本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
事务支持
使用 Amazon Cloud Directory,通常需要添加新对象或者添加新对象与现有对象之间的关系,用于体现真实层次结构的更改。批处理操作提供了以下优势,可以使得类似于这样的目录任务更易于管理:
-
批处理操作可以最大程度地减少在目录中写入和读取对象所需的往返次数,从而提高整体应用程序的性能。
-
批处理写入提供了 SQL 数据库等效事务语义。所有操作均成功完成;如果有任何操作失败,则不会应用任何一个操作。
-
使用批处理引用,您可以创建对象并使用对新对象的引用执行进一步操作,例如将其添加到关系中,减少在写入操作前使用读取操作的开销。
BatchWrite
使用 BatchWrite 操作可对目录执行多个写入操作。批处理写入中的所有操作按顺序执行。其工作方式类似于 SQL 数据库事务。如果批处理写入中的一个操作失败,则整个批处理写入都不会影响目录。如果批处理写入失败,则引发批处理写入异常。异常包含失败操作的索引以及异常类型和消息。这些信息可以帮助确定失败的根本原因。
批处理写入中支持以下 API 操作:
批处理引用名称
在中间批处理操作需要引用某个对象时,只有批处理写入支持批处理引用名称。例如,假设在给定批处理写入中,要分离 10 个不同的对象并将它们附加到目录的另一个部分。如果不使用批处理引用,则必须读取所有 10 个对象引用,并在批处理写入中的重新附加过程中提供它们作为输入。您可以使用批处理引用在附加过程中标识分离的资源。批处理引用可以是用数字符号/井号 (#) 作为前缀的任何常规字符串。
例如,在以下代码示例中,链接名称为 "this-is-a-typo" 的对象使用批处理引用名称 "ref" 从根分离。随后该对象使用链接名称 "correct-link-name" 附加到根。该对象使用设置为批处理引用的子引用进行标识。如果不使用批处理引用,则需要先获取所分离的 objectIdentifier,并在附加过程中在子引用中提供它。可以使用批处理引用名称避免这种额外的读取。
BatchDetachObject batchDetach = new BatchDetachObject() .withBatchReferenceName("ref") .withLinkName("this-is-a-typo") .withParentReference(new ObjectReference().withSelector("/")); BatchAttachObject batchAttach = new BatchAttachObject() .withParentReference(new ObjectReference().withSelector("/")) .withChildReference(new ObjectReference().withSelector("#ref")) .withLinkName("correct-link-name"); BatchWriteRequest batchWrite = new BatchWriteRequest() .withDirectoryArn(directoryArn) .withOperations(new ArrayList(Arrays.asList(batchDetach, batchAttach)));
BatchRead
使用 BatchRead 操作可对目录执行多个读取操作。例如,在以下代码示例中,在单个批处理读取中读取具有引用“/managers”的对象的子级以及具有引用“/managers/bob”的对象的属性。
BatchListObjectChildren listObjectChildrenRequest = new BatchListObjectChildren() .withObjectReference(new ObjectReference().withSelector("/managers")); BatchListObjectAttributes listObjectAttributesRequest = new BatchListObjectAttributes() .withObjectReference(new ObjectReference().withSelector("/managers/bob")); BatchReadRequest batchRead = new BatchReadRequest() .withConsistencyLevel(ConsistencyLevel.SERIALIZABLE) .withDirectoryArn(directoryArn) .withOperations(new ArrayList(Arrays.asList(listObjectChildrenRequest, listObjectAttributesRequest))); BatchReadResult result = cloudDirectoryClient.batchRead(batchRead);
BatchRead 支持以下 API 操作:
针对批处理操作的限制
对服务器的每个请求 (包括批处理请求) 所能操作的资源存在最大数量限制,不论请求中有多少个操作。这可以在编写批处理请求时带来巨大的灵活性,只要您保持在资源限制内。有关资源最大值的更多信息,请参阅Amazon Cloud Directory 限制。
限制的计算方式是将批处理内每个操作的写入数或读取数相加。例如,当前每个 API 调用的读取操作限制为 200 个对象。假设您编写一个批处理,添加 9 个 ListObjectChildren API 调用,每个调用需要读取 20 个对象。由于读取对象总数 (9 x 20 = 180) 未超过 200,批处理操作将成功。
同样的概念也适用于计算写入操作数。例如,当前写入操作限制为 20。如果您设置批处理添加 2 个 UpdateObjectAttributes API 调用,每个调用有 9 个写入操作,这也会成功。在这两种情况下,如果批处理操作超出限制,操作将会失败并引发 LimitExceededException。
计算批处理中包含的对象数量的正确方式是应包含实际节点或 leaf_node 对象;如果使用基于路径的方式迭代您的目录树,您也需要在批处理中包含迭代的每个路径。例如,如下图所示的基本目录树,要读取 003 对象的属性值,对象的读取计数总数应该是三。
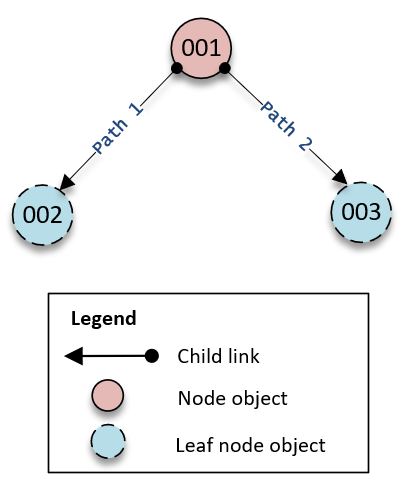
沿目录树向下遍历读取的工作原理如下:
1. 读取对象 001,来确定对象 003 的路径
2. 沿 Path 2 向下
3. 读取对象 003
同样,对于属性数量,我们需要针对对象 001 和 003 中的属性数量进行计数,以确保不会超出限制。
异常处理
Cloud Directory 中的 Batch 操作有时会失败。在这些情况下,务必要知道如何处理此类故障。对于写入操作和读取操作,解决故障所用的方法不相同。
批处理写入操作失败
如果批处理写入操作失败,Cloud Directory 会使整个批处理操作失败,并返回异常。异常包含失败操作的索引以及异常类型和消息。如果看到 RetryableConflictException,您可以使用指数退避重试。执行此操作的一个简单方法是,每次出现异常或失败时,您等待的时间都加倍。例如,如果第一个批处理写入操作失败,则等待 100 毫秒,然后重试请求。如果第二个请求失败,则等待 200 毫秒,然后重试。如果第三个请求失败,则等待 400 毫秒,然后重试。
批处理读取操作失败
如果批处理读取操作失败,响应包含成功响应或异常响应。单个批处理读取操作失败不会导致整个批处理读取操作失败,Cloud Directory 会为每个操作返回单独的成功或失败响应。
相关 Cloud Directory 博客文章
