DynamoDB 中的投诉管理系统架构设计
投诉管理系统业务使用场景
DynamoDB 是一个非常适合投诉管理系统(或联系中心)使用场景的数据库,因为与之关联的大多数访问模式都是基于键/值的事务性查找。在这种情况下,典型的访问模式将是:
-
创建和更新投诉
-
上报投诉
-
创建和阅读对投诉的评论
-
收到客户的所有投诉
-
获取客服坐席的所有评论并获取所有上报
有些评论可能有描述投诉或解决方案的附件。虽然这些都是键/值访问模式,但可能还有其他要求,例如在投诉中添加新评论时发送通知,或者运行分析查询以每周按严重程度(或客服坐席绩效)查找投诉分布情况。与生命周期管理或合规性相关的另一项要求是在记录投诉三年后归档投诉数据。
投诉管理系统架构图
下图显示投诉管理系统的架构图。此图显示了投诉管理系统使用的不同 AWS 服务集成。
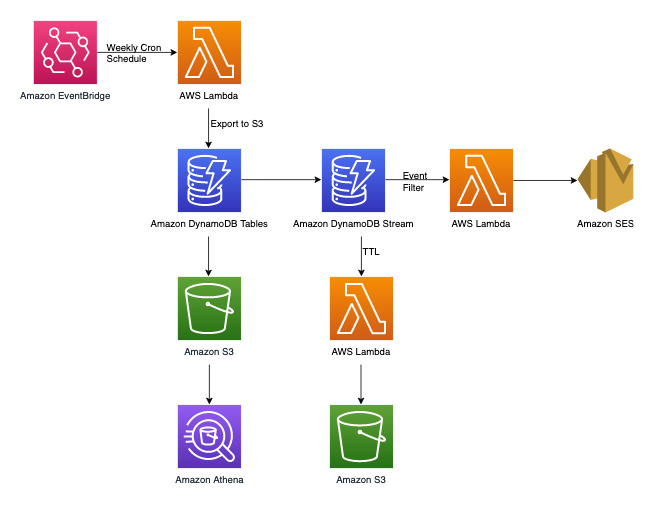
除了我们稍后将在 DynamoDB 数据建模部分中处理的键/值事务性访问模式外,我们还有三项非事务性要求。上面的架构图可以分解为以下三个工作流程:
-
在投诉中添加新评论时发送通知
-
对每周数据运行分析查询
-
归档超过三年的数据
让我们更深入地了解每个工作流程。
在投诉中添加新评论时发送通知
我们可以使用以下工作流程来满足这项要求:
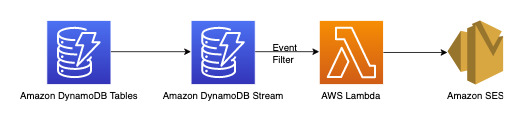
DynamoDB Streams 是一种更改数据捕获机制,用于记录 DynamoDB 表上的所有写入活动。您可以配置 Lambda 函数以触发部分或全部更改。可以在 Lambda 触发器上配置事件筛选条件,以筛选掉与应用场景无关的事件。在这种情况下,只有在添加新评论时,我们才能使用筛选条件来触发 Lambda,并将通知发送到相关电子邮件 ID(可以从 AWS Secrets Manager 或任何其他凭证存储中获取此类 ID)。
对每周数据运行分析查询
DynamoDB 适用于主要侧重于在线事务处理(OLTP)的工作负载。对于其他 10-20% 具有分析需求的访问模式,可以使用托管式导出到 Amazon S3 功能将数据导出到 S3,而不会影响 DynamoDB 表上的实时流量。看看下面的这个工作流程:
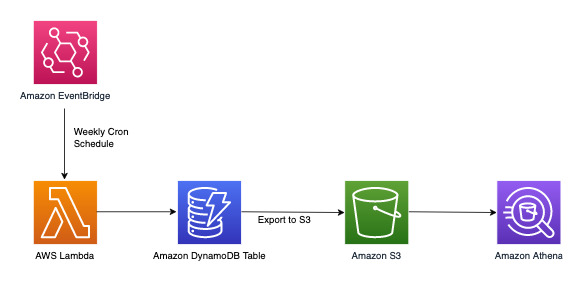
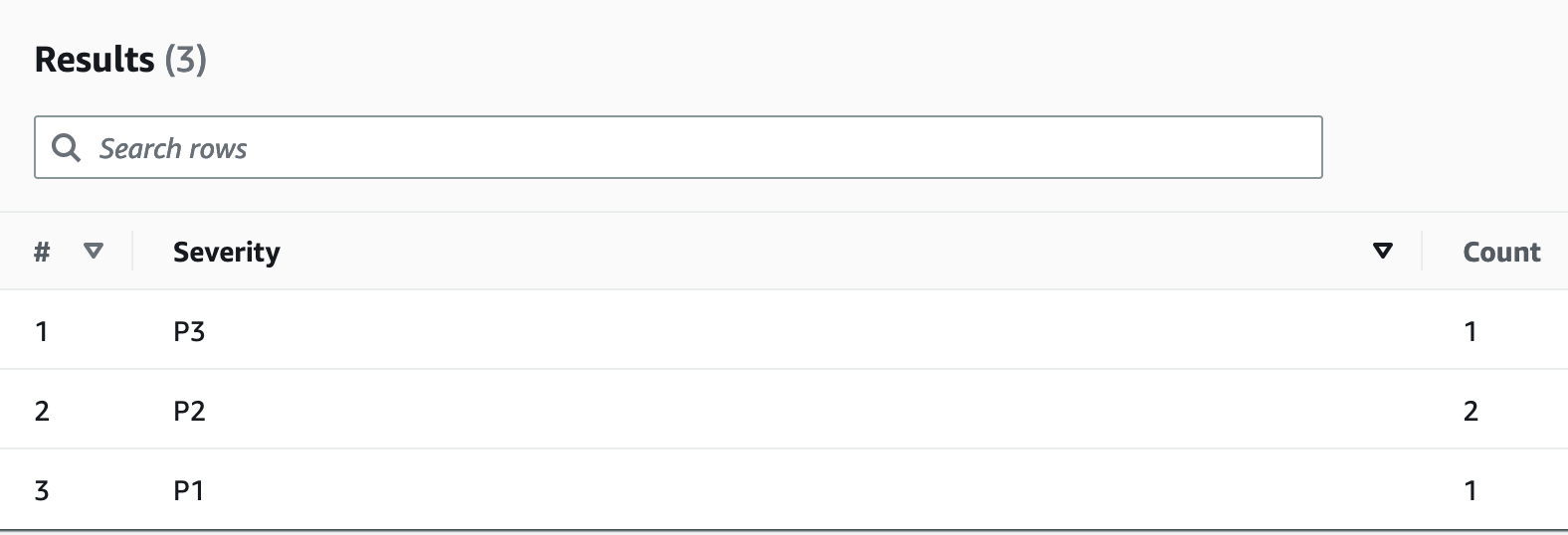
Amazon EventBridge 可用来按计划触发 AWS Lambda - 它允许您配置 cron 表达式,以便定期进行 Lambda 调用。Lambda 可以调用 ExportToS3 API 调用并在 S3 中存储 DynamoDB 数据。然后,可以通过 SQL 引擎(例如 Amazon Athena)访问此 S3 数据,以便在不影响表上的实时事务性工作负载的情况下,对 DynamoDB 数据运行分析查询。用于查找每个严重性级别的投诉数量的 Athena 查询示例如下所示:
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count" FROM "complaint_management"."data" WHERE NOT Item.severity.S = '' GROUP BY Item.severity.S ;
这将导致以下 Athena 查询结果:
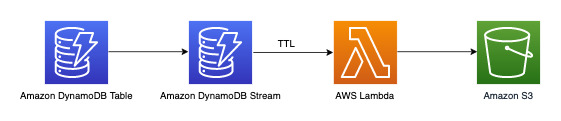
归档超过三年的数据
您可以利用 DynamoDB 生存时间(TTL)功能从 DynamoDB 表中删除过时数据,而无需任何额外费用 [2019.11.21(当前)版本的全局表副本除外,其中,复制到其他区域的 TTL 删除操作会消耗写入容量]。这些数据会出现,并且可以从 DynamoDB Streams 中使用,以归档到 Amazon S3 中。此要求的工作流程如下:
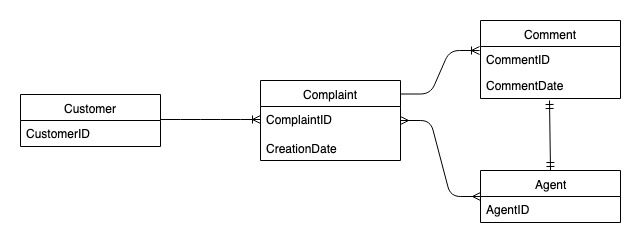
投诉管理系统实体关系图
这是我们将在投诉管理系统架构设计中使用的实体关系图(ERD)。
投诉管理系统访问模式
这些是我们将在投诉管理架构设计中考虑的访问模式。
-
createComplaint
-
updateComplaint
-
updateSeveritybyComplaintID
-
getComplaintByComplaintID
-
addCommentByComplaintID
-
getAllCommentsByComplaintID
-
getLatestCommentByComplaintID
-
getAComplaintbyCustomerIDAndComplaintID
-
getAllComplaintsByCustomerID
-
escalateComplaintByComplaintID
-
getAllEscalatedComplaints
-
getEscalatedComplaintsByAgentID(按最新到最旧排序)
-
getCommentsByAgentID(在两个日期之间)
投诉管理系统架构设计演变
由于这是一个投诉管理系统,因此大多数访问模式都围绕作为主要实体的投诉展开。ComplaintID 是高度基数的,这将确保数据在底层分区中均匀分布,也是我们识别的访问模式的最常见搜索标准。因此,ComplaintID 是该数据集中的理想分区键候选对象。
步骤 1:解决访问模式 1(createComplaint)、2(updateComplaint)、3(updateSeveritybyComplaintID)和 4(getComplaintByComplaintID)
我们可以使用名为“metadata”(或“AA”)的通用排序键值来存储特定于投诉的信息,例如 CustomerID、State、Severity 以及 CreationDate。我们对 PK=ComplaintID 和 SK=“metadata” 使用单例操作来执行以下操作:
-
使用
PutItem以创建新的投诉 -
使用
UpdateItem以更新投诉元数据中的严重性或其他字段 -
使用
GetItem以便为投诉获取元数据

步骤 2:解决访问模式 5(addCommentByComplaintID)
这种访问模式要求在投诉和投诉评论之间建立一对多关系模型。我们将在这里使用垂直分区技术来使用排序键,并创建具有不同类型数据的项目集合。如果我们看一下访问模式 6(getAllCommentsByComplaintID)和 7(getLatestCommentByComplaintID),我们就知道评论需要按时间排序。我们也可以同时发表多条评论,这样我们就可以使用复合排序键技术,以便在排序键属性中追加时间和 CommentID。
处理此类可能的评论冲突的其他选择是增加时间戳的粒度,或添加一个增量数字作为后缀,而不是使用 Comment_ID。在这种情况下,我们将为与评论对应的项目的排序键值加上“comm#”前缀,以启用基于范围的操作。
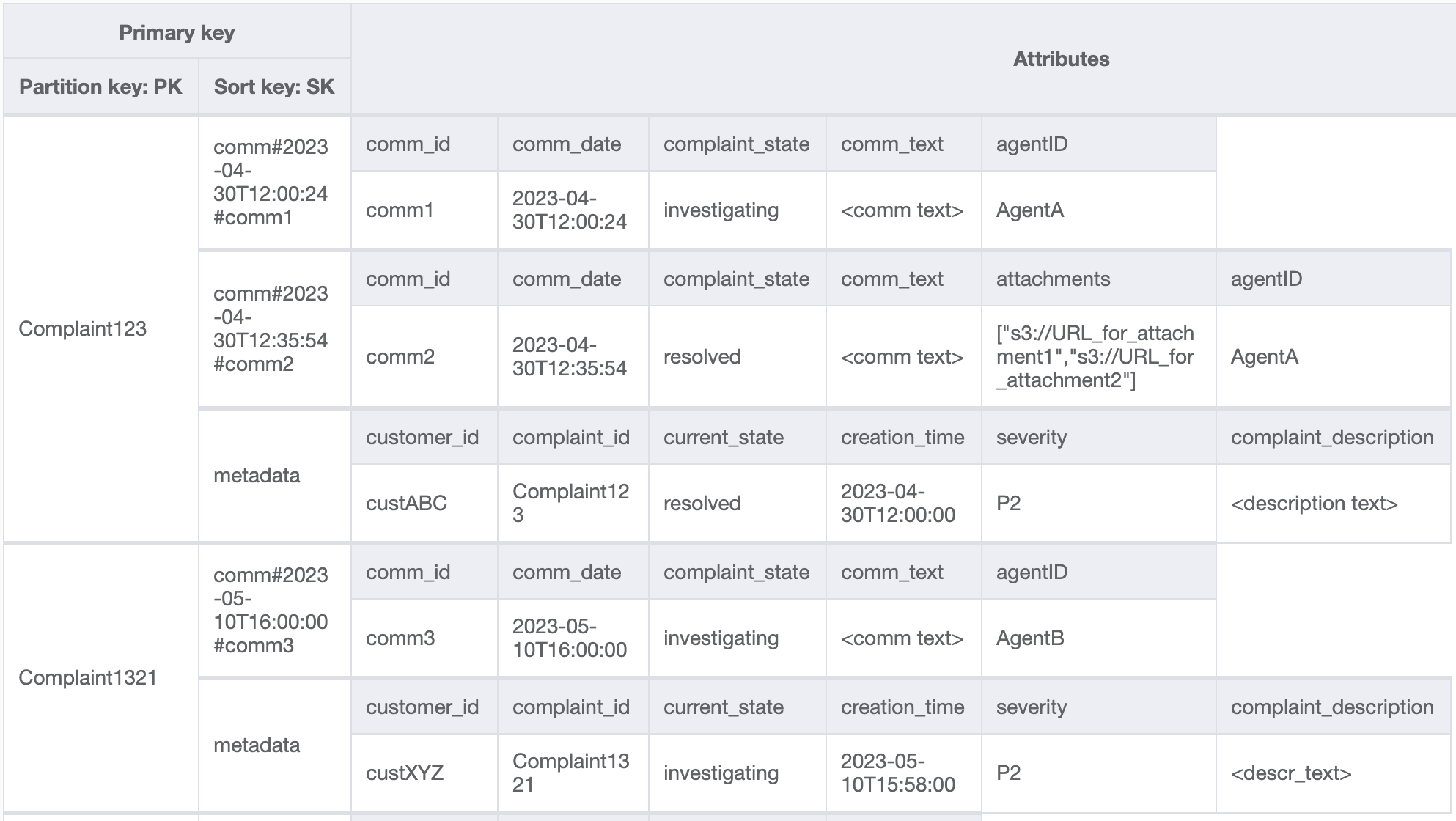
我们还需要确保投诉元数据中的 currentState 反映添加新评论时的状态。添加评论可能表明投诉已分配给客服坐席或已得到解决,诸如此类。为了以要么全有、要么全无的方式在投诉元数据中捆绑注释的添加和当前状态的更新,我们将使用 TransactWriteItems API。生成的表状态现在如下所示:

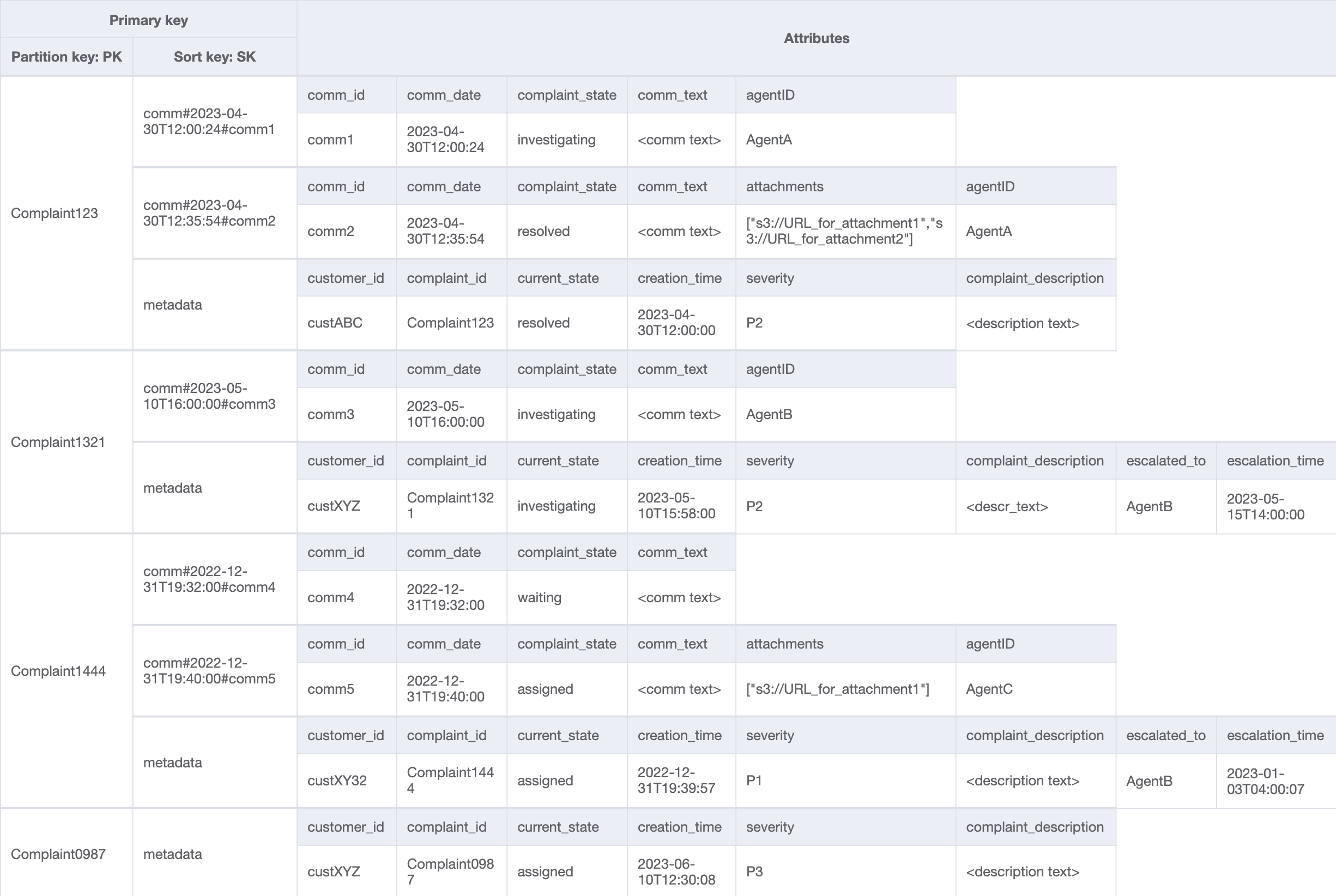
让我们在表中添加一些更多数据,并将 ComplaintID 作为 PK 中的一个单独字段添加,以便在 ComplaintID 上需要额外索引的情况下对模型进行未来验证。另请注意,一些评论可能有附件,我们会将其存储在 Amazon Simple Storage Service 中,仅在 DynamoDB 中保留其引用或 URL。保持事务数据库尽可能精简以优化成本和性能是一种最佳实践。现在的数据如下所示:
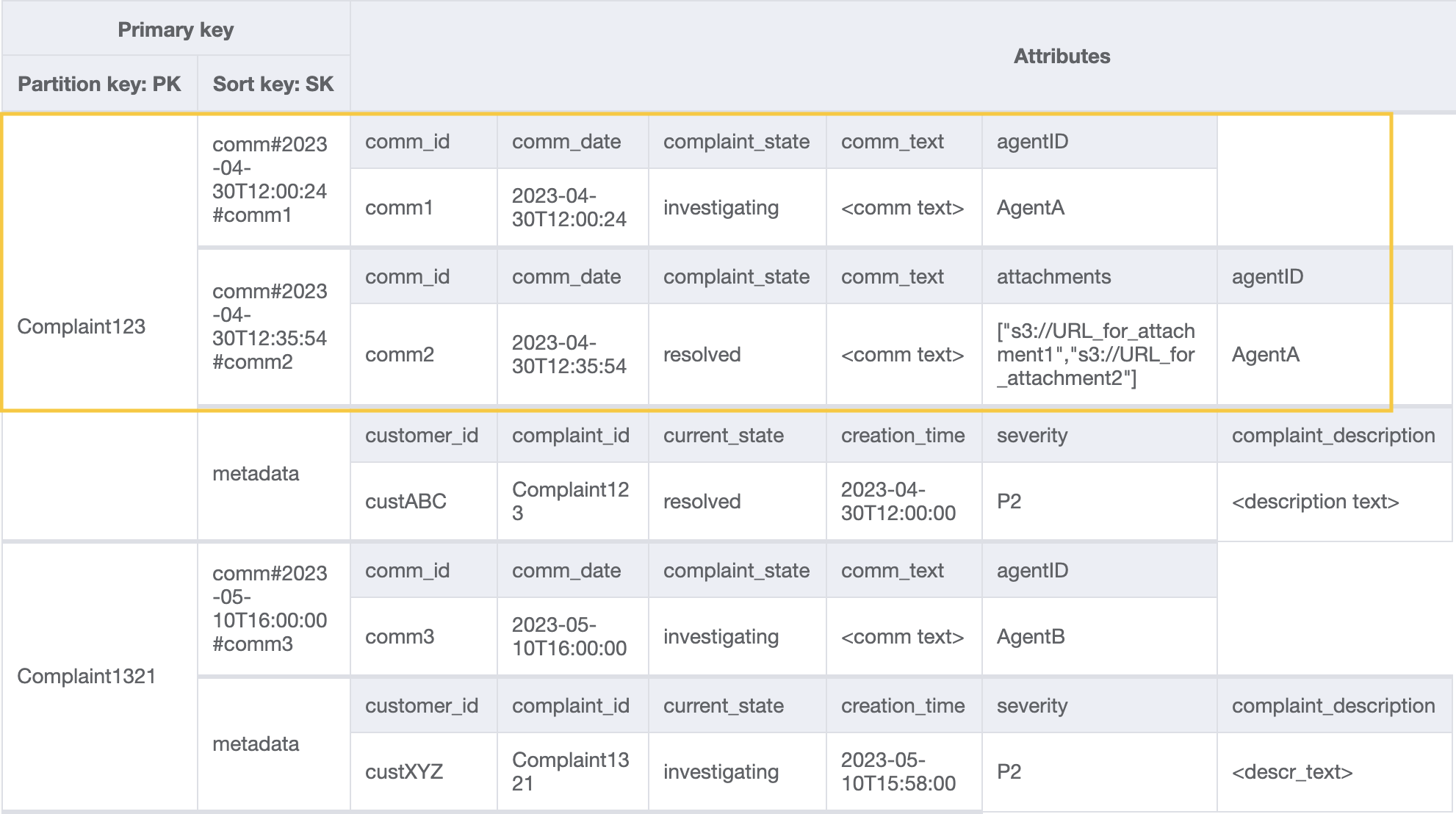
步骤 3:解决访问模式 6(getAllCommentsByComplaintID)和 7(getLatestCommentByComplaintID)
为了获得某个投诉的所有评论,我们可以对排序键使用具有 begins_with 条件的 query 操作。使用这样的排序键条件可以帮助我们只读取所需的内容,而不是消耗额外的读取容量来读取元数据条目,然后承担筛选相关结果的开销。例如,具有 PK=Complaint123 和 SK begins_with comm# 的查询操作将返回以下内容,同时跳过元数据条目:
由于我们在模式 7(getLatestCommentByComplaintID)中需要投诉的最新评论,让我们使用另外两个查询参数:
-
ScanIndexForward应设置为 False 以获得按降序排序的结果 -
Limit应设置为 1 以获得最新的(只有一个)评论
类似于访问模式 6(getAllCommentsByComplaintID),我们使用 begins_with comm# 作为排序键条件来跳过元数据条目。现在,您可以将查询操作与 PK=Complaint123 和 SK=begins_with comm#、ScanIndexForward=False 和 Limit 1 结合使用,在此设计上执行访问模式 7。结果将返回以下目标项目:
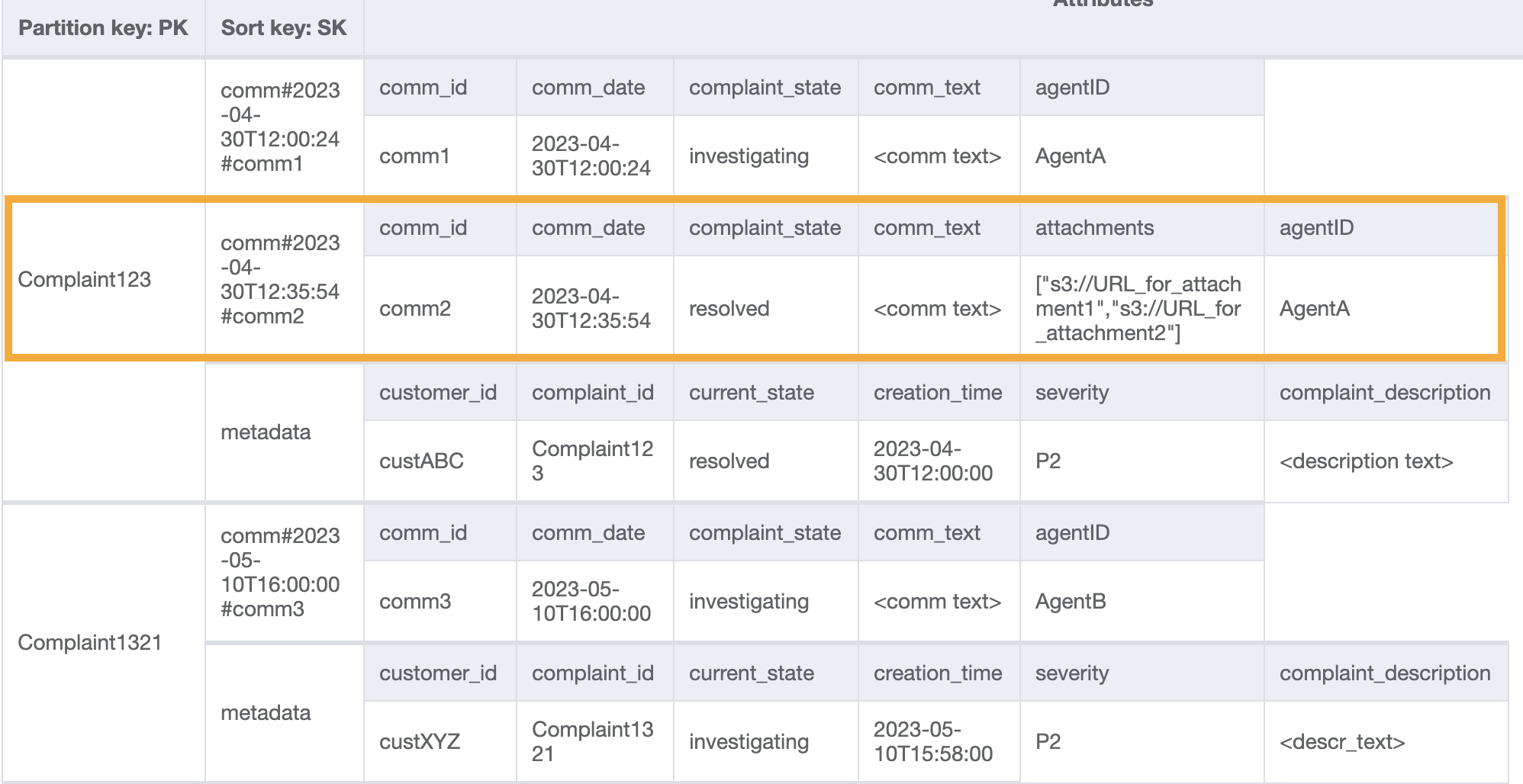
让我们向表中添加更多虚拟数据。
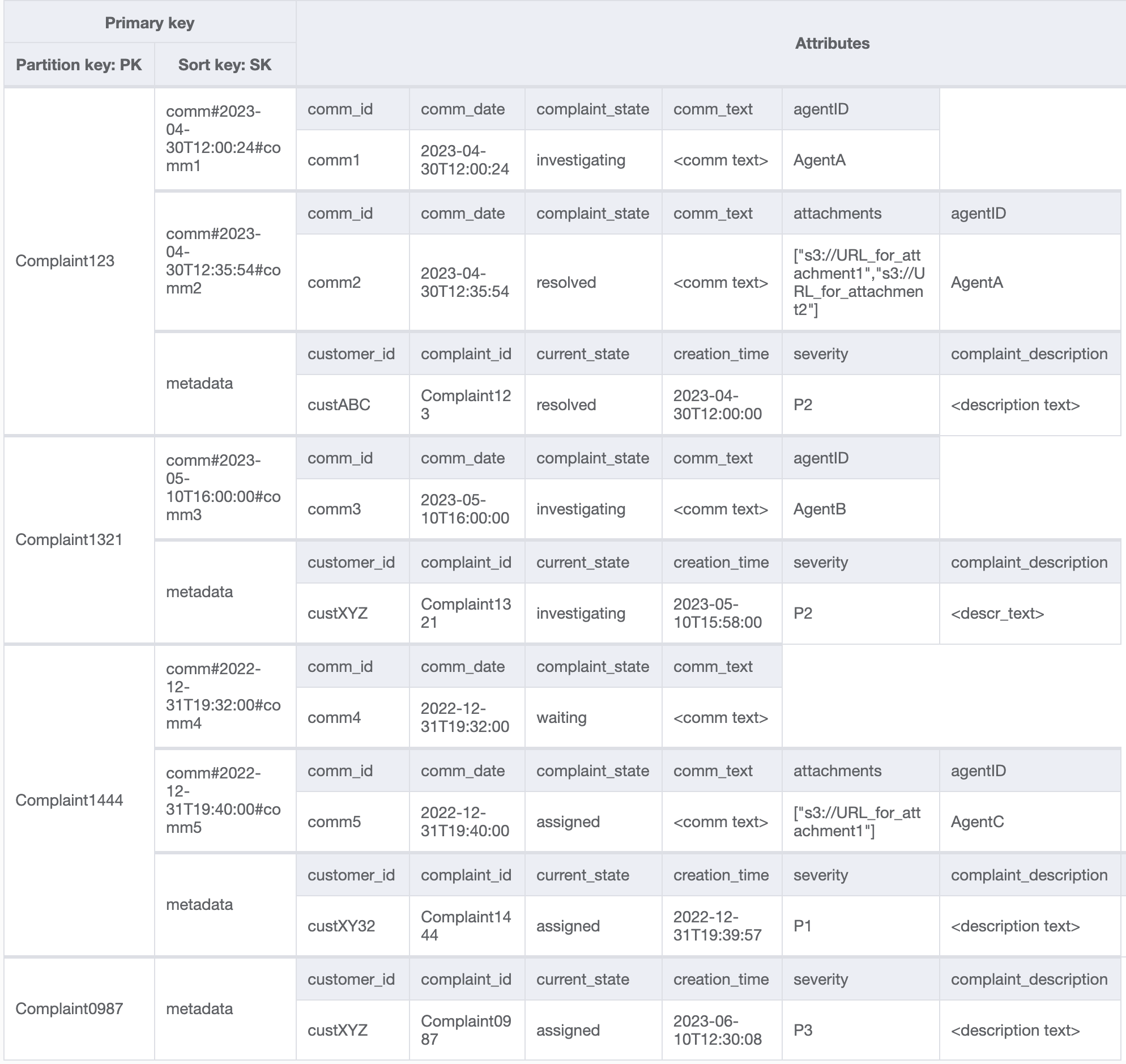
步骤 4:解决访问模式 8(getAComplaintbyCustomerIDAndComplaintID)和 9(getAllComplaintsByCustomerID)
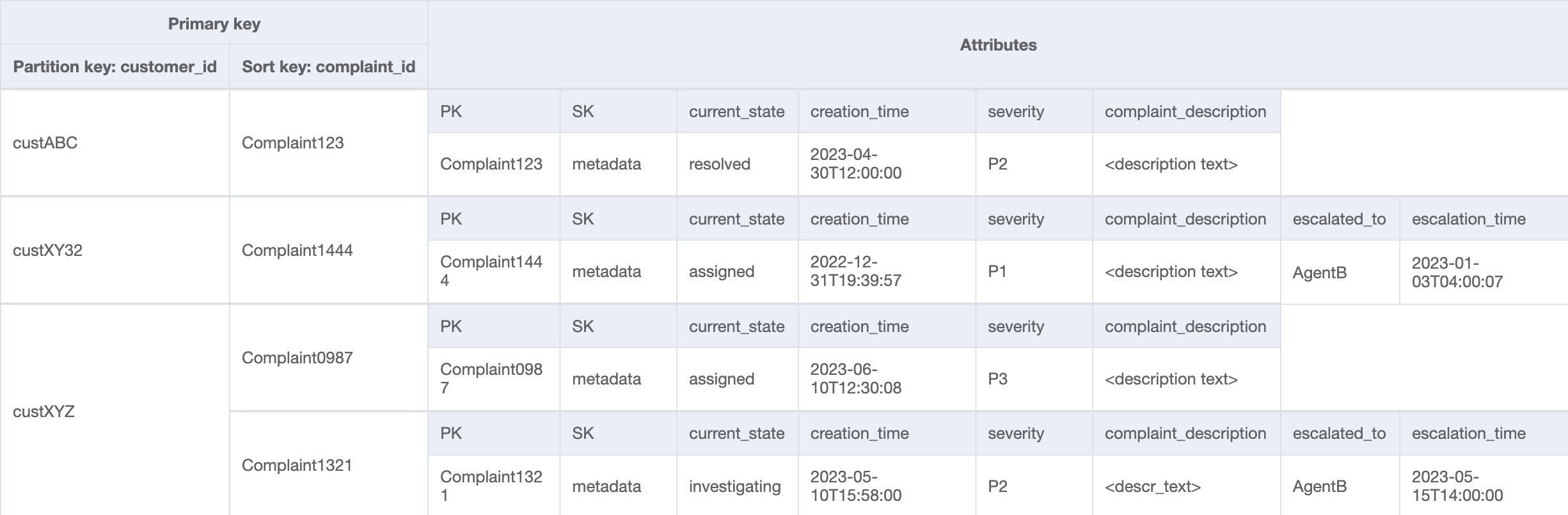
访问模式 8 (getAComplaintbyCustomerIDAndComplaintID) 和 9 (getAllComplaintsByCustomerID) 引入了新的搜索条件:CustomerID。从现有表中提取它需要执行昂贵的 Scan 来读取所有数据,然后针对相关的 CustomerID 筛选相关项目。我们可以通过创建一个以 CustomerID 为分区键的全局二级索引(GSI)来提高搜索效率。记住客户和投诉之间的一对多关系以及访问模式 9(getAllComplaintsByCustomerID),ComplaintID 将是排序键的正确候选对象。
GSI 中的数据将如下所示:
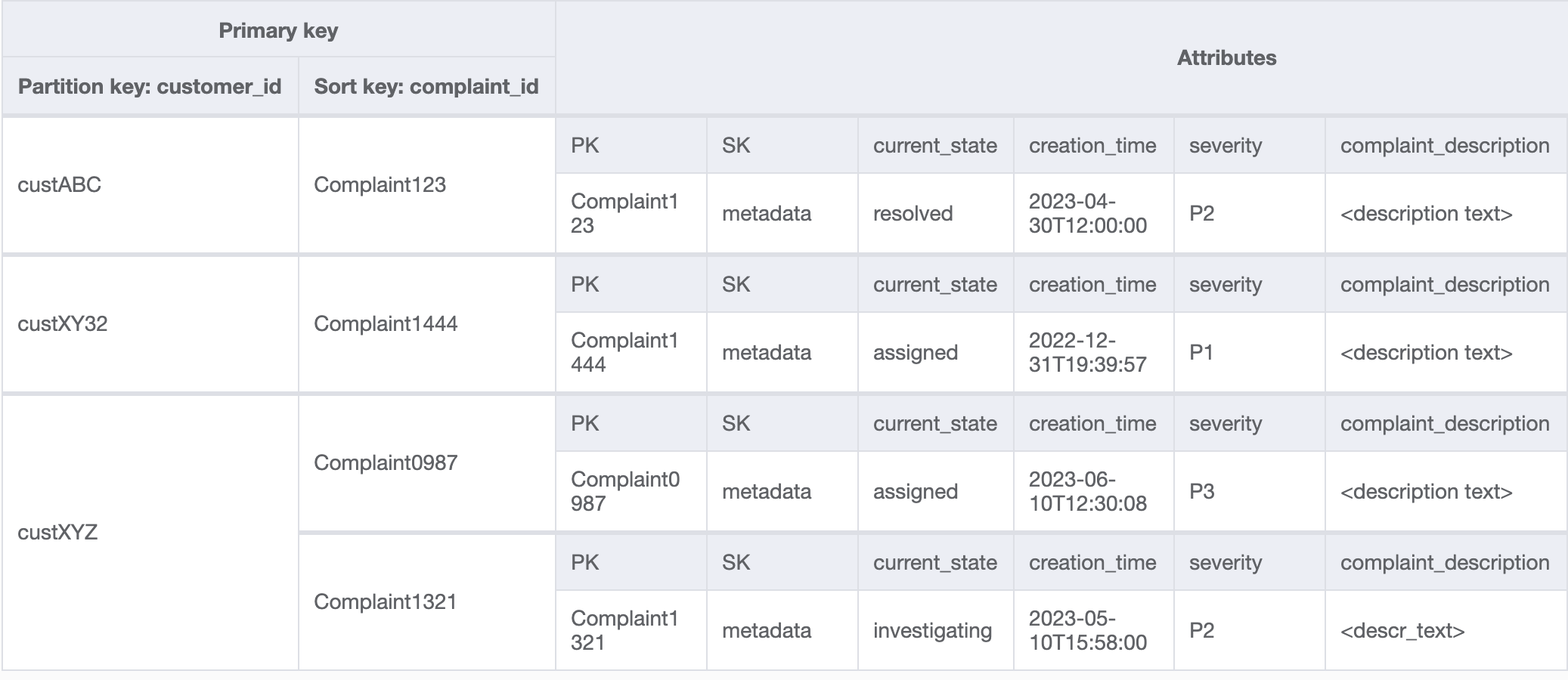
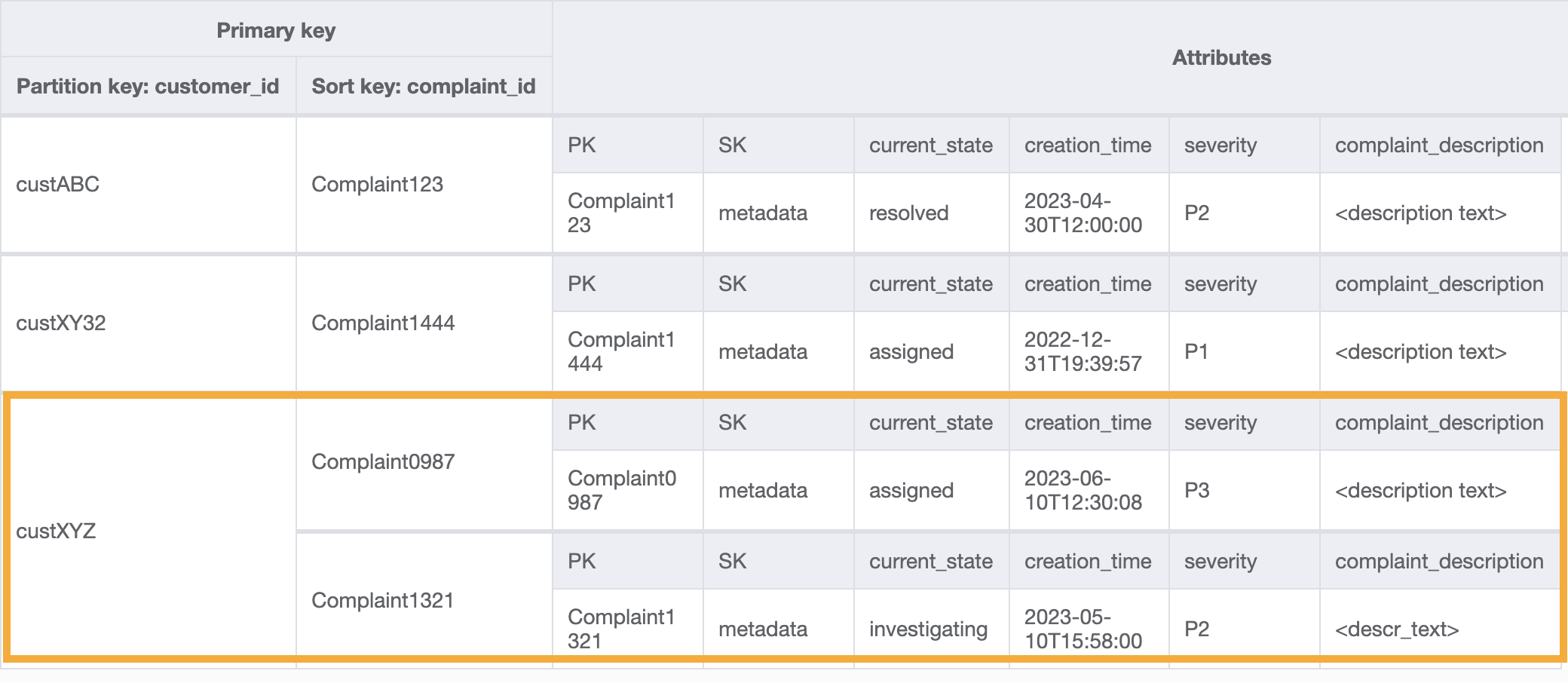
此 GSI 上用于访问模式 8(getAComplaintbyCustomerIDAndComplaintID)的查询示例将是:customer_id=custXYZ、sort key=Complaint1321。结果将是:
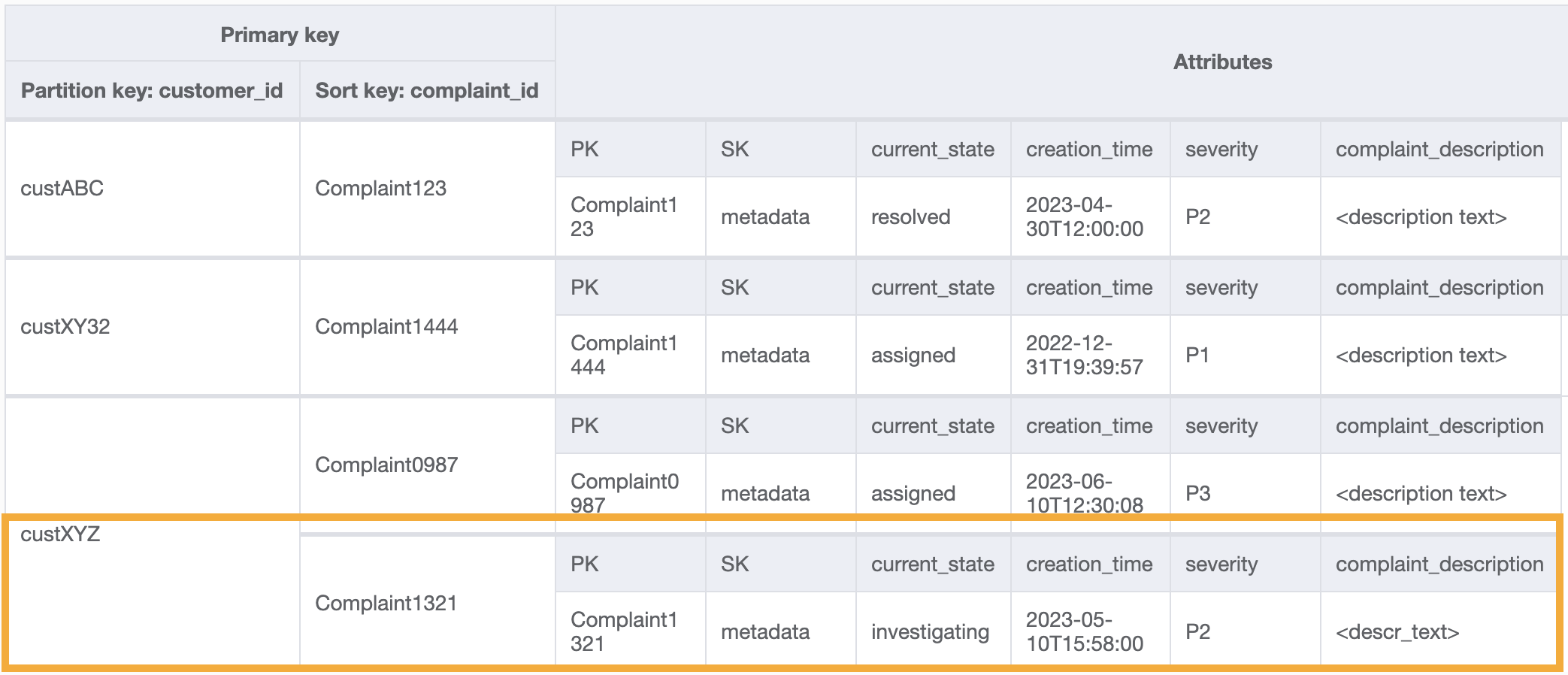
获取客户对访问模式 9(getAllComplaintsByCustomerID)的所有投诉,GSI 上的查询将是:customer_id=custXYZ 作为分区键条件。结果将是:
步骤 5:解决访问模式 10(escalateComplaintByComplaintID)
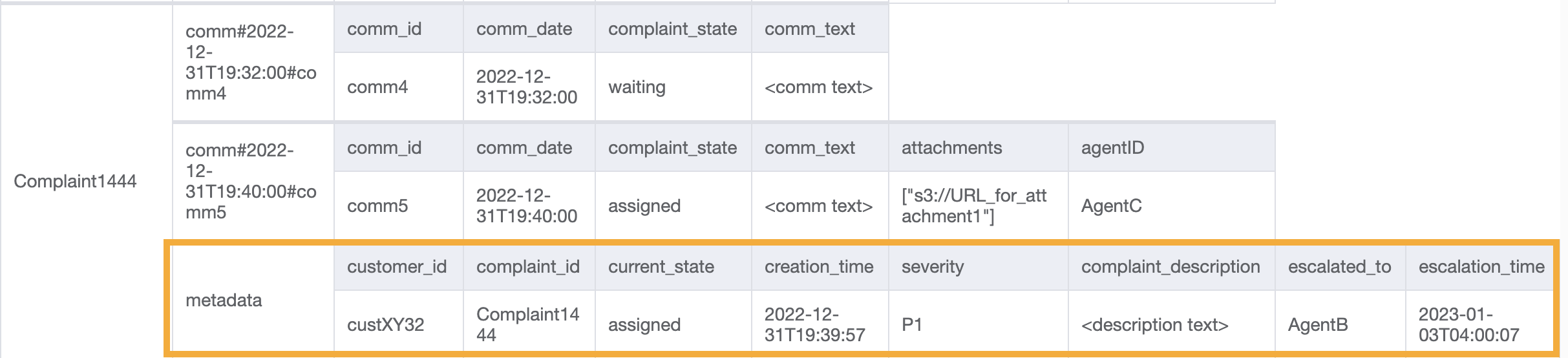
这种访问引入了上报环节。要上报投诉,我们可以使用 UpdateItem 来将属性(例如 escalated_to 和 escalation_time)添加到现有的投诉元数据项目。DynamoDB 提供灵活的架构设计,这意味着一组非关键属性在不同的项目之间可以是统一的或离散的。有关示例,请参阅以下内容:
UpdateItem with PK=Complaint1444, SK=metadata
步骤 6:解决访问模式 11(getAllEscalatedComplaints)和 12(getEscalatedComplaintsByAgentID)
预计整个数据集中只有少数投诉会上报。因此,对上报相关属性创建索引将带来高效的查找以及经济高效的 GSI 存储。我们可以利用稀疏索引技术来实现这一目标。分区键为 escalated_to 且排序键为 escalation_time 的 GSI 看起来像这样:

要获取所有针对访问模式 11(getAllEscalatedComplaints)的上报投诉,我们只需扫描这个 GSI 即可。请注意,由于 GSI 的大小,此扫描将具有高性能和成本效益。为了获得针对特定客服坐席的上报投诉 [访问模式 12(getEscalatedComplaintsByAgentID)],分区键将为 escalated_to=agentID,并且我们将 ScanIndexForward 设置为 False,以便按最新到最旧排序。
步骤 7:解决访问模式 13(getCommentsByAgentID)
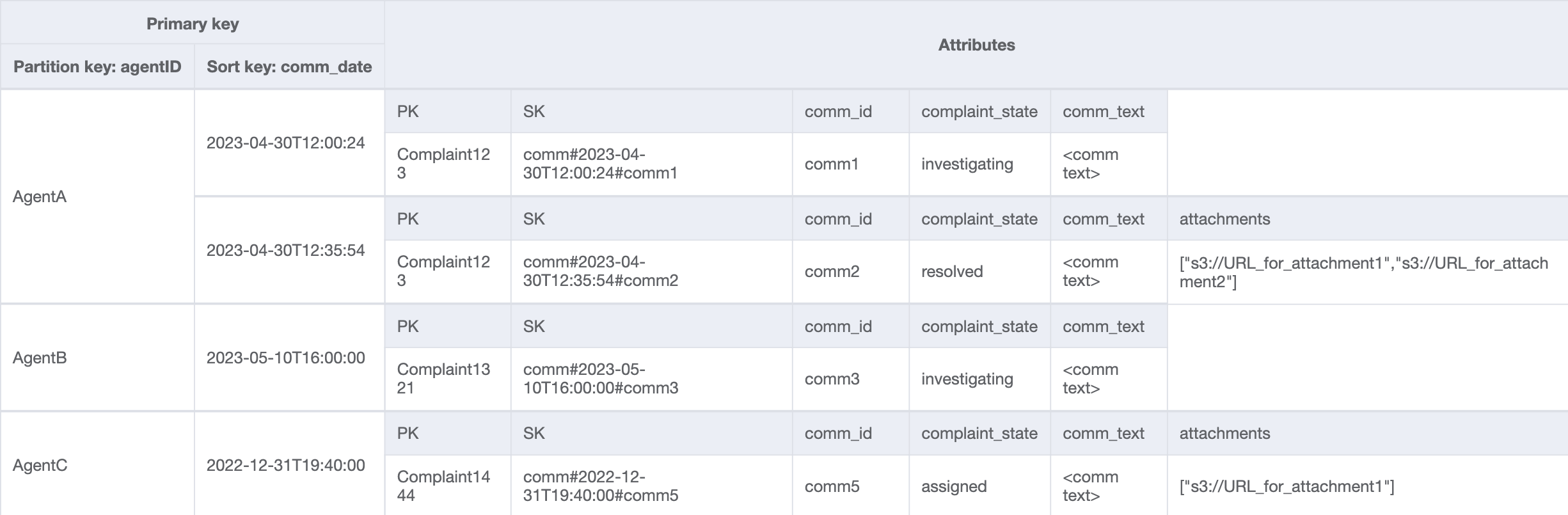
对于最后一个访问模式,我们需要按新维度进行查找:AgentID。我们还需要基于时间的排序来读取两个日期之间的评论,所以我们以 agent_id 作为分区键并以 comm_date 作为排序键创建一个 GSI。此 GSI 中的数据将如下所示:
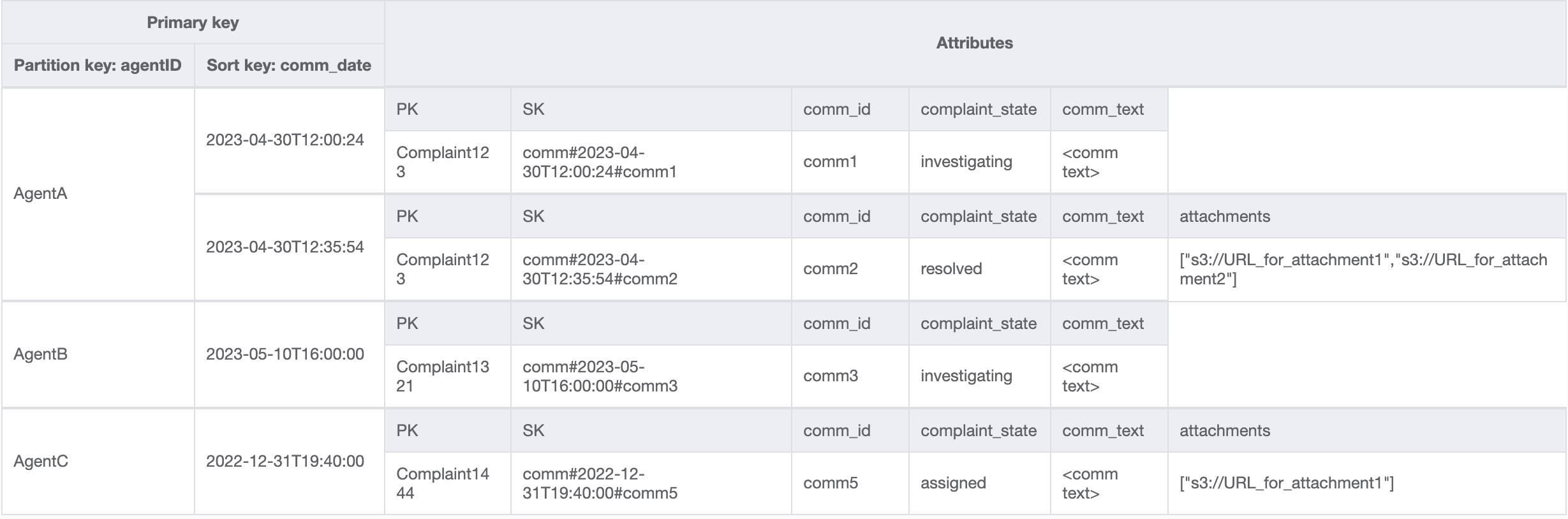
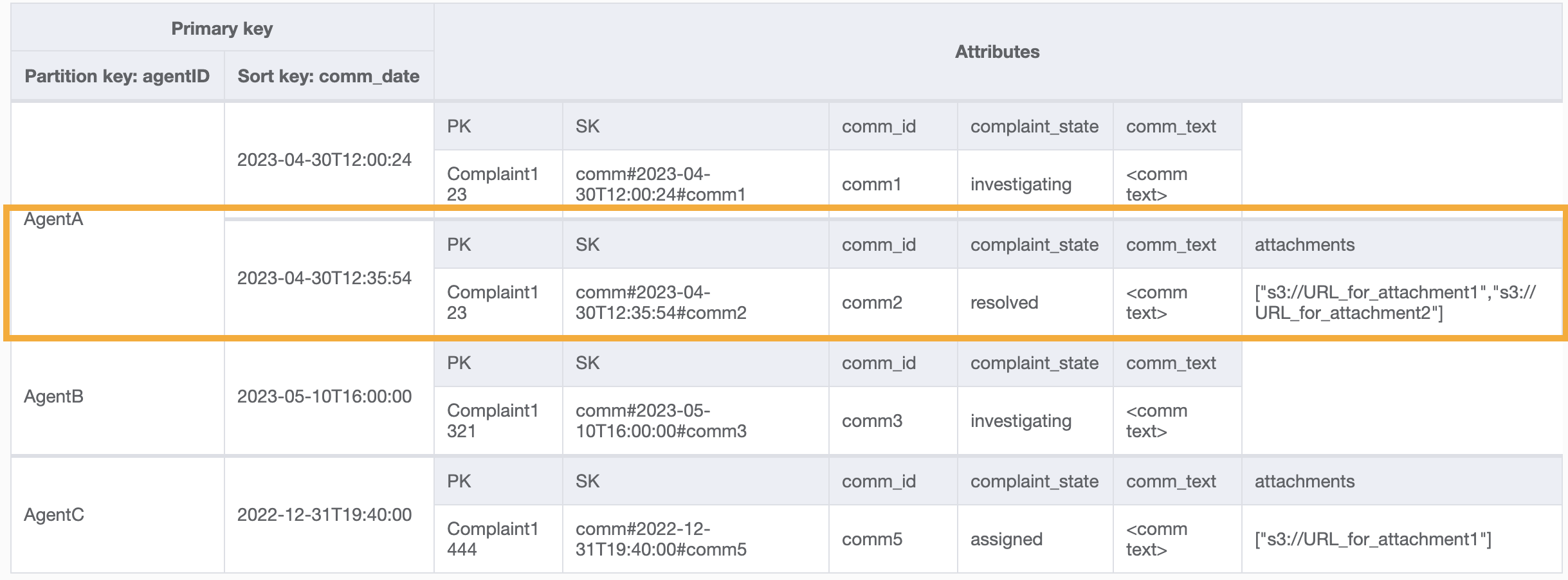
此 GSI 上的查询示例是 partition key agentID=AgentA 和 sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00),其结果是:
下表总结了所有访问模式以及架构设计如何解决访问模式:
| 访问模式 | 基表/GSI/LSI | 操作 | 分区键值 | 排序键值 | 其他条件/筛选条件 |
|---|---|---|---|---|---|
| createComplaint | 基表 | PutItem | PK=complaint_id | SK=metadata | |
| updateComplaint | 基表 | UpdateItem | PK=complaint_id | SK=metadata | |
| updateSeveritybyComplaintID | 基表 | UpdateItem | PK=complaint_id | SK=metadata | |
| getComplaintByComplaintID | 基表 | GetItem | PK=complaint_id | SK=metadata | |
| addCommentByComplaintID | 基表 | TransactWriteItems | PK=complaint_id | SK=metadata,SK=comm#comm_date#comm_id | |
| getAllCommentsByComplaintID | 基表 | Query | PK=complaint_id | SK begins_with "comm#" | |
| getLatestCommentByComplaintID | 基表 | Query | PK=complaint_id | SK begins_with "comm#" | scan_index_forward=False,Limit 1 |
| getAComplaintbyCustomerIDAndComplaintID | Customer_complaint_GSI | 查询 | customer_id=customer_id | complaint_id = complaint_id | |
| getAllComplaintsByCustomerID | Customer_complaint_GSI | 查询 | customer_id=customer_id | 不适用 | |
| escalateComplaintByComplaintID | 基表 | UpdateItem | PK=complaint_id | SK=metadata | |
| getAllEscalatedComplaints | Escalations_GSI | Scan | 不适用 | 不适用 | |
| getEscalatedComplaintsByAgentID(按最新到最旧排序) | Escalations_GSI | 查询 | escalated_to=agent_id | 不适用 | scan_index_forward=False |
| getCommentsByAgentID(在两个日期之间) | Agents_Comments_GSI | 查询 | agent_id=agent_id | SK between (date1, date2) |
投诉管理系统最终架构
这是最终的架构设计。要以 JSON 文件格式下载此架构设计,请参阅 GitHub 上的 DynamoDB 示例
基表
Customer_Complaint_GSI
Escalations_GSI

Agents_Comments_GSI
在此架构设计中使用 NoSQL Workbench
若要进一步探索和编辑新项目,您可以将此最终架构导入到 NoSQL Workbench,这是一款为 DynamoDB 提供数据建模、数据可视化和查询开发功能的可视化工具。请按照以下步骤开始使用:
-
下载 NoSQL Workbench。有关更多信息,请参阅 下载 NoSQL Workbench for DynamoDB。
-
下载上面列出的 JSON 架构文件,该文件已经采用 NoSQL Workbench 模型格式。
-
将 JSON 架构文件导入到 NoSQL Workbench。有关更多信息,请参阅 导入现有数据模型。
-
导入到 NOSQL Workbench 后,您便可编辑数据模型。有关更多信息,请参阅 编辑现有数据模型。
