion Tool,转换架构后,从项目的左侧面板中选择一个或多个表。
您可以选择所有表,但我们不建议这样做 (出于性能考虑)。我们建议您根据数据仓库中的表大小,为多个表创建多个任务。
-
打开每个表的上下文 (右键单击) 菜单,然后选择创建任务。此时显示创建本地任务对话框。
-
对于任务名称,输入任务的名称。
-
对于迁移模式,请选择下列选项之一:
-
仅提取:提取您的数据,并将数据保存到您的本地工作文件夹。
-
提取并上传:提取您的数据,并将数据上传到 Amazon S3。
-
提取、上传和复制:提取您的数据,将数据上传到 Amazon S3,并将其复制到您的 Amazon Redshift 数据仓库。
-
-
对于加密类型,选择下列选项之一:
-
无:在整个数据迁移过程中关闭数据加密。
-
CSE_SK — 使用带有对称密钥的客户端加密来迁移数据。 AWS SCT 使用安全套接字层 (SSL) 自动生成加密密钥并将其传输到数据提取代理。 AWS SCT 在数据迁移期间不加密大型对象 (LOBs)。
-
-
选择 “提取” LOBs 以提取大型对象。如果您不需要提取大型对象,则可以清除该复选框。这样做可以减少提取的数据量。
-
如果要查看有关任务的详细信息,请选择启用任务日志记录。您可以使用任务日志来调试问题。
如果启用任务日志记录,请选择要查看的详细信息级别。级别如下所示,每个级别包含上一级别的所有消息:
ERROR:最小数量的详细信息。WARNINGINFODEBUGTRACE:最大数量的详细信息。
-
要从中导出数据 BigQuery,请 AWS SCT 使用 Google 云存储空间存储分区文件夹。数据提取代理在此文件夹中存储您的源数据。
要输入 Google Cloud Storage 存储桶文件夹的路径,请选择高级。对于 Google CS 存储桶文件夹,输入存储桶名称和文件夹名称。
-
要为您的数据提取代理用户代入角色,请选择 Amazon S3 设置。对于 IAM 角色,输入要使用的角色的名称。在 “区域” 中, AWS 区域 为该角色选择。
-
选择测试任务以验证是否可连接到您的工作文件夹、Amazon S3 存储桶和 Amazon Redshift 数据仓库。验证取决于您选择的迁移模式。
-
选择 Create (创建) 以创建任务。
-
重复之前步骤,为您要迁移的所有数据创建任务。
运行和监控任务
-
对于视图,选择数据迁移视图。此时显示 Agents 选项卡。
-
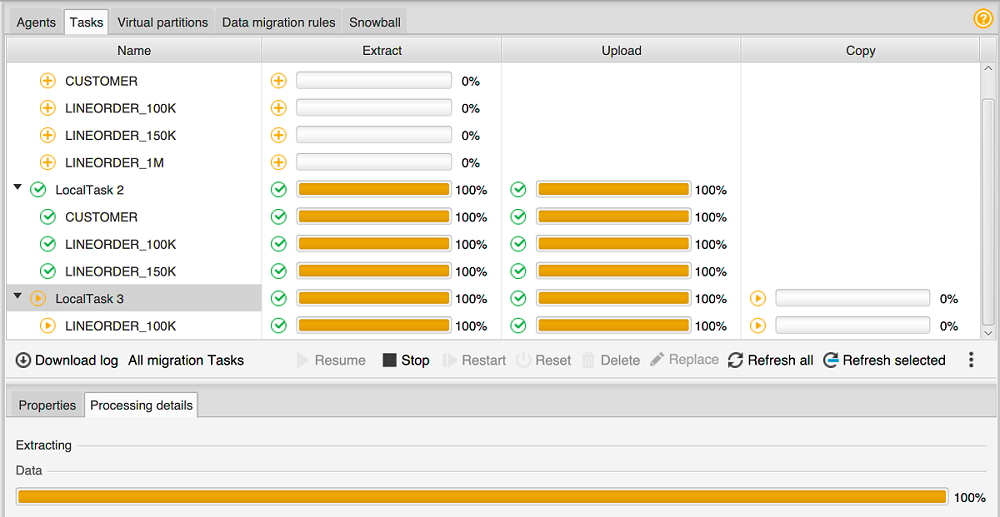
选择 Tasks 选项卡。您的任务将显示在顶部网格中,如下所示。您可以在顶部网格中查看任务的状态,并在底部网格中查看其子任务的状态。
-
在顶部网格中选择一个任务并将其展开。根据所选的迁移模式,您将看到该任务分为 Extract、Upload 和 Copy。
-
对任务选择 Start 以开始该任务。您可以监控任务工作时的状态。其子任务并行运行。提取、上传和复制操作也并行运行。
-
如果启用了日志记录,当您设置任务时,可以查看日志:
-
选择下载日志。此时显示一条消息,其中包含存储该日志文件的文件夹的名称。关闭该消息。
-
Task details 选项卡中显示一个链接。选择该链接以打开包含日志文件的文件夹。
-
您可以关闭 AWS SCT,您的代理和任务将继续运行。您可以 AWS SCT 稍后重新打开以检查任务状态并查看任务日志。
您可以将数据提取任务保存到本地磁盘,然后使用导出和导入将其还原到同一项目或其他项目。如需导出任务,请确保项目中至少创建了一个提取任务。您可以导入项目中创建的单个提取任务或所有提取任务。
导出提取任务时, AWS SCT 会为该任务创建一个单独的.xml文件。该 .xml 文件存储该任务的元数据信息,例如任务属性、描述和子任务。该 .xml 文件不包含有关提取任务处理的信息。导入任务时,会重新创建如下信息:
-
任务进度
-
子任务和阶段状态
-
按子任务和阶段分配提取代理
-
任务和子任务 IDs
-
任务名称
导出和导入 AWS SCT 数据提取任务
您可以快速保存一个项目中的现有任务,然后使用导 AWS SCT 出和导入将其恢复到另一个项目(或同一个项目)中。使用以下过程可导出和导入数据提取任务。
导出和导入数据提取任务
-
对于视图,选择数据迁移视图。此时显示 Agents 选项卡。
-
选择 Tasks 选项卡。您的任务将在出现的网格中列出。
-
选择位于任务列表右下角的三个垂直对齐的点(省略号图标)。
-
从弹出式菜单中选择导出任务。
-
选择 AWS SCT 要放置任务导出
.xml文件的文件夹。AWS SCT 创建文件名格式为的任务导出文件
TASK-DESCRIPTION_TASK-ID.xml -
选择任务列表右下角的三个垂直对齐的点(省略号图标)。
-
从弹出式菜单中选择导入任务。
您可以将提取任务导入到与源数据库相连的项目,并且该项目至少有一个已注册的提取代理处于活动状态。
-
为导出的提取任务选择
.xml文件。AWS SCT 从文件中获取提取任务的参数,创建任务,然后将任务添加到提取代理中。
-
重复这些步骤以导出和导入其他数据提取任务。
在此过程结束时,您的导出和导入已完成,并且您的数据提取任务已准备就绪。
使用 AWS Snowball Edge Edge 设备提取数据
使用 AWS SCT 和 AWS Snowball Edge Edge 的过程分为几个步骤。迁移涉及本地任务,即 AWS SCT 使用数据提取代理将数据移至 AWS Snowball Edge Edge 设备,然后是将数据从 Ed AWS Snowball Edge ge 设备 AWS 复制到 Amazon S3 存储桶的中间操作。该过程完成了将数据从 Amazon S3 存储桶 AWS SCT 加载到 Amazon Redshift。
本概述之后的各节为每项任务提供了 step-by-step指南。该过程假设您已在专用计算机上 AWS SCT 安装并配置和注册了数据提取代理。
执行以下步骤,使用 AWS Snowball Edge Edge 将数据从本地数据存储迁移到 AWS 数据存储。
使用 AWS Snowball Edge 控制台创建 AWS Snowball Edge Edge 作业。
使用本地专用 Linux 计算机解锁 AWS Snowball Edge Edge 设备。
在中创建新项目 AWS SCT。
安装和配置数据提取代理。
创建要使用的 Amazon S3 存储桶并设置权限。
将 AWS Snowball Edge 任务导入您的 AWS SCT 项目。
在 AWS SCT中注册数据提取代理。
在中创建本地任务 AWS SCT。
在 AWS SCT中运行和监控数据迁移任务。
Step-by-step 使用 AWS SCT 和 AWS Snowball Edge Edge 迁移数据的过程
以下部分提供了有关迁移步骤的详细信息。
步骤 1:创建 AWS Snowball Edge 边缘任务
按照《AWS Snowball Edge 边AWS Snowball Edge 缘开发者指南》中创建 Edge AWS Snowball Edge Job 一节中概述的步骤创建作业。
第 2 步:解锁 AWS Snowball Edge Edge 设备
运行命令,从安装代理的计算机上解锁 Snowball Edge 设备并向 Snowball Edge 设备提供凭据。 AWS DMS 通过运行这些命令,可以确保 AWS DMS 代理呼叫连接到 AWS Snowball Edge Edge 设备。有关解锁 AWS Snowball Edge Edge 设备的更多信息,请参阅解锁 Snowball Edge Edge。
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
步骤 3:创建新 AWS SCT 项目
接下来,创建一个新 AWS SCT 项目。
要在中创建新项目 AWS SCT
-
启动 AWS Schema Conversion Tool. 在文件菜单上,选择新建项目。此时将显示新建项目对话框。
-
为本地存储在计算机上的项目输入一个名称。
-
输入本地项目文件的位置。
-
选择 “确定” 创建您的 AWS SCT 项目。
-
选择 “添加源”,将新的源数据库添加到您的 AWS SCT 项目中。
-
选择添加目标可在 AWS SCT 项目中添加新的目标平台。
-
在左侧面板中选择源数据库架构。
-
在右侧面板中,为所选源架构指定目标数据库平台。
-
选择创建映射。选择源数据库架构和目标数据库平台后,此按钮将变为活动状态。
步骤 4:安装和配置数据提取代理
AWS SCT 使用数据提取代理将数据迁移到 Amazon Redshift。您下载用于安装的.zip 文件 AWS SCT包括解压缩代理安装程序文件。您可以在 Windows、Red Hat Enterprise Linux 或 Ubuntu 中安装数据提取代理。有关更多信息,请参阅 安装提取代理。
要配置数据提取代理,请输入源数据库引擎和目标数据库引擎。此外,请确保在运行数据提取代理的计算机上下载了源数据库和目标数据库的 JDBC 驱动程序。数据提取代理使用这些驱动程序连接至源数据库和目标数据库。有关更多信息,请参阅 正在安装 JDBC 驱动程序 AWS Schema Conversion Tool。
在 Windows 中,数据提取代理安装程序在命令提示符窗口中启动配置向导。在 Linux 中,从安装代理的位置运行该 sct-extractor-setup.sh 文件。
步骤 5:配置 AWS SCT 为访问 Amazon S3 存储桶
有关 Amazon S3 存储桶的更多信息,请参阅《Amazon Simple Storage Service 用户指南》中的存储桶概述。
第 6 步:将 AWS Snowball Edge 作业导入您的 AWS SCT 项目
要将您的 AWS SCT 项目与 AWS Snowball Edge Edge 设备连接,请导入您的 AWS Snowball Edge 作业。
导入您的 AWS Snowball Edge 作业
-
打开设置菜单,然后选择全局设置。此时显示 Global settings 对话框。
-
选择 AWS 服务配置文件,然后选择导入作业。
选择你的 AWS Snowball Edge 工作。
-
输入 AWS Snowball Edge IP。有关更多信息,请参阅《AWS Snowball Edge 用户指南》中的更改 IP 地址。
-
输入您的 AWS Snowball Edge 端口。有关更多信息,请参阅《边缘开发者指南》中的在 AWS Snowball Edge 边缘设备上使用 AWS 服务所需的AWS Snowball Edge 端口。
-
输入您的 AWS Snowball Edge 访问密钥和 AWS Snowball Edge 秘密密钥。有关更多信息,请参阅《AWS Snowball Edge 用户指南》中的 AWS Snowball Edge中的身份验证和访问控制。
选择应用,然后选择确定。
步骤 7:在中注册数据提取代理 AWS SCT
在本节中,您将在 AWS SCT中注册数据提取代理。
注册数据提取代理
-
在视图菜单上,选择数据迁移视图(其他),然后选择注册。
-
对于描述,请输入数据提取代理名称。
-
对于主机名,请输入运行数据提取代理的计算机的 IP 地址。
-
对于端口,请输入您配置的侦听端口。
-
选择注册。
步骤 8:创建本地任务
接下来,创建迁移任务。该任务包含两个子任务。一个子任务将数据从源数据库迁移到 AWS Snowball Edge Edge 设备。另一个子任务提取该设备加载到 Amazon S3 存储桶的数据,并将其迁移到目标数据库。
创建迁移任务
-
打开视图菜单,然后选择数据迁移视图(其他)。
在显示源数据库架构的左侧面板中,选择一个要迁移的架构对象。打开该对象的上下文 (右键单击) 菜单,然后选择创建本地任务。
-
对于任务名称,请输入数据迁移任务的描述性名称。
-
对于迁移模式,选择提取、上传和复制。
-
选择 Amazon S3 设置。
-
选择使用 Snowball Edge。
-
在 Amazon S3 存储桶中输入数据提取代理可以存储数据的文件夹和子文件夹。
-
选择 Create (创建) 以创建任务。
步骤 9:在中运行和监控数据迁移任务 AWS SCT
要启动数据迁移任务,请选择开始。确保在上建立了与源数据库、Amazon S3 存储桶、 AWS Snowball Edge 设备的连接以及与目标数据库的连接 AWS。
您可以在任务选项卡中监控和管理数据迁移任务及其子任务。您可以查看数据迁移进度,也可以暂停或重启数据迁移任务。
数据提取任务输出
迁移任务完成后,您的数据便准备就绪。使用以下信息确定如何根据所选的迁移模式和数据位置继续操作。
| 迁移模式 | 数据位置 |
|---|---|
|
提取、上传和复制 |
数据已在您的 Amazon Redshift 数据仓库中。您可以验证数据是否存在,并开始使用它。有关更多信息,请参阅通过客户端工具和代码连接到集群。 |
|
提取和上传 |
提取代理已将您的数据以文件形式保存在 Amazon S3 存储桶中。您可以使用 Amazon Redshift 复制命令将数据加载到 Amazon Redshift。有关更多信息,请参阅 Amazon Redshift 文档中的从 Amazon S3 加载数据。 您的 Amazon S3 存储桶中包含多个文件夹,与您设置的提取任务对应。将数据加载到 Amazon Redshift 时,请指定每个任务所创建的清单文件的名称。清单文件显示在 Amazon S3 存储桶的任务文件夹中,如下所示。 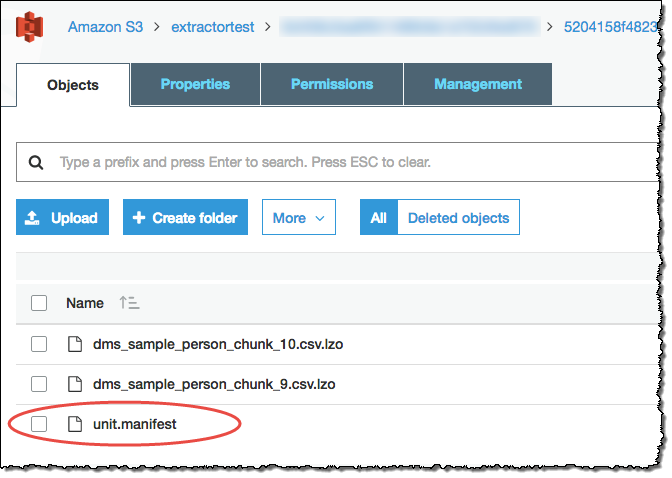
|
|
仅提取 |
提取代理已将您的数据以文件形式保存在工作文件夹中。手动将数据复制到 Amazon S3 存储桶,然后按照提取和上传的说明继续操作。 |
将虚拟分区与 AWS Schema Conversion Tool
通常,您可以通过创建子任务 (使用筛选规则创建表数据的虚拟分区) 来最有效地管理大型未分区表。在中 AWS SCT,您可以为迁移的数据创建虚拟分区。有三种可与特定数据类型搭配使用的分区类型:
RANGE 分区类型,可与数字以及日期和时间数据类型搭配使用。
LIST 分区类型,可与数字、字符以及日期和时间数据类型搭配使用。
DATE AUTO SPLIT 分区类型,可与数字、日期和时间数据类型搭配使用。
AWS SCT 验证您为创建分区提供的值。例如,如果您尝试对数据类型为 NUMERIC 的列进行分区,但却提供了不同的数据类型的值,则 AWS SCT 会引发错误。
此外,如果您使用将数据迁移 AWS SCT 到 Amazon Redshift,则可以使用本机分区来管理大型表的迁移。有关更多信息,请参阅 使用本机分区。
创建虚拟分区时的限制
以下是创建虚拟分区的限制:
您只能对未分区的表使用虚拟分区。
您只能在数据迁移视图中使用虚拟分区。
您无法对虚拟分区使用选项 UNION ALL VIEW。
RANGE 分区类型
RANGE 分区类型基于针对数字以及日期和时间数据类型的一系列值对数据进行分区。此分区类型将创建一个 WHERE 子句,您将为每个分区提供值范围。使用值框为已分区的列指定一个值列表。您可以使用 .csv 文件加载值信息。
RANGE 分区类型在分区值的两端创建默认分区。这些默认分区会捕获任何小于或大于指定分区值的数据。
例如,您可以基于您提供的值范围创建多个分区。在以下示例中,指定了 LO_TAX 的分区值以创建多个分区。
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
创建 RANGE 虚拟分区
打开 AWS SCT。
选择数据迁移视图(其他)模式。
选择要在其中设置虚拟分区的表。打开该表的上下文 (右键单击) 菜单,并选择添加虚拟分区。
在添加虚拟分区对话框中,输入如下信息。
Option Action 分区类型
选择 RANGE。根据您选择的类型,对话框 UI 将发生更改。
列名称
选择要分区的列。
列类型
在该列中选择值的数据类型。
值
通过在 New Value 框中键入各个值来添加新值,然后选择加号以添加相应值。
从文件加载
(可选)输入包含分区值的 .csv 文件的名称。
-
选择确定。
LIST 分区类型
LIST 分区类型基于一个数字、字符以及日期和时间数据类型的列值对数据进行分区。此分区类型将创建一个 WHERE 子句,您将为每个分区提供值。使用值框为已分区的列指定一个值列表。您可以使用 .csv 文件加载值信息。
例如,您可以基于您提供的值创建多个分区。在以下示例中,指定了 LO_ORDERKEY 的分区值以创建多个分区。
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
您还可以为未包含在指定的分区中的值创建默认分区。
如果要从迁移中排除特定值,则可以使用 LIST 分区类型来筛选源数据。例如,假设您要省略带 LO_ORDERKEY = 4 的行。在这种情况下,请不要在分区值列表中包含该值 4,并确保未选择包括其他值。
创建 LIST 虚拟分区
打开 AWS SCT。
选择数据迁移视图(其他)模式。
选择要在其中设置虚拟分区的表。打开该表的上下文 (右键单击) 菜单,并选择添加虚拟分区。
在添加虚拟分区对话框中,输入如下信息。
Option Action 分区类型
选择 LIST。根据您选择的类型,对话框 UI 将发生更改。
列名称
选择要分区的列。
新值
在此处键入一个值以将其添加到分区值集。
包括其他值
选择此选项可创建一个默认分区,不满足分区条件的所有值都将存储在该分区中。
从文件加载
(可选)输入包含分区值的 .csv 文件的名称。
选择确定。
DATE AUTO SPLIT 分区类型
DATE AUTO SPLIT 分区类型是一种自动生成 RANGE 分区的方式。使用 DATA AUTO SPLIT,您可以告诉 AWS SCT 分区属性、起点和结束位置以及值之间的范围大小。然后, AWS SCT 自动计算分区值。
DATA AUTO SPLIT 可自动执行创建范围分区所涉及的大量工作。使用这种技术和范围分区之间的权衡是您对分区边界的控制程度。自动拆分过程始终创建大小相等(统一)的范围。范围分区使您可以根据特定数据分布的需要改变每个范围的大小。例如,您可以使用每日、每周、每两周、每月等。
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
创建 DATE AUTO SPLIT 虚拟分区
打开 AWS SCT。
选择数据迁移视图(其他)模式。
选择要在其中设置虚拟分区的表。打开该表的上下文 (右键单击) 菜单,并选择添加虚拟分区。
在添加虚拟分区对话框中,输入如下信息。
Option Action 分区类型
选择 DATE AUTO SPLIT。根据您选择的类型,对话框 UI 将发生更改。
列名称
选择要分区的列。
开始日期
键入开始日期。
结束日期
键入结束日期。
Interval
输入间隔单位,然后选择该单位的值。
选择确定。
使用本机分区
为了加快数据迁移速度,您的数据提取代理可以使用源数据仓库服务器上表的本机分区。 AWS SCT 支持原生分区,用于从 Greenplum、Netezza 和 Oracle 迁移到 Amazon Redshift。
例如,在创建项目后,您可以收集架构的统计信息并分析选定要迁移的表的大小。对于超过指定大小的表, AWS SCT 会触发本机分区机制。
使用本机分区
-
打开 AWS SCT,然后为 “文件” 选择 “新建项目”。此时将显示新建项目对话框。
-
创建新项目,添加源服务器和目标服务器,并创建映射规则。有关更多信息,请参阅 在中启动和管理项目 AWS SCT。
-
选择视图,然后选择主视图。
-
在项目设置中,选择数据迁移选项卡。选择使用自动分区。对于 Greenplum 和 Netezza 源数据库,请输入支持表的最小大小,以兆字节为单位(例如 100)。 AWS SCT 自动为每个不为空的本机分区创建单独的迁移子任务。对于 Oracle 到 Amazon Redshift 的迁移,需要为所有分区表 AWS SCT 创建子任务。
-
在显示源数据库中的架构的左面板中,选择架构。打开该对象的上下文 (右键单击) 菜单,然后选择收集统计数据。要将数据从 Oracle 迁移到 Amazon Redshift,您可以跳过此步骤。
-
选择所有要迁移的表。
-
注册所需数量的代理。有关更多信息,请参阅 在中注册提取剂 AWS Schema Conversion Tool。
-
为所选表创建数据提取任务。有关更多信息,请参阅 创建、运行和监控 AWS SCT 数据提取任务。
检查大型表是否被拆分为子任务,以及每个子任务是否与呈现源数据仓库中一个切片上的表的一部分的数据集相匹配。
-
启动并监控迁移过程,直到 AWS SCT 数据提取代理完成源表中的数据迁移。
迁移 LOBs 到亚马逊 Redshift
Amazon Redshift 不支持存储大型二进制对象 () LOBs。但是,如果您需要将一个或多个迁移 LOBs 到 Amazon Redshift, AWS SCT 可以执行迁移。为此,请 AWS SCT 使用亚马逊 S3 存储桶来存储 Amazon S3 存储桶, LOBs 并将该存储桶的 URL 写入存储在 Amazon Redshift 中的迁移数据中。
迁移 LOBs 到亚马逊 Redshift
打开一个 AWS SCT 项目。
连接到源数据库和目标数据库。刷新目标数据库中的元数据,并确保转换后的表存在于目标数据库中。
对于操作,选择创建本地任务。
-
对于迁移模式,请选择下列选项之一:
-
提取并上传提取您的数据,并将数据上传到 Amazon S3。
-
提取、上传和复制提取您的数据,将数据上传到 Amazon S3,并将其复制到 Amazon Redshift 数据仓库。
-
选择Amazon S3 设置。
对于 Amazon S3 存储桶 LOBs 文件夹,在 Amazon S3 存储桶中输入要 LOBs 存储该文件夹的名称。
如果您使用 AWS 服务配置文件,则此字段为可选字段。 AWS SCT 可以使用您个人资料中的默认设置。要使用其他 Amazon S3 存储桶,请在此处输入路径。
-
启用使用代理选项,使用代理服务器将数据上传到 Amazon S3。然后选择数据传输协议,输入主机名称、端口、用户名称和密码。
-
对于加密类型,选择 FIPS 以使用联邦信息处理标准(FIPS)端点。选择 VPCE 以使用虚拟私有云(VPC)端点。然后,对于 VPC 端点,输入 VPC 端点的域名系统(DNS)。
-
打开文件复制到 Amazon Redshift 后将其保留在 Amazon S3 上选项,以便在将提取的文件复制到 Amazon Redshift 后将这些文件保留在 Amazon S3 上。
选择 Create (创建) 以创建任务。
数据提取代理的最佳实践和故障排除
以下是一些关于使用提取代理的最佳实践和故障排除建议。
| 问题 | 故障排除建议 |
|---|---|
|
性能低下 |
为了提高性能,我们建议执行以下操作:
|
|
争用延迟 |
避免有太多代理同时访问您的数据仓库。 |
|
代理暂时关闭 |
如果某代理关闭,其每个任务在 AWS SCT中的状态显示为失败。如果等待,某些情况下,该代理可以恢复。在这种情况下,其任务的状态会在 AWS SCT中更新。 |
|
代理永久关闭 |
如果运行代理的计算机永久关闭,而该代理正运行一个任务,您可以替换新的代理以继续该任务。仅当原始代理的工作文件夹与原始代理不位于同一台计算机时,您才可以使用新代理进行替换。要替换新的代理,请执行以下操作:
|
