DynamoDB 中的社交网络架构设计
社交网络业务使用场景
此使用场景探讨如何将 DynamoDB 用于社交网络。社交网络是一种在线服务,让不同的用户可以彼此互动。我们设计的社交网络将提供一个时间线供用户查看,其中包括他们的帖子、他们的粉丝、他们关注的人以及他们关注的人的发帖。此架构设计的访问模式为:
-
获取给定 userID 的用户信息
-
获取给定 userID 的粉丝名单
-
获取给定 userID 的关注名单
-
获取给定 userID 的帖子列表
-
获取给定 postID 中喜欢该帖子的用户名单
-
获取给定 postID 的点赞次数
-
获取给定 userID 的时间线
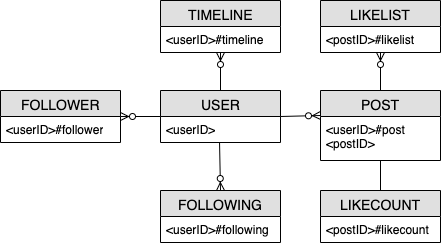
社交网络实体关系图
这是我们在社交网络架构设计中使用的实体关系图 (ERD, Entity Relationship Diagram)。
社交网络访问模式
我们将为社交网络架构设计考虑这些访问模式。
-
getUserInfoByUserID -
getFollowerListByUserID -
getFollowingListByUserID -
getPostListByUserID -
getUserLikesByPostID -
getLikeCountByPostID -
getTimelineByUserID
社交网络架构设计演变
DynamoDB 是一个 NoSQL 数据库,因此不允许您执行联接操作,也就是合并来自多个数据库的数据的操作。不熟悉 DynamoDB 的客户可能会不必要地将关系数据库管理系统 (RDBMS, Relational DataBase Management System) 的设计理念(例如为每个实体创建表)应用于 DynamoDB。DynamoDB 单表设计的目的是根据应用程序的访问模式,以预先联接的形式写入数据,然后无需额外计算即可立即使用数据。有关更多信息,请参阅 DynamoDB 中的单表与多表设计。
现在,我们来逐步了解一下如何改进架构设计以解决所有访问模式。
步骤 1:解决访问模式 1 (getUserInfoByUserID)
要获取给定用户的信息,我们需要使用键条件 PK=<userID> 对基表执行 Query 操作。查询操作允许您对结果进行分页,这在用户有很多关注者时很有用。有关 Query 的更多信息,请参阅在 DynamoDB 中查询表。
在示例中,我们跟踪用户的两种类型的数据:他们的“count”和“info”。用户的“count”反映了他们有多少粉丝,他们关注了多少用户,以及他们创建了多少帖子。用户的“info”反映了他们的个人信息,例如他们的姓名。
我们看到这两种数据类型由以下两项表示。排序键 (SK) 中带有“count”的项目比带有“info”的项目更有可能发生改变。DynamoDB 会考虑更新前后的项目大小,所消耗的预置吞吐量将反映这些项目大小中较大的一个。因此,即使您只更新项目属性的子集,UpdateItem 仍会消耗全部的预调配吞吐量(之前和之后项目大小中的较大者)。您可以通过单个 Query 操作获取项目,并使用 UpdateItem 对现有的数值属性进行加减。

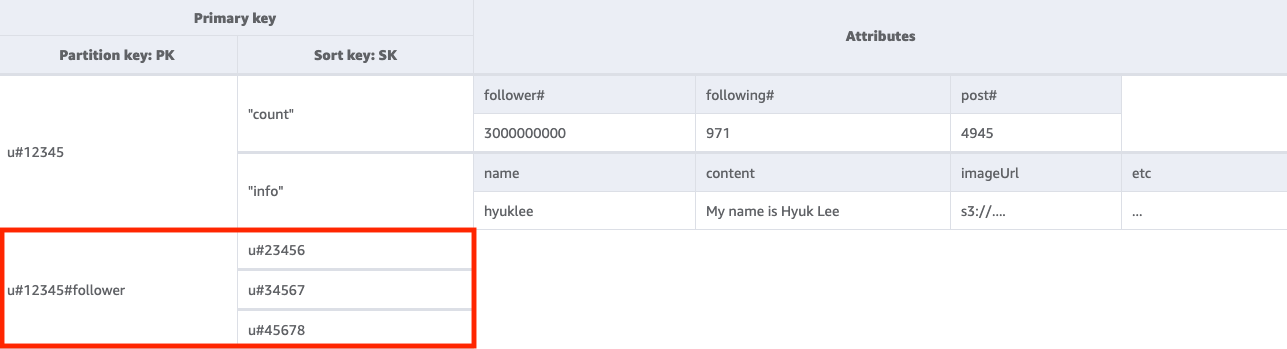
步骤 2:解决访问模式 2 (getFollowerListByUserID)
要获取关注给定用户的用户名单,我们需要使用键条件 PK=<userID>#follower 对基表执行 Query 操作。
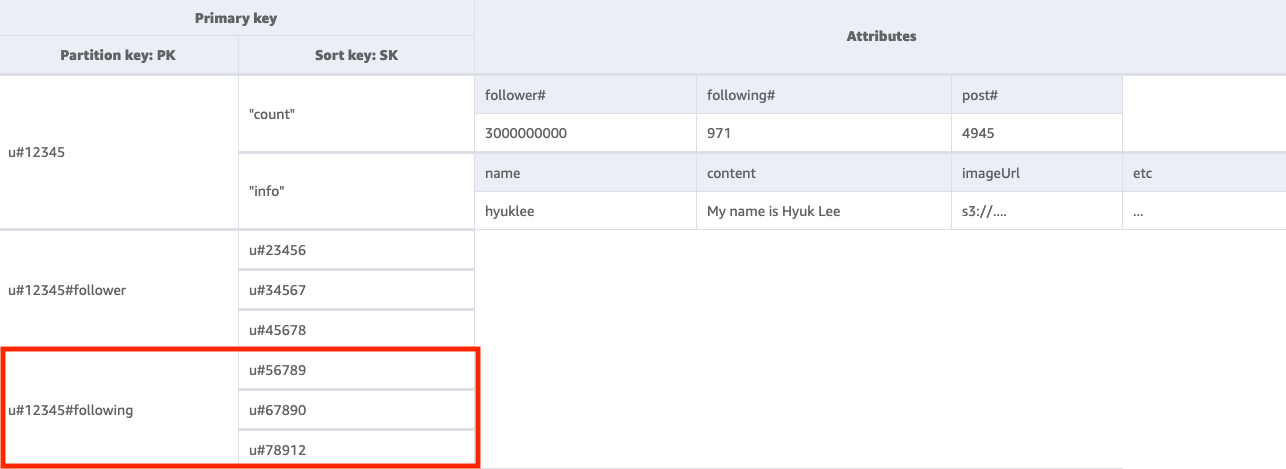
步骤 3:解决访问模式 3 (getFollowingListByUserID)
要获取给定用户所关注的用户名单,我们需要使用键条件 PK=<userID>#following 对基表执行 Query 操作。接下来,您可以使用 TransactWriteItems 操作来将多个请求分组在一起,并执行以下操作:
-
将用户 A 添加到用户 B 的粉丝名单,然后将用户 B 的粉丝人数增加 1。
-
将用户 B 添加到用户 A 的粉丝名单,然后将用户 A 的粉丝人数增加 1。
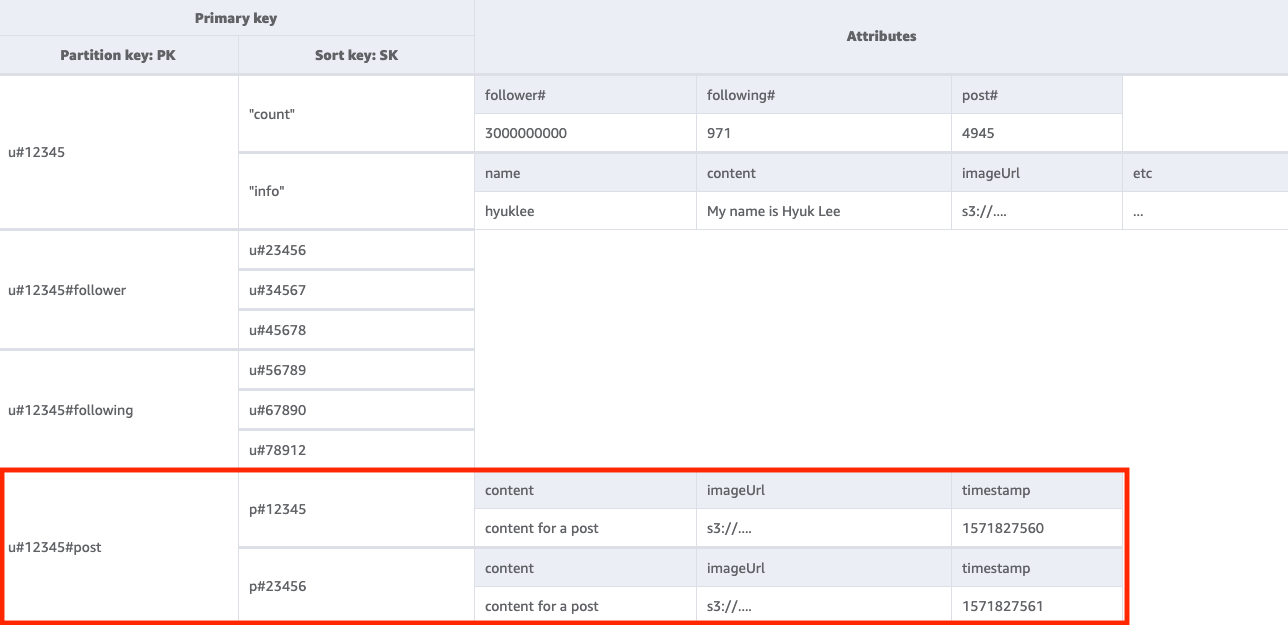
步骤 4:解决访问模式 4 (getPostListByUserID)
要获取给定用户发布的帖子列表,我们需要使用键条件 PK=<userID>#post 对基表执行 Query 操作。这里有非常重要的一点需要注意,用户的 postID 必须是递增的:第二个 postID 值必须大于第一个 postID 值(因为用户希望以排序的方式查看他们的帖子)。为此,您可以根据时间值生成 postID 来实现此目的,例如通用唯一词典排序标识符 (ULID, Lexicographically Sortable Identifier)。
步骤 5:解决访问模式 5 (getUserLikesByPostID)
要获取对给定用户的帖子点赞的用户名单,我们需要使用键条件 PK=<postID>#likelist 对基表执行 Query 操作。这种方法与我们在访问模式 2 (getFollowerListByUserID) 和访问模式 3 (getFollowingListByUserID) 中用来检索粉丝和关注名单时使用的模式相同。
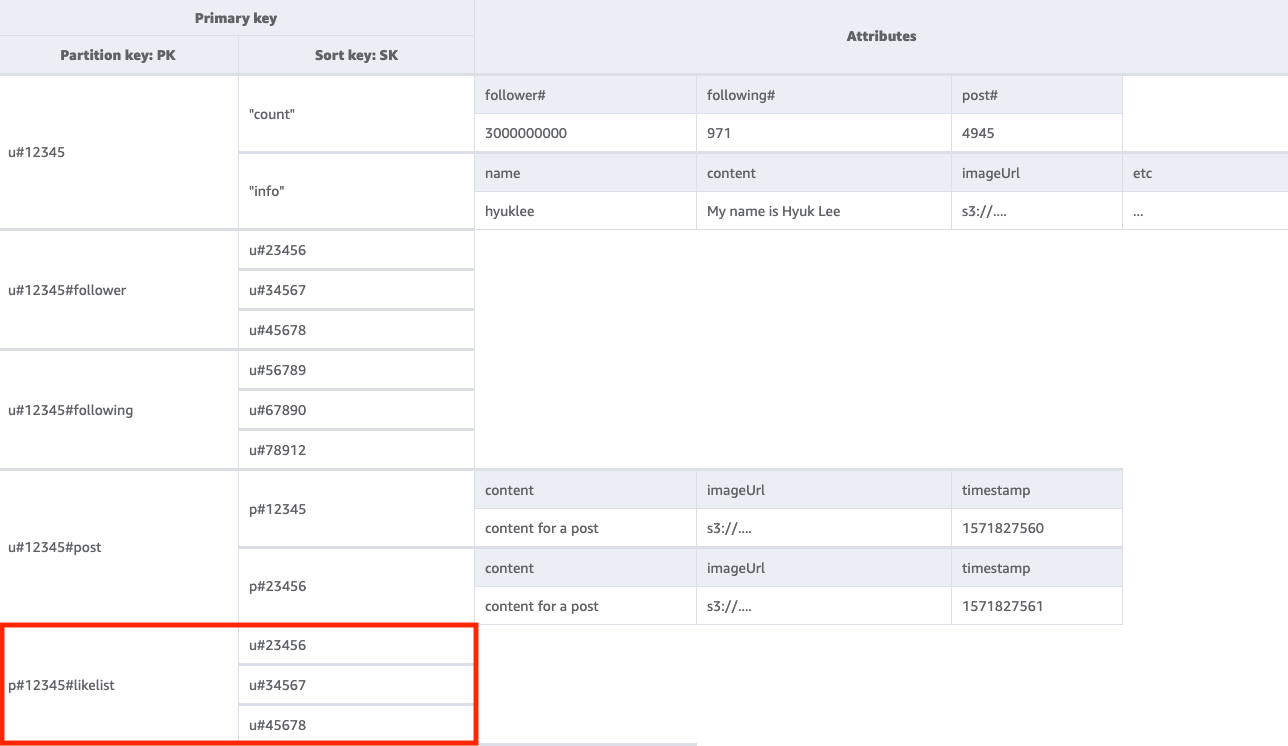
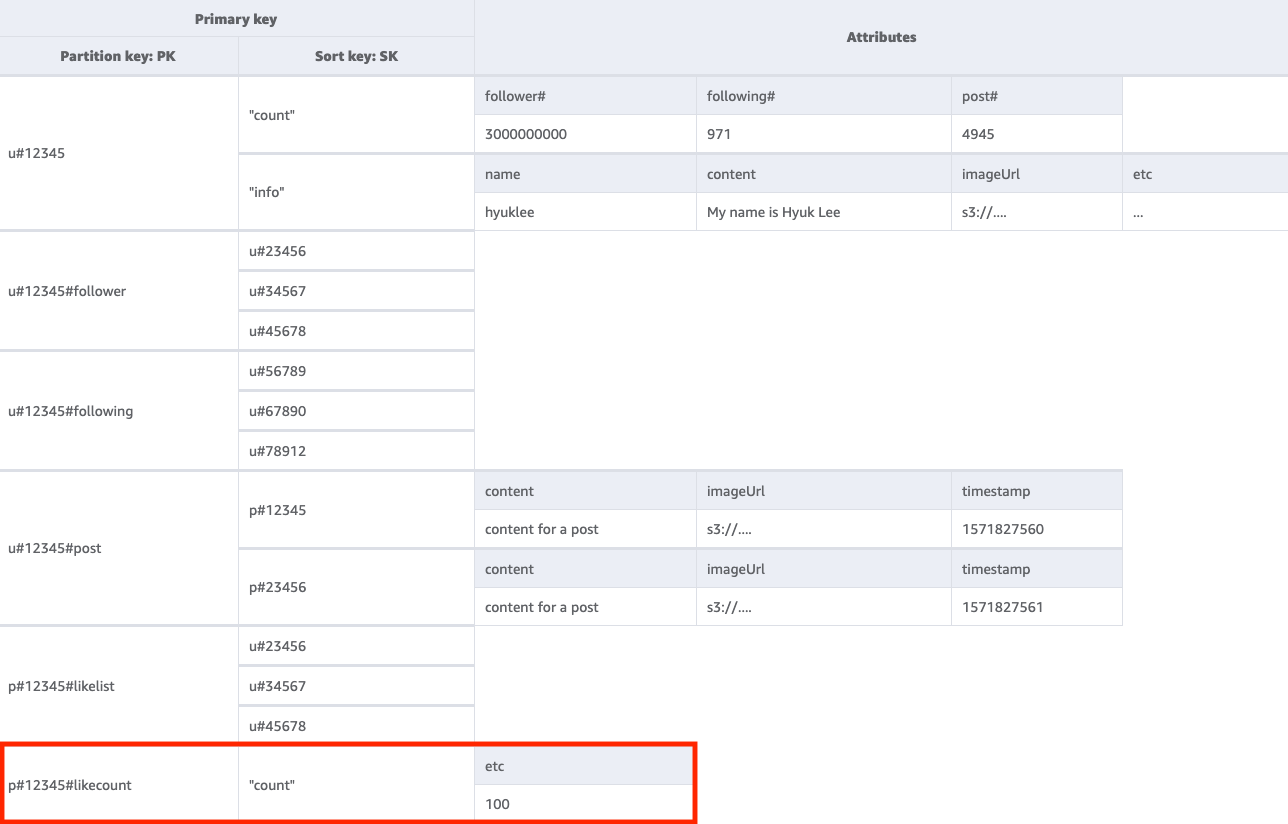
步骤 6:解决访问模式 6 (getLikeCountByPostID)
要获取给定帖子的点赞数,我们需要使用键条件 PK=<postID>#likecount 对基表执行 GetItem 操作。当拥有许多粉丝的某个用户(例如名人)创建帖子时,这种访问模式可能会导致节流问题,因为当单个分区的吞吐量超过每秒 1000 个 WCU 时,就会出现节流。这个问题不是 DynamoDB 造成的,只是正好出现在 DynamoDB 中,因为它位于软件堆栈的最后部分。
您应该评估一下是否有必要让所有用户同时查看点赞数,还是可以在一段时间内逐步显示。通常,帖子的点赞数不必立即获得 100% 准确的值。您可以通过在应用程序和 DynamoDB 之间放置队列,用于定期进行更新,以此来实施此策略。
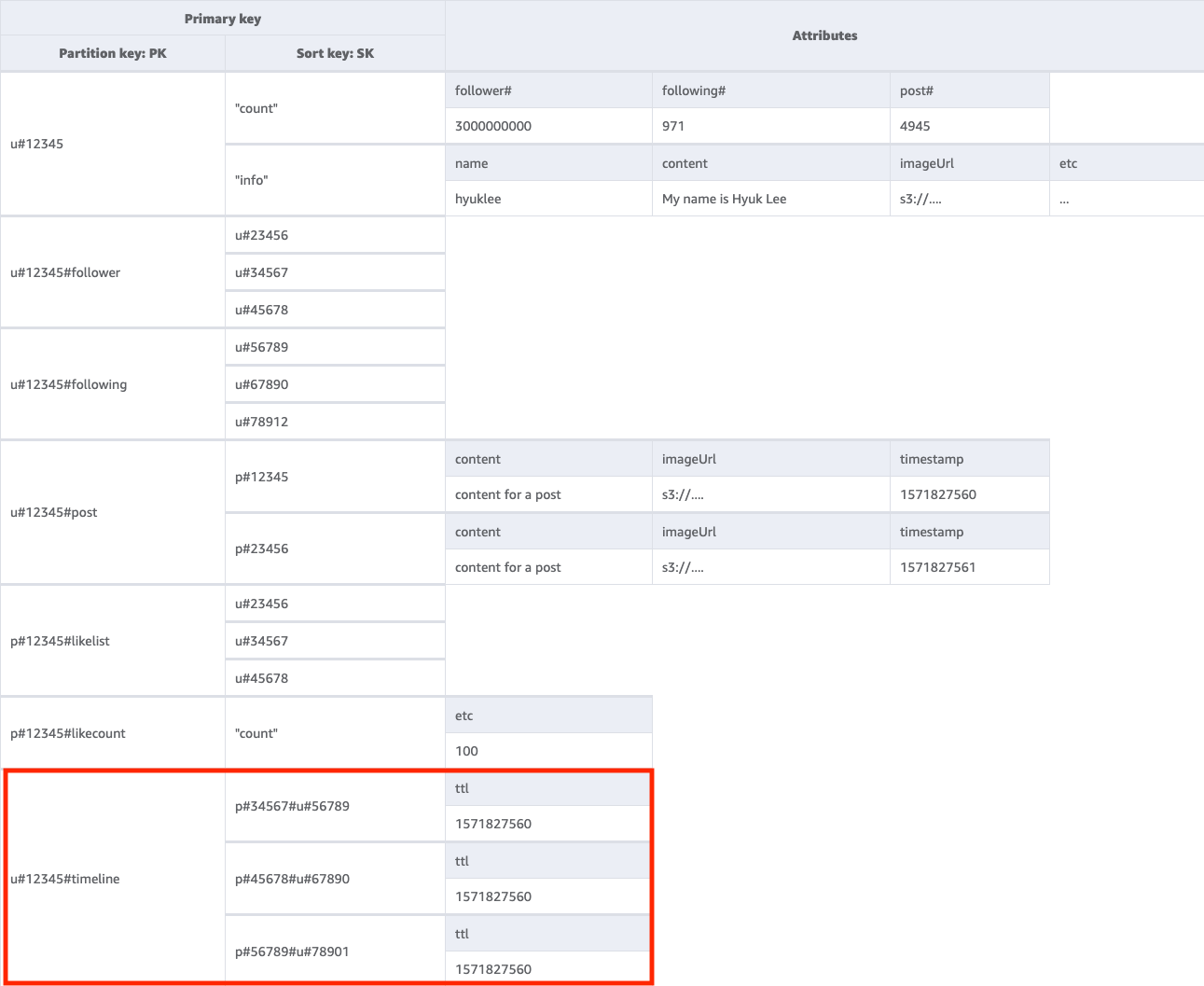
步骤 7:解决访问模式 7 (getTimelineByUserID)
要获取给定用户的时间线,我们需要使用键条件 PK=<userID>#timeline 对基表执行 Query 操作。我们来考虑一个场景,即用户的粉丝需要同步查看用户的帖子。每次用户发了一个帖子时,都会读取用户的粉丝名单,并将用户的 userID 和 postID 逐步输入其所有粉丝的时间线中。然后,当应用程序启动时,您可以通过 Query 操作读取时间线键,并对任何新项目使用 BatchGetItem 操作,将 userID 和 postID 的组合结果来填充时间线屏幕。您无法通过 API 调用来读取时间线,但是如果帖子经常会进行编辑,则这是一种更具成本效益的解决方案。
时间线是显示最近帖子的位置,所以我们需要一种方法来清理旧帖子。您可以使用 DynamoDB 的 TTL 功能来免费删除旧帖子,而无需使用 WCU。
下表总结了所有访问模式以及架构设计如何解决访问模式:
| 访问模式 | 基表/GSI/LSI | 操作 | 分区键值 | 排序键值 | 其他条件/筛选条件 |
|---|---|---|---|---|---|
| getUserInfoByUserID | 基表 | Query | PK=<userID> | ||
| getFollowerListByUserID | 基表 | Query | PK=<userID>#follower | ||
| getFollowingListByUserID | 基表 | Query | PK=<userID>#following | ||
| getPostListByUserID | 基表 | Query | PK=<userID>#post | ||
| getUserLikesByPostID | 基表 | Query | PK=<postID>#likelist | ||
| getLikeCountByPostID | 基表 | GetItem | PK=<postID>#likecount | ||
| getTimelineByUserID | 基表 | Query | PK=<userID>#timeline |
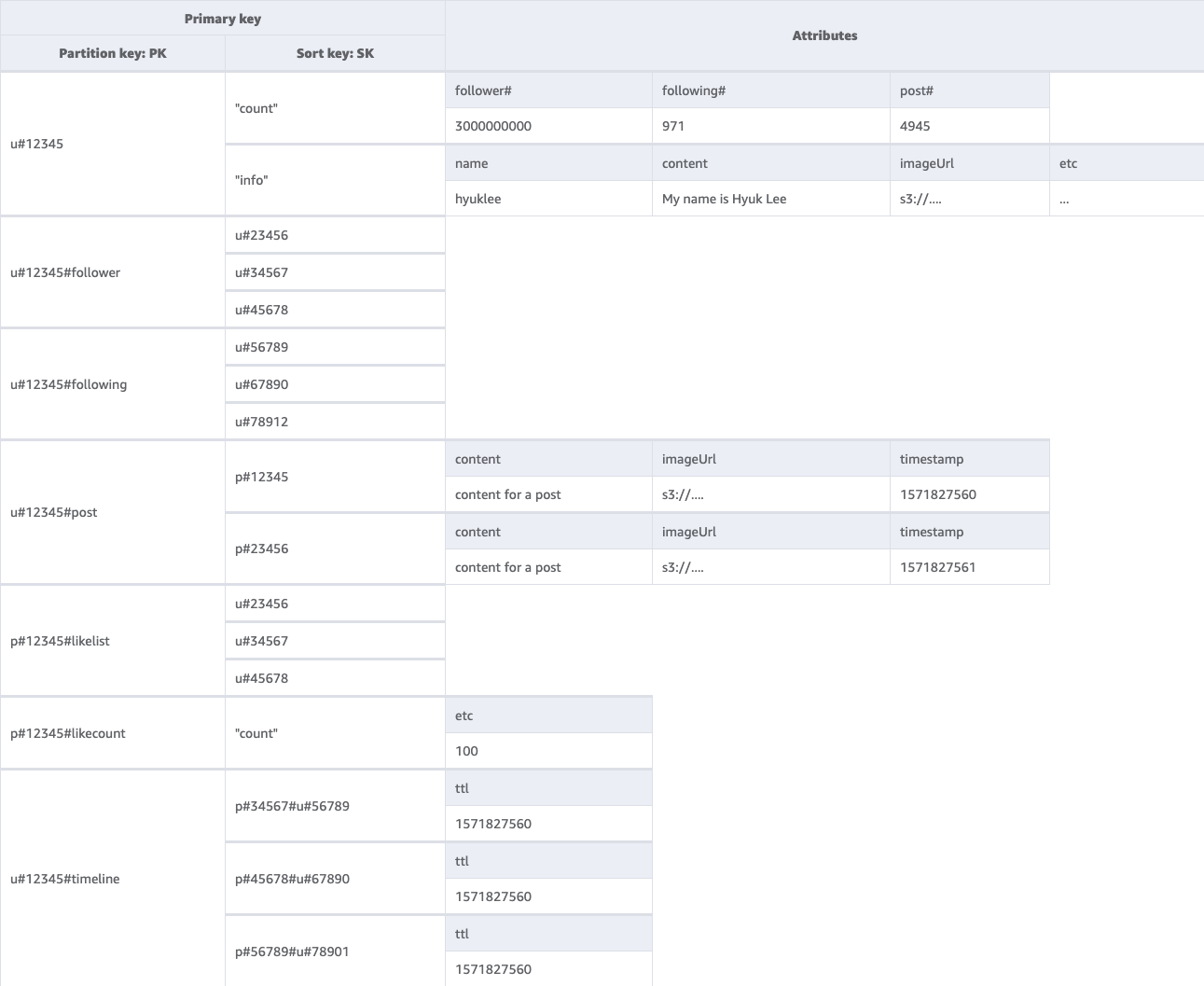
社交网络最终架构
这是最终的架构设计。要以 JSON 文件格式下载此架构设计,请参阅 GitHub 上的 DynamoDB 示例
基表:
在此架构设计中使用 NoSQL Workbench
若要进一步探索和编辑新项目,您可以将此最终架构导入到 NoSQL Workbench,这是一款为 DynamoDB 提供数据建模、数据可视化和查询开发功能的可视化工具。请按照以下步骤开始使用:
-
下载 NoSQL Workbench。有关更多信息,请参阅 下载 NoSQL Workbench for DynamoDB。
-
下载上面列出的 JSON 架构文件,该文件已经采用 NoSQL Workbench 模型格式。
-
将 JSON 架构文件导入到 NoSQL Workbench。有关更多信息,请参阅 导入现有数据模型。
-
导入到 NOSQL Workbench 后,您便可编辑数据模型。有关更多信息,请参阅 编辑现有数据模型。
