本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用亚马逊托管 Grafana 监控 Kafka 应用程序的解决方案
基于 Apache Kafka
注意
此解决方案不支持监控适用于 Apache Kafka 的 Apache Managed Streaming 应用程序。有关监控亚马逊MSK应用程序的信息,请参阅《适用于 A pache 的亚马逊托管流媒体 Kafka 开发者指南》中的 “监控亚马逊MSK集群”。
此解决方案配置:
-
您的亚马逊托管服务 Prometheus 工作空间,用于存储来自您的亚马逊集群的 Kafka 和 Java 虚拟机 (JVM) 指标。EKS
-
使用代理以及 CloudWatch CloudWatch 代理插件收集特定的 Kafka 和JVM指标。这些指标配置为发送到适用于 Prometheus 的亚马逊托管服务工作区。
-
您的 Amazon Managed Grafana 工作区用于提取这些指标,并创建控制面板来帮助您监控集群。
注意
此解决方案为在亚马逊上运行的应用程序提供JVM了 Kafka 指标EKS,但不包括亚马逊EKS指标。您可以使用可观察性解决方案来监控 Amazon,EKS以查看您的 Amazon EKS 集群的指标和警报。
关于此解决方案
此解决方案将亚马逊托管 Grafana 工作空间配置为你的 Apache Kafka 应用程序提供指标。这些指标用于生成仪表板,通过深入了解 Kafka 应用程序的性能和工作负载,帮助您更有效地操作应用程序。
下图显示了此解决方案创建的其中一个仪表板的示例。
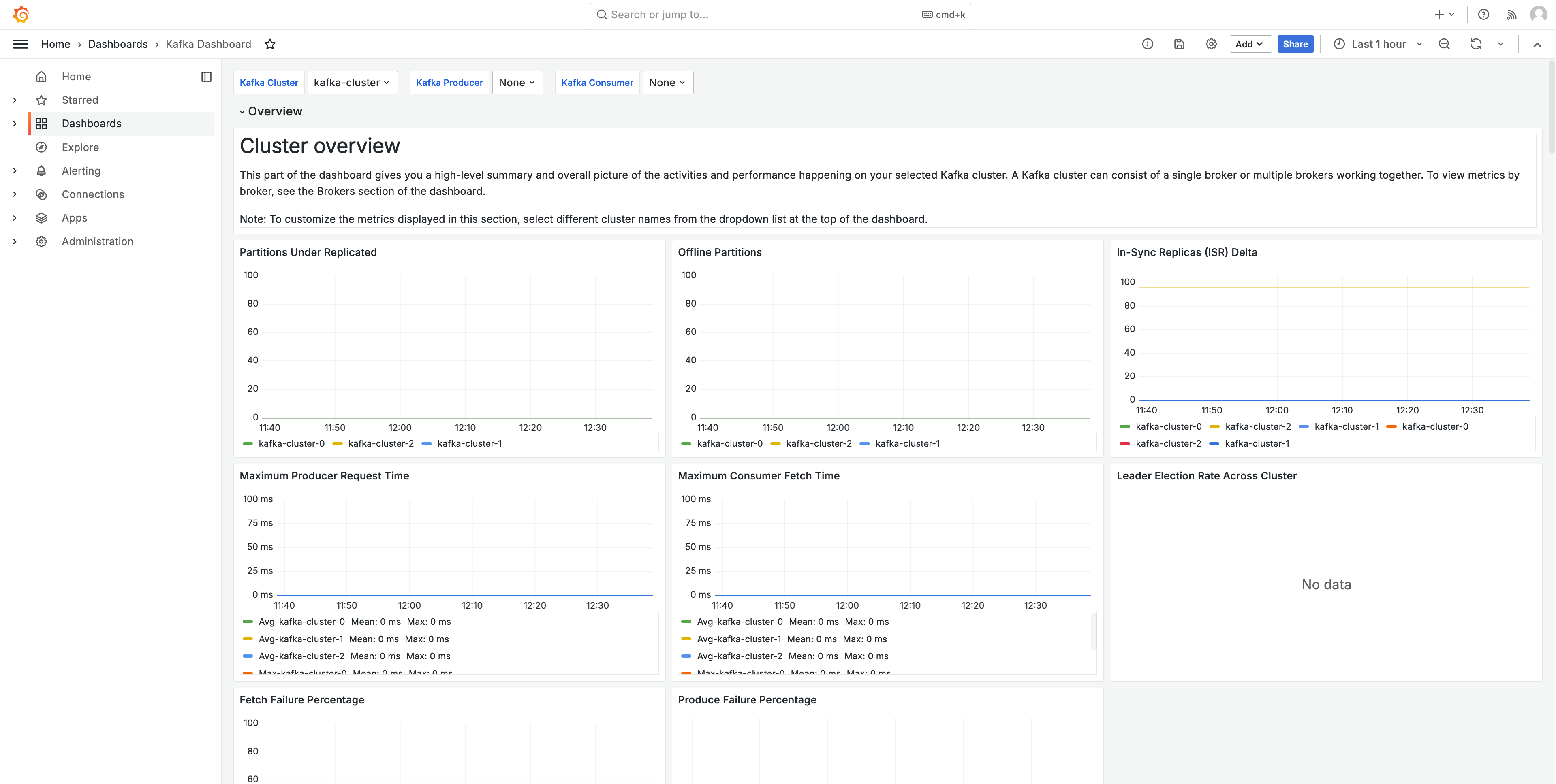
这些指标以 1 分钟的抓取间隔进行抓取。控制面板根据特定指标显示聚合到 1 分钟、5 分钟或更长时间的指标。
有关此解决方案跟踪的指标的列表,请参阅 跟踪的指标的列表。
成本
此解决方案在您的工作区中创建和使用资源。您需要为创建的资源的标准使用量付费,包括:
-
用户的 Amazon Managed Grafana 工作区访问权限。有关定价的更多信息,请参阅 Amazon Managed Grafana 定价
。 -
适用于 Prometheus 的亚马逊托管服务指标摄取和存储,以及指标分析(查询样本处理)。此解决方案使用的指标数量取决于您的应用程序配置和使用情况。
您可以使用在 Prometheus 的亚马逊托管服务中查看摄取和存储指标。有关更多信息,请参阅适用于 Prometheus CloudWatch 的亚马逊托管服务用户CloudWatch指南中的指标。
您可以使用 Amazon Managed Service for Prometheus 定价
页面上的定价计算器估算成本。指标的数量将取决于集群中的节点数量以及您的应用程序生成的指标。 -
联网成本。跨可用区、区域或其他流量可能会产生标准 AWS 网络费用。
每种产品的定价页面上都有定价计算器,可以帮助您了解解决方案的潜在成本。以下信息可以帮助计算在与 Amazon EKS 集群相同的可用区中运行的解决方案的基本成本。
| 产品 | 计算器指标 | 值 |
|---|---|---|
Amazon Managed Service for Prometheus |
活跃序列 |
95(每个 Kafka pod) |
平均收集间隔 |
60(秒) |
|
Amazon Managed Grafana |
活跃编辑/管理员数量 |
1(或更多,视您的用户而定) |
这些数字是在亚马逊EKS上运行 Kafka 的解决方案的基数。这些数字将为您提供基本成本的估算。如图所示,在向应用程序中添加 Kafka pod 时,成本将会增加。这些费用不包括网络使用成本,具体取决于亚马逊托管 Grafana 工作空间、适用于 Prometheus 的亚马逊托管服务工作空间和EKS亚马逊集群是否位于同一个可用区,以及。 AWS 区域 VPN
先决条件
此解决方案要求您在使用该解决方案之前完成以下操作。
-
您必须拥有或创建要监控的 Amazon Elastic Kubernetes Service 集群,并且该集群必须至少有一个节点。集群必须将API服务器终端节点访问权限设置为包括私有访问(它也可以允许公共访问)。
身份验证模式必须包括API访问权限(可以将其设置为
API或API_AND_CONFIG_MAP)。这允许解决方案部署使用访问权限条目。应在集群中安装以下内容(通过控制台创建集群时默认为真,但如果您使用 AWS API或创建集群,则必须添加 AWS CLI):Amazon EKS Pod Identity Agent、Core AWS CNI DNS、Kube-Proxy 和 Amazon D EBS CSI ri AddOns ver(从技术上讲,解决方案不需要亚马逊EBSCSI驱动程序 AddOn ,但大多数 Kafka 应用程序都需要亚马逊驱动程序)。
保存集群名称以便稍后指定。这可以在 Amazon EKS 控制台的集群详细信息中找到。
注意
有关如何创建 Amazon EKS 集群的详细信息,请参阅 Amazon 入门EKS。
-
您必须在亚马逊EKS集群上的 Java 虚拟机上运行 Apache Kafka 应用程序。
-
您必须在与您的亚马逊集群相同 AWS 账户 的工作空间中创建适用于 Prometheus 的亚马逊托管服务工作空间。EKS有关详细信息,请参阅《Amazon Managed Service for Prometheus 用户指南》中的创建工作区。
保存适用于 Prometheus 的亚马逊托管服务工作区以供日后ARN指定。
-
您必须使用 Grafana 版本 9 或更高版本创建 Amazon 托管 Grafana 工作空间,与您的亚马逊集群相同。 AWS 区域 EKS有关创建新工作区的详细信息,请参阅 创建 Amazon Managed Grafana 工作区。
工作空间角色必须具有访问适用于 Prometheus 和亚马逊的亚马逊托管服务的权限。 CloudWatch APIs最简单的方法是使用服务托管权限,然后选择 Prometheus 和 Amazon 托管服务。 CloudWatch您也可以手动将AmazonPrometheusQueryAccess和AmazonGrafanaCloudWatchAccess策略添加到您的工作空间IAM角色中。
保存 Amazon Managed Grafana 工作区 ID 和端点,以便日后指定。ID 的格式为
g-123example。ID 和端点可在 Amazon Managed Grafana 控制台中找到。终端节点是URL工作空间的,包括 ID。例如,https://g-123example.grafana-workspace.<region>.amazonaws.com/。
注意
虽然不是严格要求设置解决方案,但您必须先在 Amazon Managed Grafana 工作区中设置用户身份验证,然后用户才能访问创建的控制面板。有关更多信息,请参阅 在 Amazon Managed Grafana 工作区中对用户进行身份验证。
使用此解决方案
此解决方案将 AWS 基础设施配置为支持 Ama EKS zon 集群中运行的 Kafka 应用程序的报告和监控指标。你可以使用安装它AWS Cloud Development Kit (AWS CDK)。
使用此解决方案监控 Amazon EKS 集群 AWS CDK
-
请确保您已完成了所有先决条件步骤。
-
从 Amazon S3 中下载解决方案的所有文件。这些文件位于
s3://aws-observability-solutions/Kafka_EKS/OSS/CDK/v1.0.0/iac,您可以使用以下 Amazon S3 命令下载它们。在命令行环境中的文件夹中运行此命令。aws s3 sync s3://aws-observability-solutions/Kafka_EKS/OSS/CDK/v1.0.0/iac/ .您无需修改这些文件。
-
在您的命令行环境中(从您下载解决方案文件的文件夹),运行以下命令。
设置所需的环境变量。将
REGION、AMG_ENDPOINTEKS_CLUSTER、和AMP_ARN替换为您 AWS 区域的 Amazon Managed Grafana 工作空间终端节点(表格中http://g-123example.grafana-workspace.us-east-1.amazonaws.com)、亚马逊集群名称和适用于 Pro EKS metheus 的亚马逊托管服务工作空间。ARNexport AWS_REGION=REGIONexport AMG_ENDPOINT=AMG_ENDPOINTexport EKS_CLUSTER_NAME=EKS_CLUSTERexport AMP_WS_ARN=AMP_ARN -
您必须创建可供部署使用的注释。你可以选择直接为命名空间、部署、statefulset、daemonset 或 pod 添加注释。Kafka 解决方案需要五个注解。您将使用以下命令
kubectl对资源进行标注:kubectl annotate<resource-type><resource-value>instrumentation.opentelemetry.io/inject-java=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-jvm=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka-producer=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka-consumer=true将
<resource-type>和<resource-value>替换为适用于您的系统的正确值。例如,要为foo部署添加注释,您的第一个命令将是:kubectl annotate deployment foo instrumentation.opentelemetry.io/inject-java=true -
创建具有调用 Grafana ADMIN HTTP APIs 权限的服务账号令牌。有关详细信息,请参阅使用服务账户通过 Grafana HTTP API 进行身份验证。您可以通过以下命令使用来创建令牌。 AWS CLI 您需要将 Grafana 工作区的 ID 替换为 Grafana 工作区的 ID(它将在表单中)。
GRAFANA_IDg-123example此密钥将在 7200 秒或 2 小时后过期。如果需要,可以更改时间(seconds-to-live)。部署需要不到一小时的时间。# creates a new service account (optional: you can use an existing account) GRAFANA_SA_ID=$(aws grafana create-workspace-service-account \ --workspace-idGRAFANA_ID\ --grafana-role ADMIN \ --name grafana-operator-key \ --query 'id' \ --output text) # creates a new token for calling APIs export AMG_API_KEY=$(aws grafana create-workspace-service-account-token \ --workspace-id $managed_grafana_workspace_id \ --name "grafana-operator-key-$(date +%s)" \ --seconds-to-live 7200 \ --service-account-id $GRAFANA_SA_ID \ --query 'serviceAccountToken.key' \ --output text)使用以下命令将API密钥添加 AWS CDK 到,使该 AWS Systems Manager 密钥可供使用。
AWS_REGION替换为您的解决方案将要运行的区域(在表单中us-east-1)。aws ssm put-parameter --name "/observability-aws-solution-kafka-eks/grafana-api-key" \ --type "SecureString" \ --value $AMG_API_KEY \ --regionAWS_REGION\ --overwrite -
运行以下
make命令,这将为项目安装任何其他依赖项。make deps -
最后,运行该 AWS CDK 项目:
make build && make pattern aws-observability-solution-kafka-eks-$EKS_CLUSTER_NAME deploy -
[可选] 堆栈创建完成后,您可以使用相同的环境为在同一区域的亚马逊EKS集群上运行的其他 Kafka 应用程序创建更多堆栈实例,前提是您满足每个应用程序的其他先决条件(包括单独的 Amazon Managed Grafana 和适用于 Prometheus 的亚马逊托管服务工作空间)。您将需要使用新参数重新定义
export命令。
堆栈创建完成后,您的 Amazon Managed Grafana 工作空间将填充一个控制面板,显示您的应用程序和亚马逊集群的指标。EKS在收集指标后,需要几分钟才能显示指标。
跟踪的指标的列表
此解决方案从JVM基于您的 Kafka 应用程序收集指标。这些指标存储在 Amazon Managed Service for Prometheus 中,然后显示在 Amazon Managed Grafana 控制面板中。
使用此解决方案可以跟踪以下指标。
jvm.classes.load
jvm.gc.collections.count
jvm.gc.collections.elapsed
jvm.memory.heap.init
jvm.memory.heap.max
jvm.memory.heap.used
jvm.memory.heap.commited
jvm.memory.nonheap.init
jvm.memory.nonheap.max
jvm.memory.nonheap.used
jvm.memory.nonheap.commited
jvm.memory.pool.init
jvm.memory.pool.max
jvm.memory.pool.used
jvm.memory.pool.commit
jvm.threads.count
kafka.message.count
kafka.count
kafka.request.f
kafka.request.time.t
kafka.request.time.50p
kafka.request.time.99p
kafka.request.time.avg
kafka.network.i
kafka.purgatory.size
kafka.partition.count
kafka.partition.of
kafka.partition.under_rep
kafka.isr.operation.co
kafka.max.lag
kafka.controller.active.count
kafka.leader.election.rate
kafka.unclean.election.rate
kafka.requeut.q
kafka.logs.flush.time.co
kafka.logs.flush.time.m
kafka.logs.flush.time.99p
kafka.consumer.fetch-rate
kafka.consumer records-lag-max
kafka.consumer.total。 bytes-consumed-rate
kafka.consumer.total。 fetch-size-avg
kafka.consumer.total。 records-consumed-rate
kafka.consumer bytes-consumed-rate
kafka.consumer fetch-size-avg
kafka.consumer records-consumed-rate
kafka.produc io-wait-time-ns-平均
kafka.produc outgoing-byte-rate
kafka.produc request-latency-avg
kafka.producer.request-
kafka.producer.response
kafka.producer.byte-r
kafka.producer.压缩率
kafka.produc record-error-rate
kafka.produc record-retry-rate
kafka.produc record-send-rate
问题排查
有几种情况可能会导致项目设置失败。务必检查以下内容:
-
安装解决方案之前,必须完成所有先决条件。
-
在尝试创建解决方案或访问指标之前,集群中必须至少有一个节点。
-
您的 Amazon EKS 集群必须安装
CoreDNS和kube-proxy附加组件。AWS CNI如果未安装这些附加组件,则解决方案将无法正常运行。默认情况下,会在通过控制台创建集群时进行安装。如果集群是通过创建的,则可能需要安装它们 AWS SDK。 -
亚马逊 EKS pod 安装超时。如果没有足够的可用节点容量,就会发生这种情况。造成这些问题的原因有多种,包括:
-
亚马逊集EKS群是用 Fargate 而不是亚马逊初始化的。EC2此项目需要亚马逊EC2。
-
节点已被污染,因此不可用。
您可以使用
kubectl describe node来检查污点。然后使用NODENAME| grep Taintskubectl taint node来移除污点。请确保在污点名称后加上NODENAMETAINT_NAME--。 -
节点已达到容量限制。在这种情况下,您可以创建新节点或增加容量。
-
-
您在 Grafana 中看不到任何控制面板:使用了错误的 Grafana 工作区 ID。
运行以下命令可获取有关 Grafana 的信息。
kubectl describe grafanas external-grafana -n grafana-operator您可以检查正确的工作空间的结果URL。如果 URL 不是您期望的 URL,请使用正确的工作区 ID 重新部署。
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
您在 Grafana 中看不到任何仪表板:您使用的密钥已过期。API
要查找这种情况,您需要找到 Grafana 操作员并检查日志中是否有错误。使用以下命令获取 Grafana 操作员的姓名:
kubectl get pods -n grafana-operator这将返回操作员姓名,例如:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2m在以下命令中使用操作员名称:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operator诸如以下的错误消息表示API密钥已过期:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).Reconcile在这种情况下,请创建一个新API密钥并重新部署解决方案。如果问题仍然存在,则可以在重新部署之前使用以下命令强制同步:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
缺少SSM参数。如果您看到类似于以下内容的错误,请运行
cdk bootstrap并重试。Deployment failed: Error: aws-observability-solution-kafka-eks-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html)
