在 DynamoDB 中监控设备状态更新
此使用案例讨论使用 DynamoDB 来监控 DynamoDB 中的设备状态更新(或设备状态更改)。
使用案例
在 IoT 使用案例(例如智能工厂)中,许多设备需要由操作员监控,它们会定期将其状态或日志发送到监控系统。当设备出现问题时,该设备的状态会从正常更改为警告。根据设备中异常行为的严重程度和类型,日志级别或状态会有所不同。然后,系统会指派一名操作员检查设备,如果需要,操作员可以将问题上报给主管。
此系统的一些典型访问模式包括:
-
为设备创建日志条目
-
获取特定设备状态的所有日志,首先显示最新的日志
-
获取给定操作员在两个日期之间的所有日志
-
获取向给定主管上报的所有日志
-
获取向给定主管上报的带有特定设备状态的所有日志
-
获取特定日期向给定主管上报的带有特定设备状态的所有日志
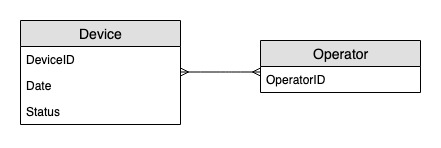
实体关系图
这是我们将用于监控设备状态更新的实体关系图(ERD)。
访问模式
这些是我们将考虑用于监控设备状态更新的访问模式。
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
架构设计的演变
步骤 1:解决访问模式 1(createLogEntryForSpecificDevice)和 2(getLogsForSpecificDevice)
设备跟踪系统的扩展单位将是各个设备。在该系统中,deviceID 唯一地标识设备。这使得 deviceID 成为分区键的出色候选者。每个设备都会定期(比如每五分钟左右)向跟踪系统发送信息。这种排序使日期成为逻辑排序标准,因此成为排序键。本案例中的示例数据如下所示:
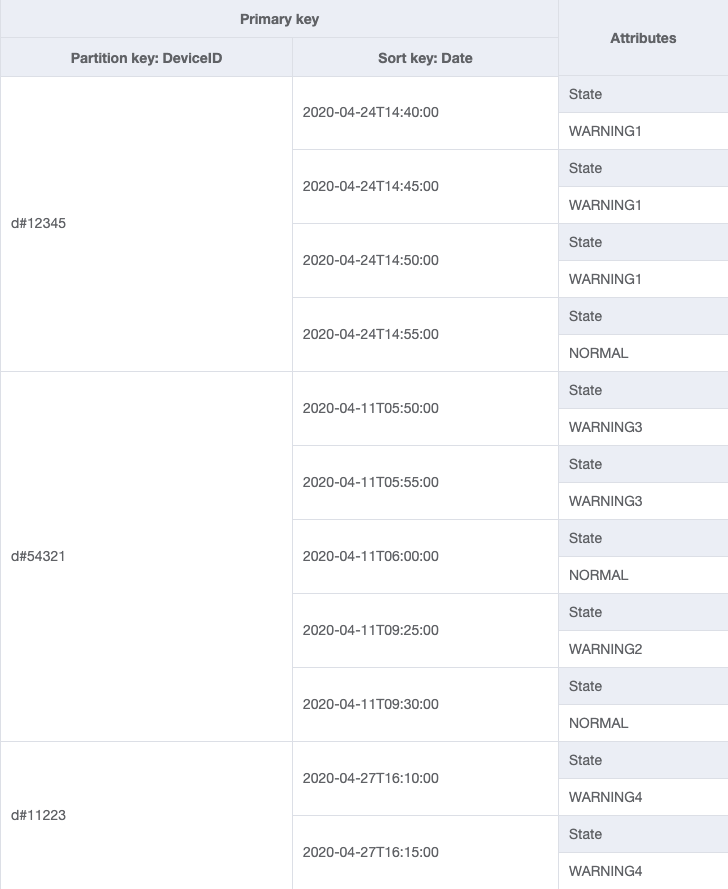
要获取特定设备的日志条目,我们可以使用分区键 DeviceID="d#12345" 执行查询操作。
步骤 2:解决访问模式 3(getWarningLogsForSpecificDevice)
由于 State 是一个非键属性,因此,使用当前架构解决访问模式 3 将需要一个筛选表达式。在 DynamoDB 中,筛选表达式是在使用键条件表达式读取数据之后应用的。例如,如果我们要获取 d#12345 的警告日志,那么分区键为 DeviceID="d#12345" 的查询操作将从上表中读取四个项目,然后筛选出一个没有警告状态的项目。这种方法在规模较大时效率不高。如果所排除的项目的比率较低或查询不频繁执行,则筛选表达式可能是一种排除所查询的项目的好方法。但是,对于从表中检索到许多项目并且大多数项目被筛选掉的情况,我们可以继续改进我们的表设计,使其运行效率更高。
让我们通过使用复合排序键来更改处理这种访问模式的方式。您可以从 DeviceStateLog_3.jsonState#Date。此排序键是属性 State、# 和 Date 的组合。在本例中,# 用作分隔符。数据现在如下所示:
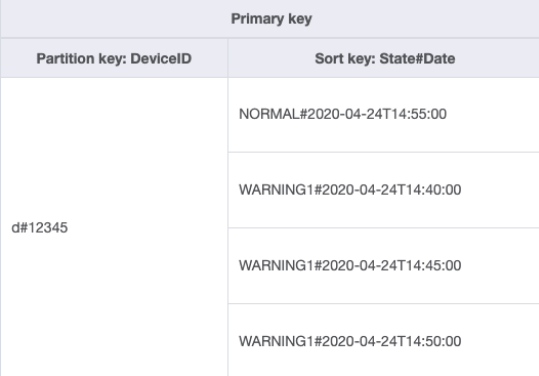
要仅获取设备的警告日志,则使用此架构可以使查询更具针对性。查询的键条件使用分区键 DeviceID="d#12345" 和排序键 State#Date begins_with
“WARNING”。此查询将只读取具有警告状态的相关三个项目。
步骤 3:解决访问模式 4(getLogsForOperatorBetweenTwoDates)
您可以导入 DeviceStateLog_4.jsonOperator 属性已添加到带有示例数据的 DeviceStateLog 表中。
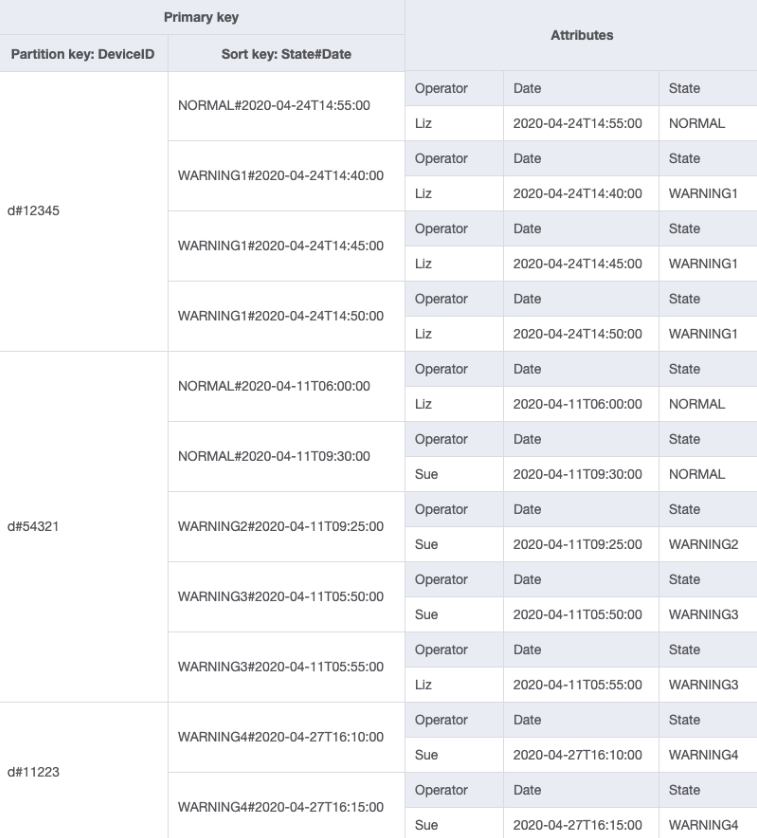
由于 Operator 当前不是分区键,因此无法基于 OperatorID 对该表执行直接键/值查找。我们需要在 OperatorID 上创建一个具有全局二级索引的新项目集合。访问模式需要基于日期的查找,因此 Date 是全局二级索引(GSI)的排序键属性。这就是 GSI 现在的样子:
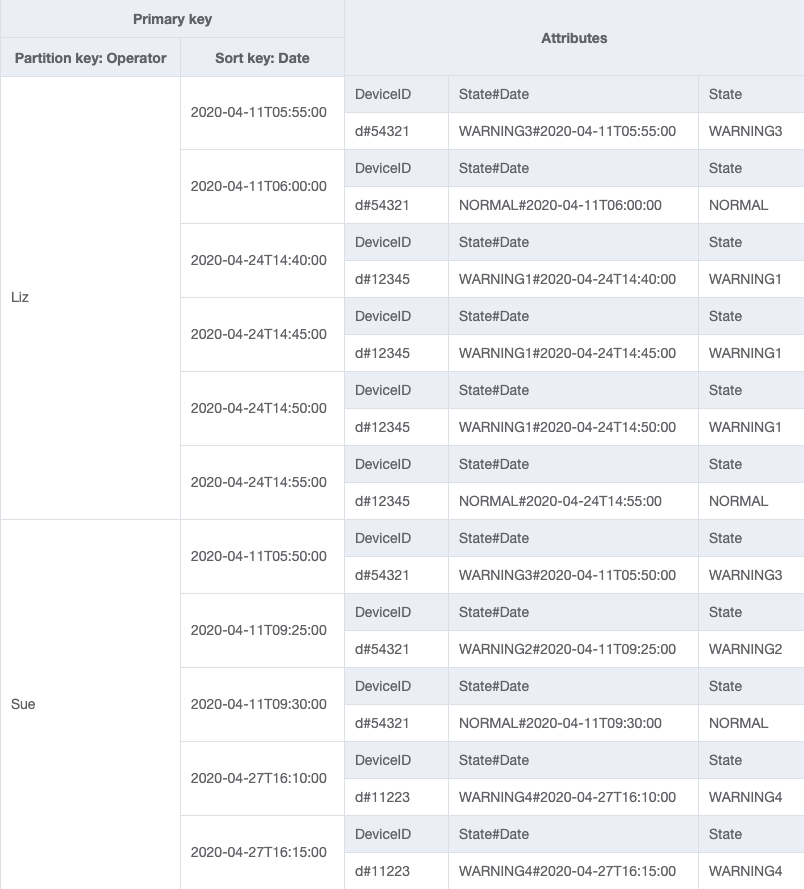
对于访问模式 4(getLogsForOperatorBetweenTwoDates),您可以在 2020-04-11T05:58:00 和 2020-04-24T14:50:00 之间使用分区键 OperatorID=Liz 和排序键 Date 来查询此 GSI。
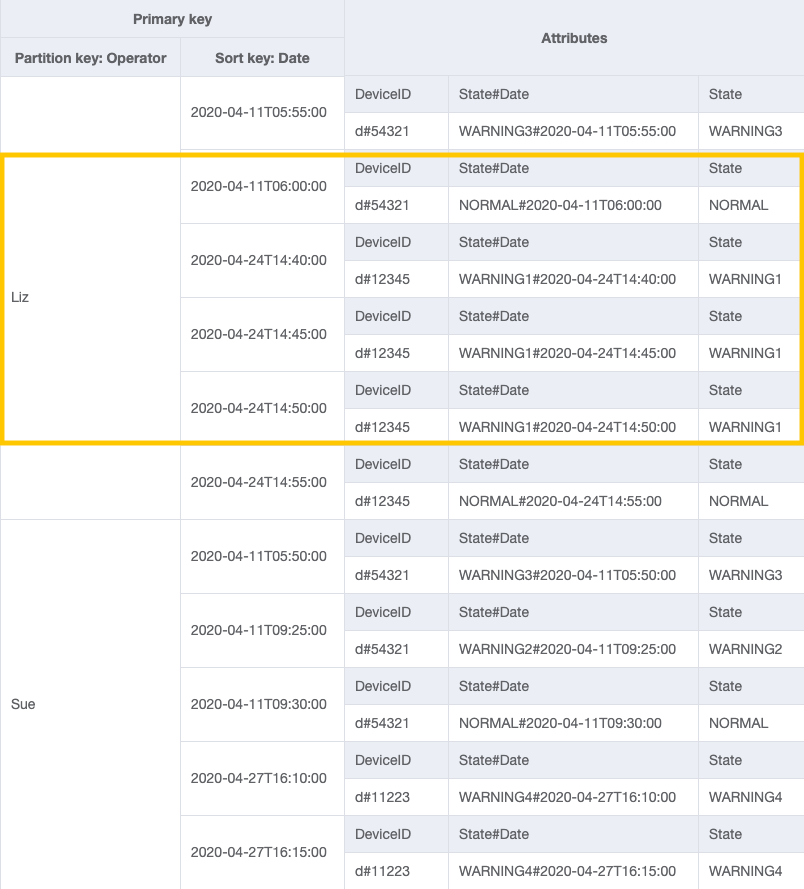
步骤 4:解决访问模式 5(getEscalatedLogsForSupervisor)、6(getEscalatedLogsWithSpecificStatusForSupervisor)和 7(getEscalatedLogsWithSpecificStatusForSupervisorForDate)
我们将使用稀疏索引来解决这些访问模式。
原定设置情况下,全局二级索引是稀疏索引,因此,只有基表中包含索引的主键属性的项目才会实际出现在索引中。这是排除与正在建模的访问模式无关的项目的另一种方法。
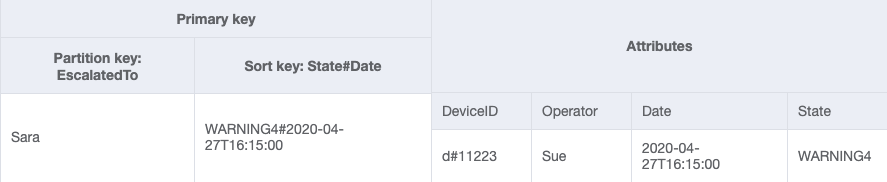
您可以导入 DeviceStateLog_6.jsonEscalatedTo 属性已添加到带有示例数据的 DeviceStateLog 表中。如前所述,并非所有日志都会上报给主管。
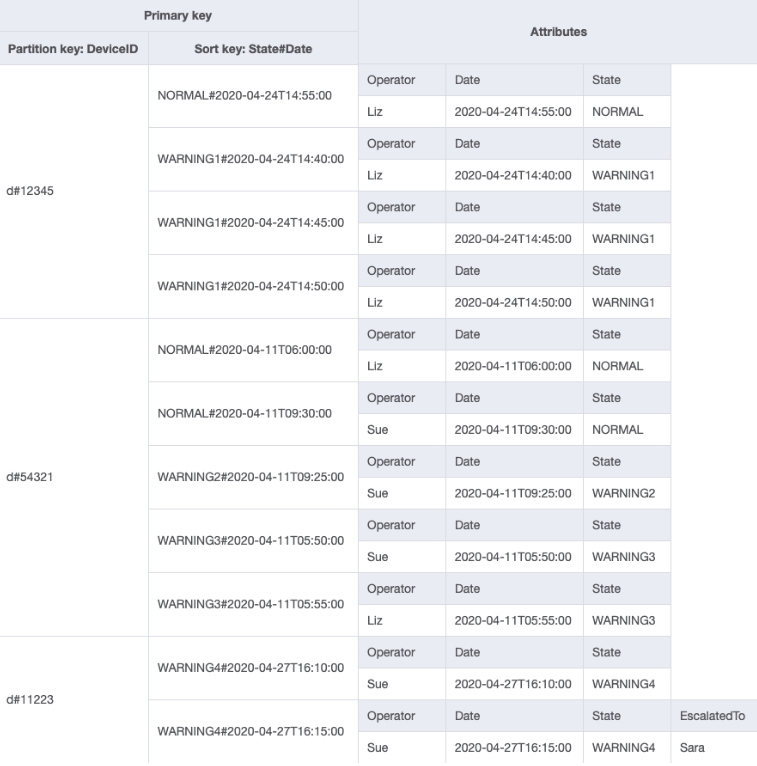
现在可以创建一个新的 GSI,其中 EscalatedTo 是分区键,State#Date 是排序键。请注意,只有同时具有 EscalatedTo 和 State#Date 属性的项目才会出现在索引中。

其余的访问模式汇总如下:
下表总结了所有访问模式以及架构设计如何解决访问模式:
| 访问模式 | 基表/GSI/LSI | 操作 | 分区键值 | 排序键值 | 其他条件/筛选条件 |
|---|---|---|---|---|---|
| createLogEntryForSpecificDevice | 基表 | PutItem | DeviceID=deviceId | State#Date=state#date | |
| getLogsForSpecificDevice | 基表 | Query | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = False |
| getWarningLogsForSpecificDevice | 基表 | Query | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| getLogsForOperatorBetweenTwoDates | GSI-1 | 查询 | Operator=operatorName | date1 和 date2 之间的日期 | |
| getEscalatedLogsForSupervisor | GSI-2 | 查询 | EscalatedTo=supervisorName | ||
| getEscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | 查询 | EscalatedTo=supervisorName | State#Date begins_with "state1#" | |
| getEscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | 查询 | EscalatedTo=supervisorName | State#Date begins_with "state1#date1" |
最终架构
这是最终的架构设计。要以 JSON 文件格式下载此架构设计,请参阅 GitHub 上的 DynamoDB 示例
基表
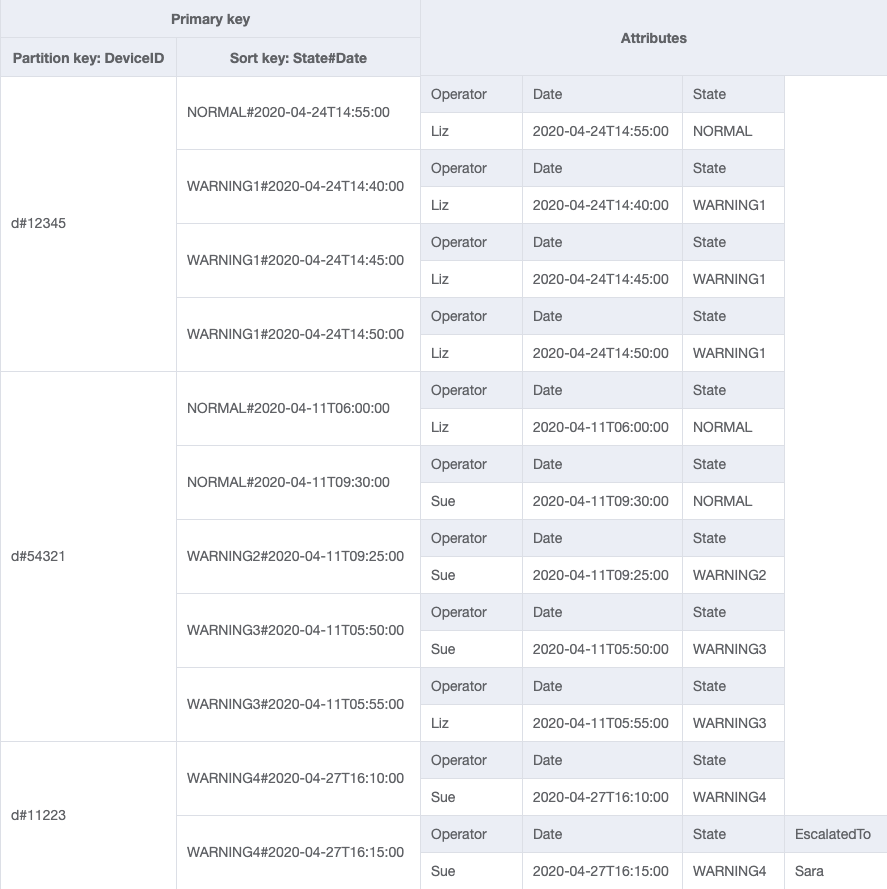
GSI-1
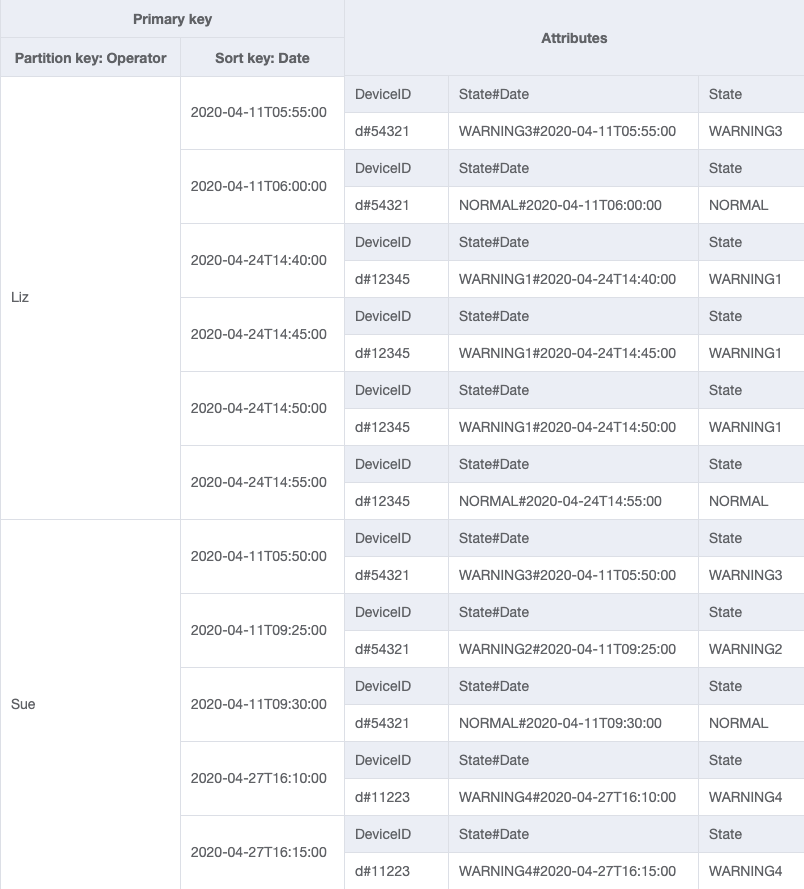
GSI-2
在此架构设计中使用 NoSQL Workbench
若要进一步探索和编辑新项目,您可以将此最终架构导入到 NoSQL Workbench,这是一款为 DynamoDB 提供数据建模、数据可视化和查询开发功能的可视化工具。请按照以下步骤开始使用:
-
下载 NoSQL Workbench。有关更多信息,请参阅 下载 NoSQL Workbench for DynamoDB。
-
下载上面列出的 JSON 架构文件,该文件已经采用 NoSQL Workbench 模型格式。
-
将 JSON 架构文件导入到 NoSQL Workbench。有关更多信息,请参阅 导入现有数据模型。
-
导入到 NOSQL Workbench 后,您便可编辑数据模型。有关更多信息,请参阅 编辑现有数据模型。
