终止支持通知:2026 年 10 月 7 日,AWS将停止对的支持。AWS IoT Greengrass Version 1 2026 年 10 月 7 日之后,您将无法再访问这些AWS IoT Greengrass V1资源。如需了解更多信息,请访问迁移自AWS IoT Greengrass Version 1。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
可选:配置设备进行 ML 资格认证
IDT fo AWS IoT Greengrass r 提供机器学习 (ML) 资格测试,以验证您的设备是否可以使用云训练模型在本地执行 ML 推理。
要运行 ML 资格认证测试,必须先按照配置设备以运行 IDT 测试中的说明配置设备。然后,按照本主题中的步骤安装要运行的 ML 框架的依赖项。
需要有 IDT v3.1.0 或更高版本才能运行 ML 资格认证测试。
安装 ML 框架依赖项
所有 ML 框架依赖项都必须安装在 /usr/local/lib/python3.x/site-packages 目录下。为确保将这些依赖项安装在正确的目录下,建议您在安装时使用 sudo root 权限。资格认证测试不支持虚拟环境。
注意
如果您正在测试使用容器化运行的 Lambda 函数(在 Greengrass 容器模式下),则不支持为 /usr/local/lib/python3.x 下的 Python 库创建符号链接。为避免错误,必须在正确的目录下安装依赖项。
按照以下步骤安装目标框架的依赖项:
安装 Apache MXNet 依赖项
此框架的 IDT 资格认证测试具有以下依赖项:
-
Python 3.6 或 Python 3.7。
注意
如果您使用的是 Python 3.6,则必须创建从 Python 3.7 二进制文件到 Python 3.6 二进制文件的符号链接。这会将设备配置为满足 AWS IoT Greengrass的 Python 要求。例如:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
Apache MXNet v1.2.1 或更高版本。
-
NumPy。 该版本必须与您的 MXnet 版本兼容。
正在安装 MXNet
按照 MXNet 文档中的说明安装 MXNet
注意
如果设备上同时安装了 Python 2.x 和 Python 3.x,请在运行来安装依赖项的命令中使用 Python 3.x。
验证 MXNet 安装
选择以下一种方式来验证 MXNet 安装。
方式 1:通过 SSH 接入设备并运行脚本
-
通过 SSH 接入设备。
-
运行以下脚本,验证是否正确安装了依赖项。
sudo python3.7 -c "import mxnet; print(mxnet.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"结果将输出版本号,而脚本应该顺利退出。
方式 2:运行 IDT 依赖项测试
-
确保已配置
device.json用于执行 ML 资格认证。有关更多信息,请参阅 为 ML 资格认证配置 device.json。 -
运行框架的依赖项测试。
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id mxnet_dependency_check测试摘要会为
mldependencies显示PASSED结果。
安装 TensorFlow 依赖关系
此框架的 IDT 资格认证测试具有以下依赖项:
-
Python 3.6 或 Python 3.7。
注意
如果您使用的是 Python 3.6,则必须创建从 Python 3.7 二进制文件到 Python 3.6 二进制文件的符号链接。这会将设备配置为满足 AWS IoT Greengrass的 Python 要求。例如:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
TensorFlow 1.x。
正在安装 TensorFlow
按照 TensorFlow 文档中的说明使用 pip 或从源
注意
如果设备上同时安装了 Python 2.x 和 Python 3.x,请在运行来安装依赖项的命令中使用 Python 3.x。
验证安装 TensorFlow
选择以下选项之一来验证 TensorFlow 安装。
方式 1:通过 SSH 接入设备并运行脚本
-
通过 SSH 接入设备。
-
运行以下脚本,验证是否正确安装了依赖项。
sudo python3.7 -c "import tensorflow; print(tensorflow.__version__)"结果将输出版本号,而脚本应该顺利退出。
方式 2:运行 IDT 依赖项测试
-
确保已配置
device.json用于执行 ML 资格认证。有关更多信息,请参阅 为 ML 资格认证配置 device.json。 -
运行框架的依赖项测试。
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id tensorflow_dependency_check测试摘要会为
mldependencies显示PASSED结果。
安装 Amazon SageMaker AI Neo 深度学习运行时 (DLR) 依赖项
此框架的 IDT 资格认证测试具有以下依赖项:
-
Python 3.6 或 Python 3.7。
注意
如果您使用的是 Python 3.6,则必须创建从 Python 3.7 二进制文件到 Python 3.6 二进制文件的符号链接。这会将设备配置为满足 AWS IoT Greengrass的 Python 要求。例如:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
SageMaker AI Neo DLR。
-
numpy。
安装 DLR 测试依赖项后,必须编译模型。
安装 DLR
按照 DLR 文档中的说明安装 Neo DLR
注意
如果设备上同时安装了 Python 2.x 和 Python 3.x,请在运行来安装依赖项的命令中使用 Python 3.x。
验证 DLR 安装
选择以下一种选项来验证 DLR 安装。
方式 1:通过 SSH 接入设备并运行脚本
-
通过 SSH 接入设备。
-
运行以下脚本,验证是否正确安装了依赖项。
sudo python3.7 -c "import dlr; print(dlr.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"结果将输出版本号,而脚本应该顺利退出。
方式 2:运行 IDT 依赖项测试
-
确保已配置
device.json用于执行 ML 资格认证。有关更多信息,请参阅 为 ML 资格认证配置 device.json。 -
运行框架的依赖项测试。
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id dlr_dependency_check测试摘要会为
mldependencies显示PASSED结果。
编译 DLR 模型
必须先编译 DLR 模型,然后才能将其用于 ML 资格认证测试。有关具体步骤,请选择以下一种选项:
选项 1:使用 Amazon SageMaker AI 编译模型
按照以下步骤使用 SageMaker AI 编译 IDT 提供的机器学习模型。该模型已预先使用 Apache MXNet 进行训练。
-
验证 A SageMaker I 是否支持您的设备类型。有关更多信息,请参阅 Amazon AI AP SageMaker I 参考中的目标设备选项。如果 SageMaker AI 目前不支持您的设备类型,请按照中的步骤操作方式 2:使用 TVM 编译 DLR 模型。
注意
使用 SageMaker AI 编译的模型运行 DLR 测试可能需要 4 或 5 分钟。在此过程中请勿停止 IDT。
-
下载包含 DLR 的未编译、预训练 MXNet 模型的 tarball 文件:
-
解压缩该 tarball 文件。此命令会生成以下目录结构。

-
将
synset.txt移出resnet18目录。记下新位置。稍后,您需要将此文件复制到已编译的模型目录中。 -
压缩
resnet18目录的内容。tar cvfz model.tar.gz resnet18v1-symbol.json resnet18v1-0000.params -
将压缩文件上传到您的 Amazon S3 存储桶 AWS 账户,然后按照编译模型(控制台)中的步骤创建编译任务。
-
对于输入配置,请使用以下值:
-
对于数据输入配置,请输入
{"data": [1, 3, 224, 224]}。 -
对于机器学习框架,请选择
MXNet。
-
-
对于输出配置,请使用以下值:
-
对于 S3 输出位置,请输入要存储已编译模型的 Amazon S3 存储桶或文件夹的路径。
-
对于目标设备,请选择您的设备类型。
-
-
-
从指定的输出位置下载已编译的模型,然后解压缩该文件。
-
将
synset.txt复制到已编译的模型目录中。 -
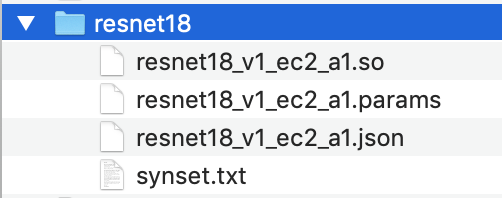
将已编译的模型目录的名称更改为
resnet18。已编译的模型目录必须具有以下目录结构。
方式 2:使用 TVM 编译 DLR 模型
按照以下步骤使用 TVM 编译 IDT 提供的 ML 模型。此模型已预先使用 Apache MXNet 进行训练,因此您必须在编译模型的计算机或设备上安装 MXNet。要安装 MXNet,请按照 MXNet 文档
注意
我们建议您在目标设备上编译模型。此做法是可选的,但它可以帮助确保兼容性并减少潜在问题。
-
下载包含 DLR 的未编译、预训练 MXNet 模型的 tarball 文件:
-
解压缩该 tarball 文件。此命令会生成以下目录结构。
-
按照 TVM 文档中的说明,从源代码为平台构建和安装 TVM
。 -
构建 TVM 后,为 resnet18 模型运行 TVM 编译。以下步骤根据 TVM 文档中的编译深度学习模型快速入门教程
的内容设计而成。 -
从克隆的 TVM 存储库中打开
relay_quick_start.py文件。 -
更新在 Relay 中定义神经网络
的代码。可以使用以下选项之一: -
选项 1:使用
mxnet.gluon.model_zoo.vision.get_model获取 Relay 模块和参数:from mxnet.gluon.model_zoo.vision import get_model block = get_model('resnet18_v1', pretrained=True) mod, params = relay.frontend.from_mxnet(block, {"data": data_shape}) -
选项 2:将您在步骤 1 中下载的未编译模型中的以下文件复制到
relay_quick_start.py文件所在的目录。这些文件中包含了 Relay 模块和参数。-
resnet18v1-symbol.json -
resnet18v1-0000.params
-
-
-
将保存和加载已编译模块
的代码更新为以下代码。 from tvm.contrib import util path_lib = "deploy_lib.so" # Export the model library based on your device architecture lib.export_library("deploy_lib.so", cc="aarch64-linux-gnu-g++") with open("deploy_graph.json", "w") as fo: fo.write(graph) with open("deploy_param.params", "wb") as fo: fo.write(relay.save_param_dict(params)) -
构建模型:
python3 tutorials/relay_quick_start.py --build-dir ./model此命令会生成以下文件。
-
deploy_graph.json -
deploy_lib.so -
deploy_param.params
-
-
-
将生成的模型文件复制到名为
resnet18的目录中。这是已编译的模型目录。 -
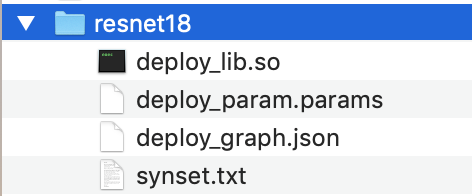
将已编译的模型目录复制到主机计算机。然后,将您在步骤 1 中下载的未编译模型中的
synset.txt复制到已编译的模型目录中。已编译的模型目录必须具有以下目录结构。
接下来,配置您的 AWS 凭据和device.json文件。
