Amazon Forecast 不再向新买家开放。Amazon Forecast 的现有客户可以继续照常使用该服务。了解更多
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
预测可解释性
预测可解释性可帮助您更好地了解数据集中的属性会如何对特定时间序列(项目和维度组合)和时间点的预测产生影响。Forecast 使用名为影响力分数的指标来量化每个属性的相对影响,并确定它们是增加还是减少预测值。
例如,假设一个预测场景,其中目标是 sales,并且有两个相关的属性:price 和 color。Forecast 可能会发现商品的颜色对某些商品的销售影响很大,但对其他商品的影响可以忽略不计。它还可能发现,夏季促销活动对销售的影响很大,但是冬季促销活动效果不大。
要启用预测可解释性,您的预测器必须至少包含以下其中一项:相关时间序列、项目元数据或其他数据集,例如节假日和天气指数。请参阅限制和最佳实践了解更多信息。
要查看数据集中所有时间序列和时间点的汇总影响力分数,请使用预测器可解释性,而不是预测可解释性。请参阅预测器可解释性。
解释影响力分数
影响力分数衡量属性对预测值的相对影响。例如,如果“价格”属性的影响力分数是“商店位置”属性的两倍,则可以得出结论,某件商品的价格对预测值的影响是商店位置的两倍。
影响力分数还提供有关属性会增加还是减少预测值的信息。在控制台中,这由两个图表表示。带有蓝条的属性会增加预测值,而带有红条的属性会降低预测值。
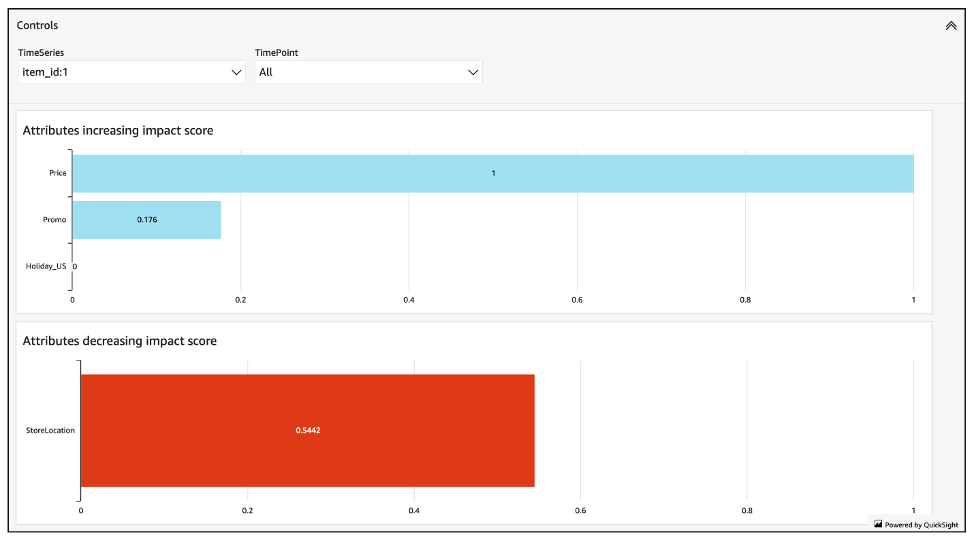
值得注意的是,影响力分数衡量的是属性的相对影响,而不是绝对影响。因此,不能使用影响力分数来确定特定属性是否提高了模型准确性。如果某个属性的影响力分数较低,这并不一定意味着它对预测值的影响较小;而是意味着它对预测值的影响要小于预测器使用的其他属性。
全部或部分影响力分数可能为零。如果要素对预测值没有影响,仅 AutoPredictor 使用非机器学习算法,或者您未提供相关的时间序列或项目元数据,则可能会发生这种情况。
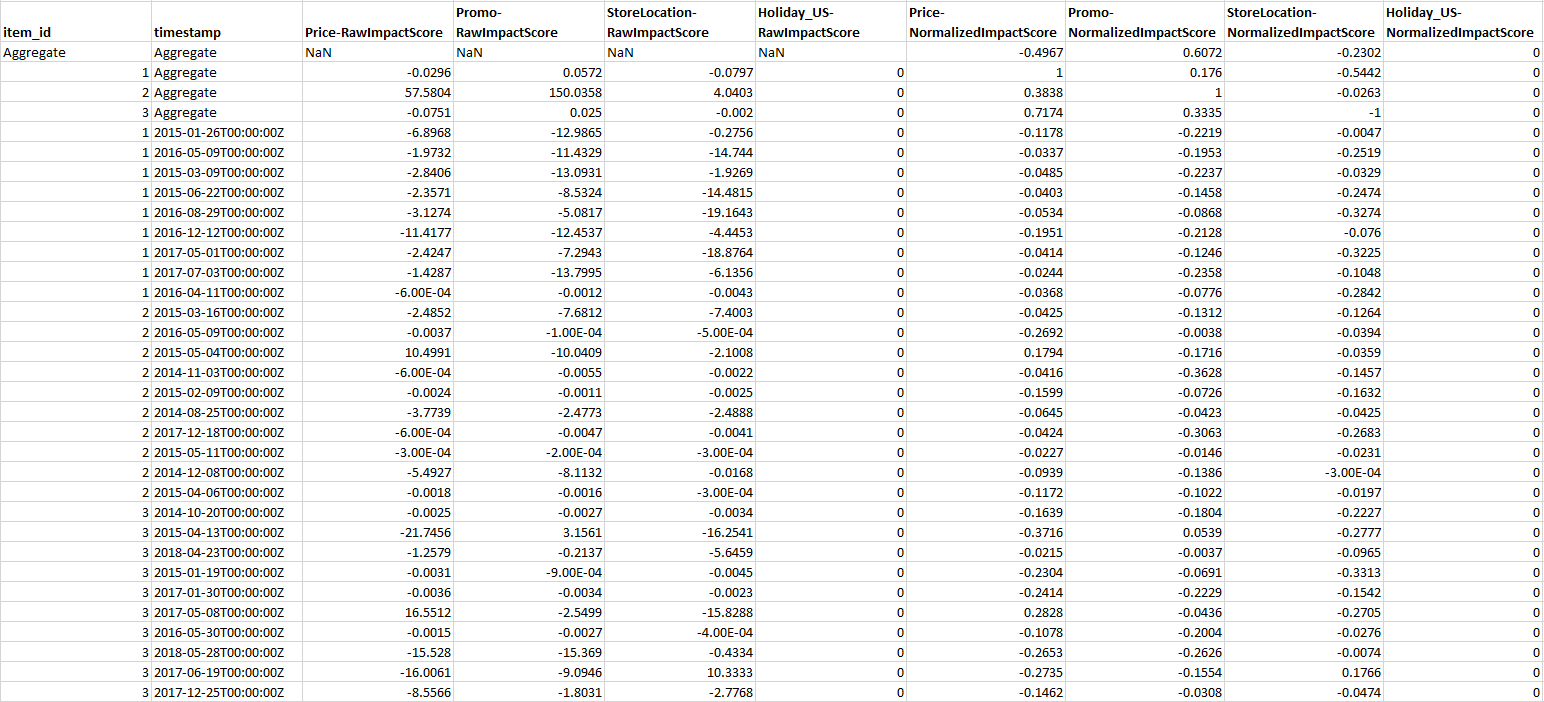
针对预测可解释性,影响力分数有两种形式:标准化影响力分数和原始影响力分数。原始影响力分数基于 Shapley 值,没有缩放或限制。标准化影响力分数将原始分数缩放到介于 -1 和 1 之间的值。
原始影响力分数对于组合和比较不同可解释性资源的分数非常有用。例如,如果您的预测器包含 50 多个时间序列或 500 多个时间点,则可以创建多个预测可解释性资源以涵盖更多的时间序列或时间点的组合数量,并直接比较属性的原始影响力分数。但是,来自不同预测的预测可解释性资源的原始影响力分数无法直接比较。
在控制台中查看影响力分数时,只能看到标准化影响力分数。导出可解释性将为您提供原始分数和标准化分数。
创建预测可解释性
借助预测可解释性,您可以探索属性如何影响特定时间序列在特定时间点的预测值。指定时间序列和时间点后,Amazon Forecast 仅计算这些特定时间序列和时间点的影响力分数。
您可以使用软件开发工具包(SDK)或 Amazon Forecast 控制台为预测器启用预测可解释性。使用 SDK 时,请使用CreateExplainability操作。
指定时间序列
注意
时间序列是数据集中项目 (item_id) 和所有维度的组合
当您为预测可解释性指定时间序列(项目和维度组合)时,Amazon Forecast 仅计算这些特定时间序列属性的影响力分数。
要指定时间序列列表,请将通过 item_id 和维度值标识时间序列的 CSV 文件上载到 S3 存储桶中。您最多可指定 50 个时间序列。您还必须定义架构中时间序列的属性和属性类型。
例如,零售商可能想知道促销活动如何影响特定商品 (item_id) 在特定商店位置的销售 (store_location)。在此用例中,您需要指定由 item_id 和 store_location 组合的时间序列。
以下 CSV 文件选择以下五个时间序列:
-
Item_id: 001,商店地点:西雅图
-
Item_id: 001,商店地点:纽约
-
Item_id: 002,商店地点:西雅图
-
Item_id: 002,商店地点:纽约
-
Item_id: 003,商店地点:丹佛
001, Seattle 001, New York 002, Seattle 002, New York 003, Denver
架构将第一列定义为 item_id,第二列定义为 store_location。
您可以使用 Forecast 控制台或 Forecast 软件开发工具包(SDK)指定时间序列。
指定时间点
注意
如果您未指定时间点 ("TimePointGranularity":
"ALL"),Amazon Forecast 将在计算影响力分数时考虑整个预测范围。
当您为预测可解释性指定时间点时,Amazon Forecast 会计算该特定时间范围内的属性的影响力分数。在预测范围内,您最多可以指定 500 个连续时间点。
例如,零售商可能想知道时间点的属性如何影响冬季的销售。在此用例中,零售商将指定仅跨越预测范围内冬季期间的时间点。
您可以使用 Forecast 控制台或 Forecast 软件开发工具包(SDK)指定时间点。
可视化预测可解释性
在控制台中创建预测可解释性时,Forecast 会自动可视化您的影响力分数。使用CreateExplainability操作创建 Forecast Explainability 时,EnableVisualization将其设置为 “true”,该可解释性资源的影响分数将在控制台中可视化。
影响力分数可视化自可解释性创建之日起持续 30 天。要重新创建可视化,请创建新的预测可解释性。
导出预测可解释性
注意
导出的文件可以直接从数据集导入中返回信息。如果导入的数据包含公式或命令,则文件易受 CSV 注入影响。因此,导出的文件可能会提示安全警告。为避免恶意活动,请在读取导出的文件时禁用链接和宏。
Forecast 允许您将影响力分数的 CSV 文件导出到 S3 位置。
导出内容包含指定时间序列的原始影响力分数和标准化影响力分数,以及所有指定时间序列和所有指定时间点的标准化汇总影响力分数。如果您未指定时间点,则预测范围内所有时间点的影响力分数均已汇总。
您可以使用 Amazon Forecast 软件开发工具包(SDK)和 Amazon Forecast 控制台导出预测可解释性。
限制和最佳实践
使用预测可解释性时,请考虑以下限制和最佳实践。
-
For@@ ecast Explainability 仅适用于从中生成的某些预测 AutoPredictor - 您无法为根据传统预测变量(自动或手动选择)生成的预测启用预测可解释性。请参阅升级到 AutoPredictor。
-
F@@ orecast Explainability 并非适用于所有模型 — ARIMA(AutoRegressive 综合移动平均线)、ETS(指数平滑状态空间模型)和 NPTS(Non-Parametric 时间序列)模型不包含外部时间序列数据。因此,即使您包含了其他数据集,这些模型也不会创建可解释性报告。
-
可解释性需要属性 - 您的预测器必须至少包含以下其中一项:相关时间序列、项目元数据、节假日或天气指数。
-
影响力分数为零表示没有影响 - 如果一个或多个属性的影响力分数为零,则这些属性对预测值没有显著影响。如果仅 AutoPredictor 使用非 ML 算法,或者您未提供相关的时间序列或项目元数据,则分数也可以为零。
-
最多指定 50 个时间序列 - 每个预测可解释性最多可以指定 50 个时间序列。
-
最多指定 500 个时间点 - 每个预测可解释性最多可以指定 500 个连续时间点。
-
Forecast 还会计算一些汇总的影响力分数 - Forecast 还将提供指定时间序列和时间点的汇总影响力分数。
-
为单个 Forecast 创建多个预测可解释性资源 - 如果您想要 50 多个时间序列或 500 多个时间点的影响力分数,则可以分批创建可解释性资源以覆盖更大的范围。
-
比较不同的预测可解释性资源的原始影响力分数 - 可以直接比较来自同一预测的可解释性资源的原始影响力分数。
-
预测可解释性可视化在创建后 30 天内可用 - 要在 30 天后查看可视化,请使用相同的配置创建新的预测可解释性。
