本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Hadoop 工作负载迁移到 Amazon EMR AWS Schema Conversion Tool
要迁移 Apache Hadoop 集群,请确保使用 AWS SCT 版本 1.0.670 或更高版本。另外,请熟悉 AWS SCT的命令行接口 (CLI)。有关更多信息,请参阅 的 CLI 参考 AWS Schema Conversion Tool。
主题
迁移概述
下图显示了从 Apache Hadoop 迁移到 Amazon EMR 的架构图。
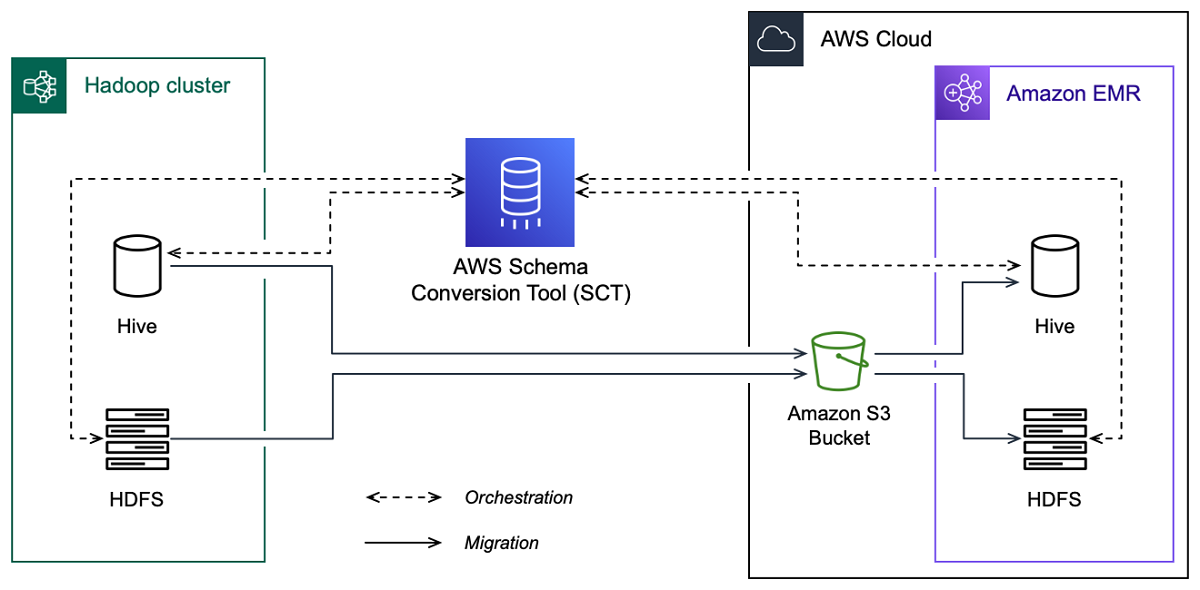
AWS SCT 将数据和元数据从您的源 Hadoop 集群迁移到 Amazon S3 存储桶。接下来, AWS SCT 使用源 Hive 元数据在目标 Amazon EMR Hive 服务中创建数据库对象。或者,您可以将 Hive 配置为使用 AWS Glue Data Catalog 作为其元数据仓。在这种情况下,会将您的源 Hive 元数据 AWS SCT 迁移到。 AWS Glue Data Catalog
然后,您可以使用将数据从 Amazon S3 存储桶迁移 AWS SCT 到您的目标 Amazon EMR HDFS 服务。或者,您可以将数据保留在 Amazon S3 存储桶中,并将其用作 Hadoop 工作负载的数据存储库。
要启动 Hapood 迁移,您需要创建并运行您的 AWS SCT CLI 脚本。此脚本包含运行迁移的完整命令集。您可以下载和编辑 Hadoop 迁移脚本的模板。有关更多信息,请参阅 获取 CLI 场景。
请确保您的脚本包含以下步骤,以便您可以运行从 Apache Hadoop 到 Amazon S3 和 Amazon EMR 的迁移。
步骤 1:连接到 Hadoop 集群
要开始迁移 Apache Hadoop 集群,请创建一个新项目。 AWS SCT 接下来,连接到源集群和目标集群。在开始迁移之前,请务必创建和配置目标 AWS 资源。
在此步骤中,您将使用以下 AWS SCT CLI 命令。
CreateProject— 创建新 AWS SCT 项目。AddSourceCluster:用于连接到 AWS SCT 项目中的源 Hadoop 集群。AddSourceClusterHive:连接到项目中的源 Hive 服务。AddSourceClusterHDFS:用于连接到项目中的源 HDFS 服务。AddTargetCluster:连接到项目中的目标 Amazon EMR 集群。AddTargetClusterS3:将 Amazon S3 存储桶添加到您的项目。AddTargetClusterHive:连接到项目中的目标 Hive 服务AddTargetClusterHDFS:连接到项目中的目标 HDFS 服务
有关使用这些 AWS SCT CLI 命令的示例,请参见连接到 Apache Hadoop。
当您运行连接到源集群或目标集群的命令时, AWS SCT 会尝试与该集群建立连接。如果连接尝试失败,则 AWS SCT 停止运行 CLI 脚本中的命令并显示错误消息。
步骤 2:设置映射规则
连接到源集群和目标集群后,设置映射规则。映射规则定义了源集群的迁移目标。确保为 AWS SCT 项目中添加的所有源集群设置映射规则。有关映射规则的更多信息,请参阅 在 AWS Schema Conversion Tool 中映射数据类型。
在此步骤中,您将使用 AddServerMapping 命令。此命令使用两个参数,分别定义源集群和目标集群。您可以将该 AddServerMapping 命令与数据库对象的显式路径或对象名称一起使用。对于第一个选项,包括对象的类型及其名称。对于第二个选项,只包括对象名称。
-
sourceTreePath:源数据库对象的显式路径。targetTreePath:目标数据库对象的显式路径。 -
sourceNamePath:仅包含源对象名称的路径。targetNamePath:仅包含目标对象名称的路径。
以下代码示例使用源 testdb Hive 数据库和目标 EMR 集群的显式路径创建映射规则。
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
您可以在 Windows 中使用此示例和以下示例。要在 Linux 中运行 CLI 命令,请确保根据您的操作系统相应地更新了文件路径。
以下代码示例使用仅包含对象名称的路径创建映射规则。
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
您可以选择 Amazon EMR 或 Amazon S3 作为源对象的目标。对于每个源对象,您只能在单个 AWS SCT 项目中选择一个目标。要更改源对象的迁移目标,请删除现有的映射规则,然后创建新的映射规则。要删除映射规则,请使用 DeleteServerMapping 命令。此命令使用以下两个参数之一。
sourceTreePath:源数据库对象的显式路径。sourceNamePath:仅包含源对象名称的路径。
有关 AddServerMapping 和 DeleteServerMapping 命令的更多信息,请参阅《AWS Schema Conversion Tool 参考》https://s3.amazonaws.com/publicsctdownload/AWS+SCT+CLI+Reference.pdf
步骤 3:创建评估报告
在开始迁移之前,建议您创建一份评估报告。该报告总结了所有迁移任务,并详细说明了迁移期间将出现的操作项。为确保迁移不会失败,请在迁移之前查看此报告并解决操作项。有关更多信息,请参阅 评测报告。
在此步骤中,您将使用 CreateMigrationReport 命令。此命令使用两个参数。treePath 参数是必填的,而 forceMigrate 参数是可选的。
treePath:保存评估报告副本的源数据库对象的明确路径。forceMigrate— 如果设置为true,即使您的项目包含引用同一对象的 HDFS 文件夹和 Hive 表,也会 AWS SCT 继续迁移。默认值为false。
您可以将评估报告的副本另存为 PDF 文件或逗号分隔值 (CSV) 文件。为此,使用SaveReportPDF 或 SaveReportCSV 命令。
该 SaveReportPDF 命令将评估报告的副本另存为 PDF 文件。此命令使用四个参数。file 参数为必填的;其他参数是可选的。
file:PDF 文件的路径及其名称。filter:您之前创建的筛选器的名称,用于定义要迁移的源对象的范围。treePath:保存评估报告副本的源数据库对象的明确路径。namePath:仅包含保存评估报告副本的目标对象名称的路径。
SaveReportCSV 命令将您的评估报告保存为三个 CSV 文件。此命令使用四个参数。directory 参数为必填的;其他参数是可选的。
directory— 保 AWS SCT 存 CSV 文件的文件夹的路径。filter:您之前创建的筛选器的名称,用于定义要迁移的源对象的范围。treePath:保存评估报告副本的源数据库对象的明确路径。namePath:仅包含保存评估报告副本的目标对象名称的路径。
以下代码示例将评估报告的副本保存在 c:\sct\ar.pdf 文件中。
SaveReportPDF -file:'c:\sct\ar.pdf' /
以下代码示例将评估报告的副本另存为 c:\sct 文件夹中的 CSV 文件。
SaveReportCSV -file:'c:\sct' /
有关 SaveReportPDF 和 SaveReportCSV 命令的更多信息,请参阅《AWS Schema Conversion Tool CLI 参考》https://s3.amazonaws.com/publicsctdownload/AWS+SCT+CLI+Reference.pdf
第 4 步:使用以下命令将你的 Apache Hadoop 集群迁移到亚马逊 EMR AWS SCT
配置 AWS SCT 项目后,开始将本地 Apache Hadoop 集群迁移到。 AWS Cloud
在此步骤中,您将使用 Migrate、MigrationStatus 和 ResumeMigration 命令。
Migrate 命令会将源对象迁移到目标集群。此命令使用四个参数。请务必指定 filter 或 treePath 参数。其他参数都是可选的。
filter:您之前创建的筛选器的名称,用于定义要迁移的源对象的范围。treePath:保存评估报告副本的源数据库对象的明确路径。forceLoad— 如果设置为true, AWS SCT 则会在迁移期间自动加载数据库元数据树。默认值为false。forceMigrate— 如果设置为true,即使您的项目包含引用同一对象的 HDFS 文件夹和 Hive 表,也会 AWS SCT 继续迁移。默认值为false。
MigrationStatus 命令将返回有关命令进程的信息。要运行此命令,请为 name 参数输入迁移项目的名称。您在 CreateProject 命令中指定了此名称。
ResumeMigration 命令会恢复您使用 Migrate 命令启动的中断迁移。该 ResumeMigration 命令不使用参数。要恢复迁移,您必须连接到源集群和目标集群。有关更多信息,请参阅 管理迁移项目。
以下代码示例将数据从您的源 HDFS 服务迁移到 Amazon EMR。
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
运行 CLI 脚本
编辑 AWS SCT CLI 脚本后,将其另存为.scts扩展名为的文件。现在,您可以从 AWS SCT 安装路径的app文件夹中运行脚本。为此,请使用以下命令。
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
在前面的示例中,script_path用 CLI 脚本替换为文件路径。有关在中运行 CLI 脚本的更多信息 AWS SCT,请参阅脚本模式。
管理大数据迁移项目
完成迁移后,您可以保存和编辑 AWS SCT 项目以备将来使用。
要保存您的 AWS SCT 项目,请使用SaveProject命令。此命令不使用参数。
以下代码示例保存了您的 AWS SCT 项目。
SaveProject /
要打开您的 AWS SCT 项目,请使用OpenProject命令。此命令使用一个必填参数。在file参数中,输入 AWS SCT 项目文件的路径及其名称。您在 CreateProject 命令中指定了项目名称。确保在项目文件名中添加 .scts 扩展名以运行 OpenProject 命令。
以下代码示例从 c:\sct 文件夹中打开 hadoop_emr 项目。
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
打开 AWS SCT 项目后,您无需添加源集群和目标集群,因为您已经将它们添加到项目中。要开始使用源集群和目标集群,必须先连接到它们。为此,您可以使用 ConnectSourceCluster 和 ConnectTargetCluster 命令。这些命令使用的参数与 AddSourceCluster 和 AddTargetCluster 命令相同。您可以编辑 CLI 脚本并替换这些命令的名称,使参数列表保持不变。
以下代码示例连接到源 Hadoop 集群。
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
以下代码示例连接到目标 Amazon EMR 集群。
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
在前面的示例中,hadoop_address替换为您的 Hadoop 集群的 IP 地址。如果需要,请配置端口变量的值。接下来,用您的 Hadoop 用户名和该用户的密码替换hadoop_user和。hadoop_password对于path\name,输入源 Hadoop 集群的 PEM 文件的名称和路径。有关添加源集群和目标集群的更多信息,请参阅 使用连接到 Apache Hadoop 数据库 AWS Schema Conversion Tool。
连接到源集群和目标 Hadoop 集群后,必须连接到 Hive 和 HDFS 服务以及 Amazon S3 存储桶。为此,您可以使用 ConnectSourceClusterHive、ConnectSourceClusterHdfs、ConnectTargetClusterHive、ConnectTargetClusterHdfs 和 ConnectTargetClusterS3 命令。这些命令使用的参数与您用于向项目添加 Hive 和 HDFS 服务以及 Amazon S3 存储桶的命令相同。编辑 CLI 脚本,将命令名称中的 Add 前缀替换为 Connect。
