本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
连接 Amazon S3 中多个文件中的数据
通过 DataBrew 控制台,您可以浏览 Amazon S3 存储桶和文件夹,并为数据集选择文件。但是,一个数据集不必局限于一个文件。
假设您有一个名为 my-databrew-bucket 的 S3 存储桶,其中包含一个名为 databrew-input 的文件夹。在该文件夹中,假设您有许多 JSON 文件,所有文件都具有相同的格式和 .json 文件扩展名。在控制台上,您可以指定 s3://my-databrew-bucket/databrew-input/ 的源 URL。然后,您可以在 DataBrew 控制台上选择此文件夹。您的数据集由该文件夹中的所有 JSON 文件组成。
DataBrew 可以处理 S3 文件夹中的所有文件,但前提是满足以下条件:
-
该文件夹中的所有文件都具有相同的格式。
-
该文件夹中的所有文件具有相同的文件扩展名。
有关支持的文件格式和扩展名的更多信息,请参阅 DataBrew input formats。
使用多个文件作为数据集时的架构
当使用多个文件作为 DataBrew 数据集时,所有文件的架构必须相同。否则,项目工作区会自动尝试从多个文件中选择一个架构,并尝试使其余的数据集文件符合该架构。该行为会导致项目工作区期间显示的视图不规则,因此作业输出也会变得不规则。
如果您的文件必须采用不同的架构,则需要创建多个数据集并分别对其进行分析。
为 Amazon S3 使用参数化路径
在某些情况下,您需要创建的数据集可能包含遵循特定命名约定的文件,或者可以跨多个 Amazon S3 文件夹。或者,您可能需要将相同的数据集重复用于结构相同的数据,这些数据是在路径取决于某些参数的 S3 位置定期生成的。例如,以数据生成日期命名的路径。
DataBrew 通过参数化的 S3 路径支持这种方法。参数化路径是包含正则表达式或自定义路径参数(或两者兼而有之)的 Amazon S3 URL。
在 S3 路径中使用正则表达式定义数据集
如果要匹配一个或多个文件夹中的多个文件,并且同时筛选出这些文件夹中不相关的文件,那么在路径中使用正则表达式非常有用。
以下是几个示例:
-
定义一个数据集,其中包含名称以
invoice开头的文件夹中的所有 JSON 文件。 -
定义一个数据集,其中包含名称中带有
2020的文件夹中的所有文件。
您可以通过在数据集 S3 路径中使用正则表达式来实施这种方法。这些正则表达式可以替换 S3 URL 密钥中的任何子字符串(但不能是存储桶名称)。
作为 S3 URL 中的密钥示例,请见下。这里,my-bucket 是存储桶名称,美国东部(俄亥俄州)是 AWS
区域,puppy.png 是密钥名称。
https://my-bucket.s3.us-west-2.amazonaws.com/puppy.png
在参数化 S3 路径中,两个尖括号(< 和 >)之间的任何字符都被视为正则表达式。以下是两个示例:
-
s3://my-databrew-bucket/databrew-input/invoice<.*>/data.json匹配databrew-input的名称以invoice开头的所有子文件夹中名为data.json的所有文件。 -
s3://my-databrew-bucket/databrew-input/<.*>2020<.*>/匹配文件夹内名称中带有2020的所有文件。
在这些示例中,.* 匹配零个或多个字符。
注意
您只能在 S3 路径的密钥部分(存储桶名称之后的部分)中使用正则表达式。因此,s3://my-databrew-bucket/<.*>-input/ 有效,但 s3://my-<.*>-bucket/<.*>-input/ 无效。
建议您测试正则表达式,以确保它们仅匹配您需要的 S3 URL,而不匹配您不需要的 S3 URL。
以下是正则表达式的一些其他示例:
<\d{2}>匹配恰好由两个连续数字组成的字符串,例如07或03,但不是1a2。<[a-z]+.*>匹配以一个或多个小写拉丁字母开头且后面有零个或多个其他字符的字符串。示例有a3、abc/def或a-z,但不是A2。<[^/]+>匹配包含除斜杠(/)之外的任何字符的字符串。在 S3 URL 中,斜杠用于分隔路径中的文件夹。<.*=.*>匹配包含等号(=)的字符串,例如month=02、abc/day=2或=10,但不是test。<\d.*\d>匹配以数字开头和结尾,并且这两个数字之间可以包含任何其他字符的字符串,例如1abc2、01-02-03或2020/Jul/21,但不是123a。
在 S3 路径中使用自定义参数定义数据集
当您可能需要为 S3 位置提供参数时,使用自定义参数定义参数化数据集比使用正则表达式更有优势:
您可以获得与使用正则表达式相同的结果,而无需知道正则表达式的语法。您可以使用诸如“开头为”和“包含”之类的熟悉术语来定义参数。
在路径中使用参数定义动态数据集时,可以在定义中包含一个时间范围,例如“过去一个月”或“过去 24 小时”。这样,您的数据集定义就可以在以后用于处理新传入的数据。
以下是一些何时可能需要使用动态数据集的示例:
连接按上次更新日期或其他有意义的属性分区到单个数据集中的多个文件。然后,您可以作为数据集中的附加列捕获这些分区属性。
将数据集中的文件限制到满足特定条件的 S3 位置。例如,假设您的 S3 路径包含基于日期的文件夹,例如
folder/2021/04/01/。在这种情况下,您可以对日期进行参数化并将其限制到某个特定范围,例如“2021 年 3 月 1 日至 2021 年 4 月 1 日之间”或“过去一周”。
要使用参数定义路径,请使用以下格式定义参数并将其添加到路径中:
s3://my-databrew-bucket/some-folder/{parameter1}/file-{parameter2}.json
注意
与 S3 路径中的正则表达式一样,您只能在路径的密钥部分(存储桶名称之后的部分)中使用参数。
参数定义中需要用到两个字段,即名称和类型。类型可以是字符串、数字或日期。日期类型的参数必须定义日期格式,这样 DataBrew 才能正确解释和比较日期值。或者,您可以为参数定义匹配条件。当 DataBrew 作业或交互式会话加载数据集时,您也可以选择将参数的匹配值作为列添加到数据集中。
示例
让我们考虑一个使用 DataBrew 控制台中的参数定义动态数据集的示例。在此示例中,假设使用如下位置将输入数据定期写入 S3 存储桶:
s3://databrew-dynamic-datasets/new-cases/UR/daily-report-2021-03-30.csvs3://databrew-dynamic-datasets/new-cases/UR/daily-report-2021-03-31.csvs3://databrew-dynamic-datasets/new-cases/US/daily-report-2021-03-30.csvs3://databrew-dynamic-datasets/new-cases/US/daily-report-2021-03-31.csv
这里有两个动态部分:国家/地区代码(如 US)和文件名中的日期(如 2021-03-30)。这里,您可以对所有文件应用相同的清理配方。假设您要每天执行清理作业。以下介绍了如何为此场景定义参数化路径:
-
导航到特定文件。
-
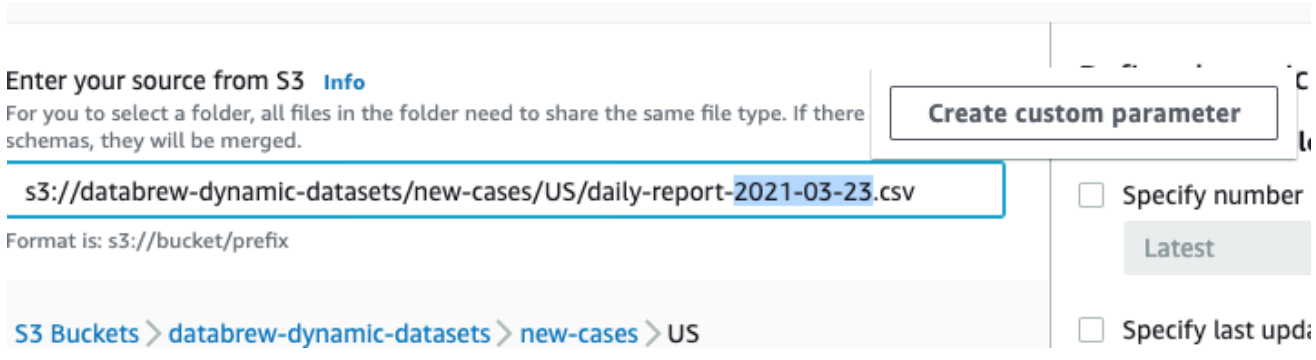
然后,选择一个不同部分,例如日期,并将其替换为参数。在此示例中,替换日期。
-
打开创建自定义参数的上下文(右键单击)菜单,然后设置其属性:
名称:报告日期
类型:日期
日期格式:yyyy-MM-dd (从预定义格式中选择)
条件(时间范围):过去 24 小时
添加为列:true(选中)
将其他字段保留其默认值。
-
选择创建。
完成后,您将看到更新的路径,如以下屏幕截图所示。
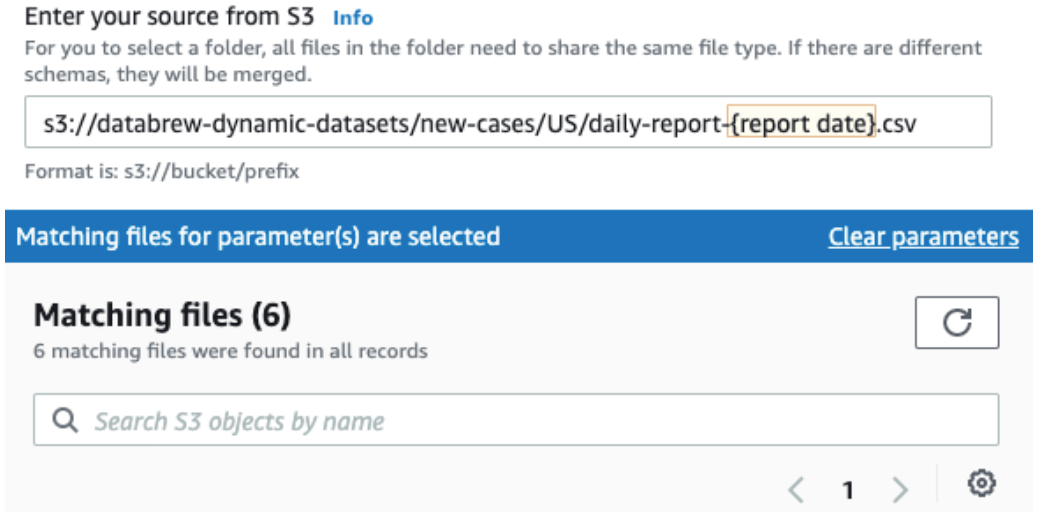
现在,您可以对国家/地区代码执行相同的操作,并按如下方式对其进行参数化:
名称:国家/地区代码
类型:字符串
添加为列:true(选中)
如果所有值都相关,则无需指定条件。例如,在该 new-cases 文件夹中,我们只有带有国家/地区代码的子文件夹,因此无需附加条件。如果您有其他要排除的文件夹,则可以使用以下条件。
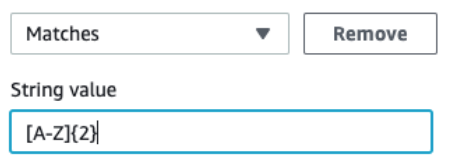
这种方法将新用例的子文件夹限制为包含两个大写拉丁字符。
完成此参数化后,您的数据集中只有匹配的文件,并且可以选择创建数据集。
注意
在条件中使用相对时间范围时,将在加载数据集时评估时间范围。无论是“过去 24 小时”之类的预定义时间范围,还是像“5 天前”这样的自定义时间范围,都是如此。无论是在交互式会话的初始化期间加载数据集,还是在作业启动期间加载数据集,这种评估方法都适用。
选择创建数据集后,您的动态数据集便可以使用了。例如,您可以先使用它来创建项目,然后使用交互式 DataBrew 会话定义清理方案。然后,您可以创建一个计划每天运行的作业。此作业可能会将清理配方应用于作业启动时满足参数条件的数据集文件。
动态数据集支持的条件
您可以使用条件,通过参数或上次修改的日期属性筛选匹配的 S3 文件。
在下文中,您可以找到每种参数类型支持的条件列表。
| DataBrew SDK 中的名称 | SDK 同义词 | DataBrew 控制台中的名称 | 说明 |
|---|---|---|---|
|
是 |
eq、== |
正好是 |
参数的值与条件中提供的值相同。 |
|
is not |
not eq、!= |
不是 |
参数的值与条件中提供的值不同。 |
|
contains |
包含 |
参数的字符串值包含条件中提供的值。 |
|
|
not contains |
不包含 |
参数的字符串值不包含条件中提供的值。 |
|
|
starts_with |
开头为 |
参数的字符串值以条件中提供的值开头。 |
|
|
not starts_with |
开头不是 |
参数的字符串值不以条件中提供的值开头。 |
|
|
ends_with |
结尾为 |
参数的字符串值以条件中提供的值结尾。 |
|
|
not ends_with |
不以以下值结尾 |
参数的字符串值不以条件中提供的值结尾。 |
|
|
matches |
Matches |
参数的值与条件中提供的正则表达式相匹配。 |
|
|
not matches |
不匹配 |
参数的值与条件中提供的正则表达式不匹配。 |
注意
字符串参数的所有条件都使用区分大小写的比较。如果您不确定 S3 路径中使用的大小写,则可以将“matches”条件与以 (?i) 开头的正则表达式值一起使用。这样做会使比较不区分大小写。
例如,假设您希望字符串参数以 abc 开头,但也可以以 Abc 或 ABC 开头。在这种情况下,可以将“matches”条件与 (?i)^abc 结合使用作为条件值。
| DataBrew SDK 中的名称 | SDK 同义词 | DataBrew 控制台中的名称 | 说明 |
|---|---|---|---|
|
是 |
eq、== |
正好是 |
参数的值与条件中提供的值相同。 |
|
is not |
not eq、!= |
不是 |
参数的值与条件中提供的值不同。 |
|
less_than |
lt、< |
Less than |
参数的数值小于条件中提供的值。 |
|
less_than_equal |
lte、<= |
小于或等于 |
参数的数值小于或等于条件中提供的值。 |
|
greater_than |
gt、> |
Greater than |
参数的数值大于条件中提供的值。 |
|
greater_than_equal |
gte、>= |
大于或等于 |
参数的数值大于或等于条件中提供的值。 |
| DataBrew SDK 中的名称 | DataBrew 控制台中的名称 | 条件值格式(SDK) | 说明 |
|---|---|---|---|
|
after |
晚于 |
ISO 8601 日期格式,例如 |
日期参数的值晚于条件中提供的日期。 |
|
before |
早于 |
ISO 8601 日期格式,例如 |
日期参数的值早于条件中提供的日期。 |
|
relative_after |
开始(相对) |
正数或负数时间单位,例如 |
日期参数的值晚于条件中提供的相对日期。 在加载数据集时(也就是在初始化交互式会话时,或者在启动关联作业时)评估相对日期。这就是示例中所谓“现在”的时刻。 |
|
relative_before |
结束(相对) |
正数或负数时间单位,例如 |
日期参数的值早于条件中提供的相对日期。 在加载数据集时(也就是在初始化交互式会话时,或者在启动关联作业时)评估相对日期。这就是示例中所谓“现在”的时刻。 |
如果您使用 SDK,请按以下格式提供相对日期:±{number_of_time_units}{time_unit}。您可以使用以下时间单位:
-1h(1 小时前)
+2d(从现在开始 2 天后)
-120m(120 分钟前)
5000s(从现在开始 5000 秒后)
-3w(3 周前)
+4M(从现在开始 4 个月后)
-1y(1 年前)
在加载数据集时(也就是在初始化交互式会话时,或者在启动关联作业时)评估相对日期。这就是在前面示例中所谓“现在”的时刻。
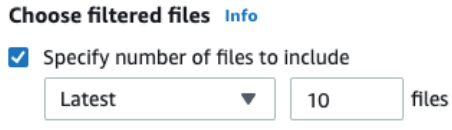
配置动态数据集的设置
除了提供参数化 S3 路径外,您还可以为包含多个文件的数据集配置其他设置。这些设置按上次修改日期筛选 S3 文件并限制文件数。
与在路径中设置日期参数类似,您可以定义更新匹配文件的时间范围,并仅将这些文件包含到数据集中。您可以使用绝对日期(例如“2021 年 3 月 30 日”)或相对范围(例如“过去 24 小时”)来定义这些范围。
要限制匹配文件的数量,请选择大于 0 的文件数,以及您想要的是最新还是最旧的匹配文件。