计划用于添加新分区的增量爬取
您可以配置 AWS Glue 爬网程序运行增量爬取,以仅向表架构添加新分区。爬网程序首次运行时,它会执行完全爬取来处理整个数据来源,以记录 AWS Glue Data Catalog 中完整的架构和所有现有分区。
初始完全爬取之后的后续爬取将是增量式的,其中爬网程序仅识别并添加自上次爬取以来引入的新分区。这种方法可以缩短爬取时间,因为爬网程序不再需要每次运行时处理整个数据来源,而是只关注新分区。
注意
增量爬取不会检测对现有分区的修改或删除。此配置最适合具有稳定架构的数据来源。如果发生一次性的重大架构变更,建议暂时将爬网程序设置为执行完全爬取以准确捕获新架构,然后再切换回增量爬取模式。
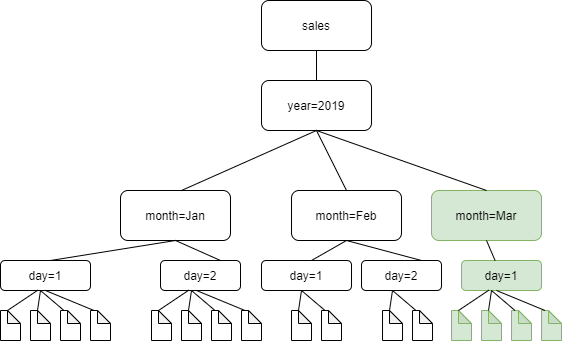
下图显示,启用增量爬取设置后,爬网程序仅检测新添加的文件夹 month=March 并将其添加到目录中。
请按照以下步骤更新爬网程序以执行增量爬取:
注释和限制
启用此选项后,您无法在编辑爬网程序时更改 Amazon S3 目标数据存储。此选项会影响某些爬网程序配置设置。启用后,它会将爬网程序的更新行为和删除行为强制为 LOG。这意味着:
-
如果发现架构不兼容的对象,爬网程序将不会在 Data Catalog 中添加这些对象,而是将此详细信息作为日志添加到 CloudWatch Logs 中。
-
它不会更新 Data Catalog 中的已删除对象。
