在 Athena 中使用 EXPLAIN 和 EXPLAIN ANALYZE
EXPLAIN 语句显示指定 SQL 语句的逻辑或分布式执行计划,或验证 SQL 语句。您可以以文本格式或数据格式输出结果,以便渲染到图形中。
注意
您可以在 Athena 控制台中查看查询的逻辑和分布式计划的图形展示,而无需使用 EXPLAIN 语法。有关更多信息,请参阅 查看 SQL 查询的执行计划。
EXPLAIN ANALYZE 语句既显示了指定 SQL 语句的分布式执行计划,也显示了 SQL 查询中每个操作的计算成本。您可以以文本或 JSON 格式输出结果。
注意事项和限制
Athena 中的 EXPLAIN 和 EXPLAIN ANALYZE 语句具有以下限制。
-
由于
EXPLAIN查询不扫描任何数据,因此 Athena 不会对其收取费用。然而,因为EXPLAIN查询会调用 AWS Glue 检索表元数据,如果呼叫超过 Glue 免费套餐限制,则可能会产生 Glue 费用。 -
由于执行
EXPLAIN ANALYZE查询,它们会扫描数据,Athena 会根据扫描的数据量收费。 -
在 Lake Formation 中定义的行或单元格筛选信息以及查询统计信息未在
EXPLAIN和EXPLAIN ANALYZE的输出中显示。
EXPLAIN 语法
EXPLAIN [ (option[, ...]) ]statement
option 的值可以是以下值之一:
FORMAT { TEXT | GRAPHVIZ | JSON } TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
如果未指定 FORMAT 选项,则输出默认为 TEXT 格式。IO 类型提供了有关查询读取的表和架构的信息。IO 仅在 Athena 引擎版本 2 中受支持,并且只能以 JSON 格式返回。
EXPLAIN ANALYZE 语法
除了 EXPLAIN 中包含的输出,EXPLAIN
ANALYZE 输出还包括指定查询的运行时统计信息,例如 CPU 使用率、输入的行数和输出的行数。
EXPLAIN ANALYZE [ (option[, ...]) ]statement
option 的值可以是以下值之一:
FORMAT { TEXT | JSON }
如果未指定 FORMAT 选项,则输出默认为 TEXT 格式。由于 EXPLAIN ANALYZE 的所有查询都是 DISTRIBUTED,所以 TYPE 选项不适用于 EXPLAIN ANALYZE。
语句可以是以下值之一:
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
EXPLAIN 示例
以下 EXPLAIN 示例的复杂程度从简单到复杂依次递增。
在以下示例中,EXPLAIN 演示了针对 Elastic Load Balancing 日志的 SELECT 查询的执行计划。格式默认为文本输出。
EXPLAIN SELECT request_timestamp, elb_name, request_ip FROM sampledb.elb_logs;
结果
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULAR您可以使用 Athena 控制台为自己绘制查询计划图表。在 Athena 查询编辑器中输入类似以下内容的 SELECT 语句,然后选择 EXPLAIN。
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey
Athena 查询编辑器的 Explain(说明)页面将打开并显示查询的分布式计划和逻辑计划。下图显示了示例的逻辑计划。
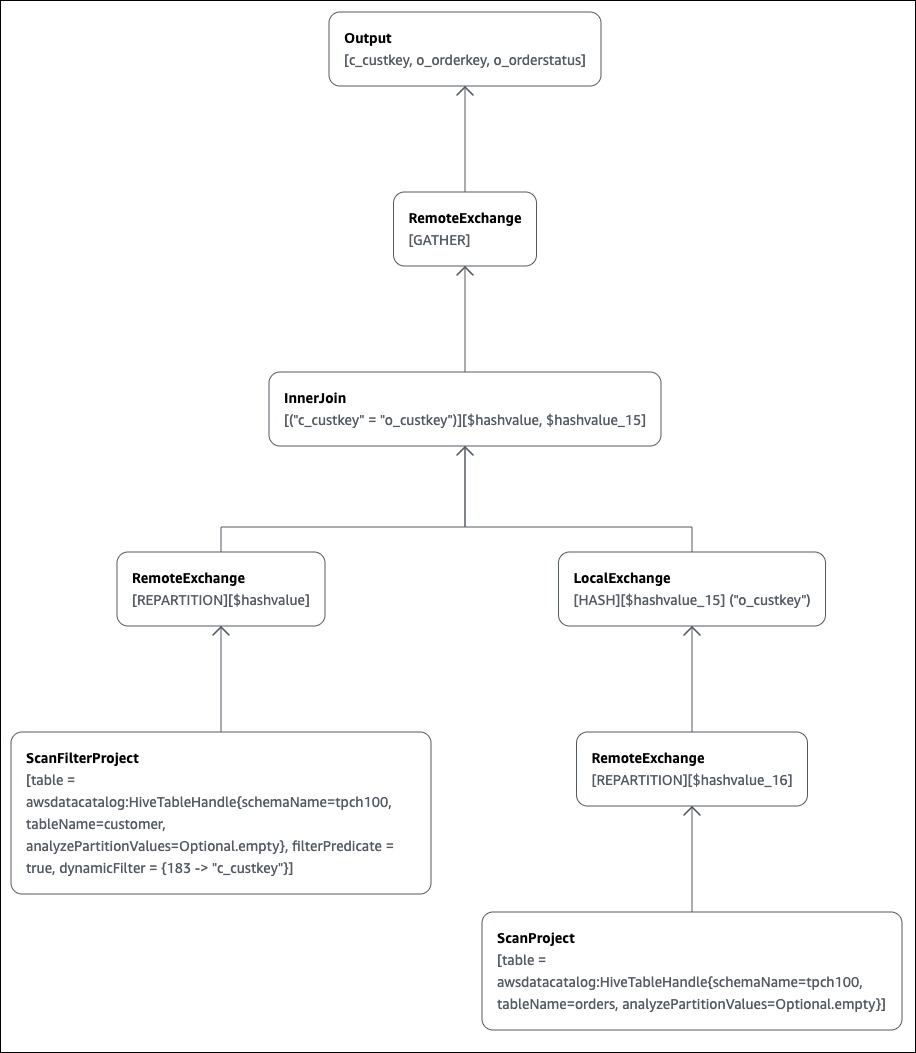
重要
目前,某些分区筛选器可能在嵌套运算符树图表中不可见,即使 Athena 确实将其应用于您的查询。要验证此类筛选器的效果,请在您的查询中运行 EXPLAIN 或 EXPLAIN
ANALYZE 并查看结果。
有关如何在 Athena 控制台中使用查询计划图表功能的更多信息,请参阅 查看 SQL 查询的执行计划。
在分区键上使用筛选谓词来查询分区表时,查询引擎会将谓词应用于分区键以减少读取的数据量。
下面的示例使用了 EXPLAIN 查询来验证分区表上 SELECT 查询的分区修剪。首先,一个 CREATE TABLE 语句将创建 tpch100.orders_partitioned 表。表将在 o_orderdate 列上进行分区。
CREATE TABLE `tpch100.orders_partitioned`( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) PARTITIONED BY ( `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/<your_directory_path>/'
tpch100.orders_partitioned 表在 o_orderdate 上有几个分区,如 SHOW PARTITIONS 命令所示。
SHOW PARTITIONS tpch100.orders_partitioned; o_orderdate=1994 o_orderdate=2015 o_orderdate=1998 o_orderdate=1995 o_orderdate=1993 o_orderdate=1997 o_orderdate=1992 o_orderdate=1996
以下 EXPLAIN 查询验证指定 SELECT 语句的分区修剪。
EXPLAIN SELECT o_orderkey, o_custkey, o_orderdate FROM tpch100.orders_partitioned WHERE o_orderdate = '1995'
结果
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR结果中的粗体文本显示谓词 o_orderdate =
'1995' 被应用于 PARTITION_KEY。
以下 EXPLAIN 查询检查 SELECT 语句的连接顺序和连接类型。使用这样的查询来检查查询内存使用情况,以便降低获取 EXCEEDED_LOCAL_MEMORY_LIMIT 错误消息的几率。
EXPLAIN (TYPE DISTRIBUTED) SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
结果
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR示例查询经过优化为交叉连接以获得更好的性能。结果表明 tpch100.orders 将作为 BROADCAST 分配类型加以分配。这意味着 tpch100.orders 表将分发给执行联接操作的所有节点。BROADCAST 分布类型将要求 tpch100.orders 表的所有筛选结果适应执行连接操作的各节点内存。
然而,tpch100.customer 表较 tpch100.orders 更小。由于 tpch100.customer 需要的内存较少,因此可以将查询重写为 BROADCAST
tpch100.customer 而不是 tpch100.orders。这会降低查询接收 EXCEEDED_LOCAL_MEMORY_LIMIT 错误消息的几率。此策略假定以下几点:
-
tpch100.customer.c_custkey是唯一的tpch100.customer表。 -
在
tpch100.customer和tpch100.orders之间存在一对多映射关系。
以下示例显示了重写的查询:
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.orders o JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes. ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
您可以使用 EXPLAIN 查询来检查筛选谓词的有效性。您可以使用结果删除没有效果的谓词,如以下示例所示。
EXPLAIN SELECT c.c_name FROM tpch100.customer c WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT) AND c.c_custkey BETWEEN 1000 AND 2000 AND c.c_custkey = 1500
结果
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULAR结果中的 filterPredicate 显示优化程序将原来的三个谓词合并为两个谓词,并更改了它们的应用顺序。
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
因为结果表明,谓词 AND c.c_custkey BETWEEN
1000 AND 2000 不起作用,所以可在不更改查询结果的情况下删除此谓词。
有关在 EXPLAIN 查询结果中使用的术语信息,请参阅 了解 Athena EXPLAIN 语句结果。
EXPLAIN ANALYZE 示例
以下示例演示示例 EXPLAIN ANALYZE 查询和输出。
在以下示例中,EXPLAIN ANALYZE 演示了对 CloudFront 日志执行的 SELECT 查询的执行计划和计算成本。格式默认为文本输出。
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
结果
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULAR以下示例演示了对 CloudFront 日志执行的 SELECT 查询的执行计划和计算成本。该示例指定 JSON 作为输出格式。
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
结果
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}其他资源
有关更多信息,请参阅以下资源。
-
Trino
EXPLAIN文档 -
Trino
EXPLAIN ANALYZE文档 -
AWS 大数据博客中的使用 Amazon Athena 中的 EXPLAIN 和 EXPLAIN ANALYZE 优化联合查询性能
。
