终止支持通知:2026 年 10 月 7 日,AWS将停止对的支持。AWS IoT Greengrass Version 1 2026 年 10 月 7 日之后,您将无法再访问这些AWS IoT Greengrass V1资源。如需了解更多信息,请访问迁移自AWS IoT Greengrass Version 1。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将数据流导出到 AWS Cloud (CLI)
本教程向您展示如何使用配置和部署启用了流管理器的 AWS IoT Greengrass 群组。 AWS CLI 该组包含一个用户定义的 Lambda 函数,该函数可以在流管理器中写入流,然后将其自动导出到 AWS Cloud中。
流管理器使得摄取、处理和导出大容量数据流更高效也更可靠。在本教程中,您将创建一个使用 IoT 数据的 TransferStream Lambda 函数。Lambda 函数使用 AWS IoT Greengrass Core SDK 在流管理器中创建流,然后对其进行读取和写入。然后,流管理器将流导出到 Kinesis Data Streams。下图演示了此工作流程。
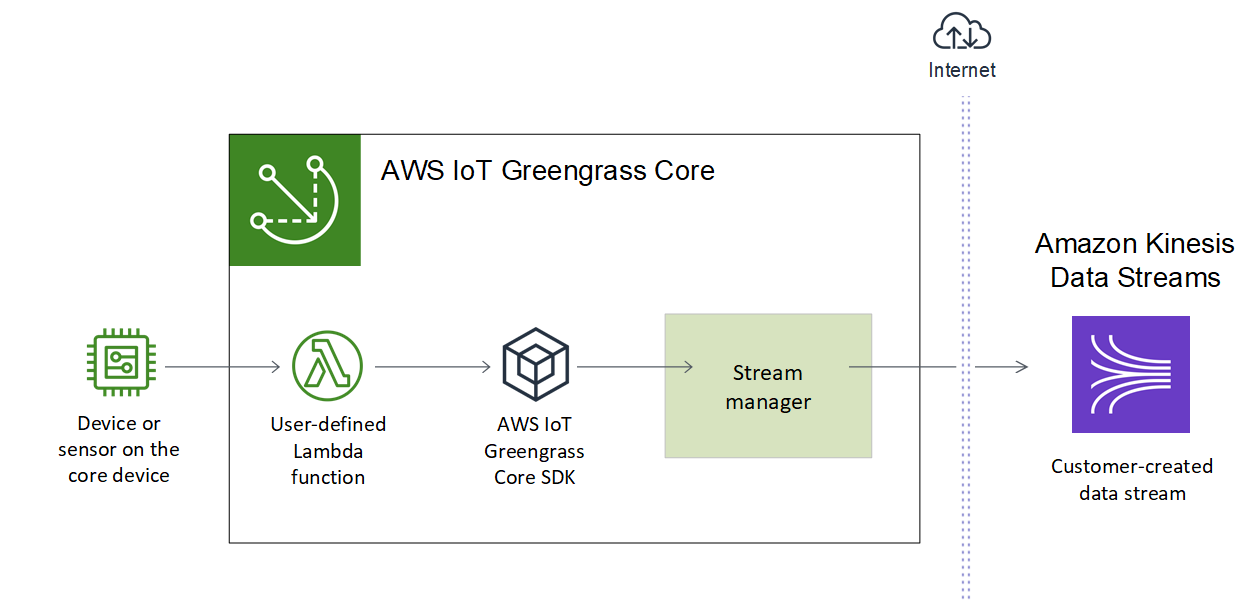
本教程的重点是展示用户定义的 Lambda 函数如何使用 AWS IoT Greengrass Core SDK 中的StreamManagerClient对象与流管理器进行交互。为简单起见,您为本教程创建的 Python Lambda 函数将生成模拟设备数据。
当您使用 AWS IoT Greengrass API(其中包含 Greengrass 命令)创建群组时,直播管理器默认处于 AWS CLI禁用状态。要在核心上启用流管理器,您需要创建一个函数定义版本,其中包括系统 GGStreamManager Lambda 函数和一个引用新的函数定义版本的组版本。然后部署组。
先决条件
要完成此教程,需要:
-
Greengrass 组和 Greengrass Core(v1.10 或更高版本)。有关如何创建 Greengrass 组和核心的信息,请参阅 开始使用 AWS IoT Greengrass。入门教程还包括安装 AWS IoT Greengrass 核心软件的步骤。
注意
OpenWrt 发行版不支持直播管理器。
-
核心设备上安装的 Java 8 运行时 (JDK 8)。
-
对于 Debian-based 发行版(包括 Raspbian)或 Ubuntu-based 发行版,请运行以下命令:
sudo apt install openjdk-8-jdk -
对于 Red Hat-based 发行版(包括 Amazon Linux),请运行以下命令:
sudo yum install java-1.8.0-openjdk有关更多信息,请参阅 OpenJDK 文档中的如何下载并安装预先构建的 OpenJDK 程序包
。
-
-
AWS IoT Greengrass 适用于 Python 的核心开发工具包 v1.5.0 或更高版本。要在适用于 Python 的 AWS IoT Greengrass Core 软件开发工具包中使用
StreamManagerClient,您必须:-
在核心设备上安装 Python 3.7 或更高版本。
-
将开发工具包和其依赖项包含在 Lambda 函数部署程序包中。本教程中提供了说明。
提示
可以将
StreamManagerClient与 Java 或 NodeJS 结合使用。有关示例代码,请参阅适用于 Java 的AWS IoT Greengrass Core SDK和 Node.js上的 AWS IoT Greengrass Core SDK GitHub。 -
-
在 Amazon Kinesis Data Streams 中
MyKinesisStream创建的目标流,名称与你的 Greengrass 群组 AWS 区域 相同。有关更多信息,请参阅 Amazon Kinesis 开发人员指南中的创建流。注意
在本教程中,流管理器将数据导出到 Kinesis Data Streams,这将向您的 AWS 账户账户收取费用。有关定价的信息,请参阅 Kinesis Data Streams 定价
。 为避免产生费用,您可以在不创建 Kinesis 数据流的情况下运行本教程。在这种情况下,您检查日志以查看流管理器试图将流导出到 Kinesis Data Streams。
-
一个添加到了
kinesis:PutRecords的 IAM policy,该策略允许对目标数据流执行 Greengrass 组角色 操作,如以下示例所示:
-
AWS CLI 已在您的计算机上安装和配置。有关更多信息,请参阅 AWS Command Line Interface 用户指南中的安装 AWS Command Line Interface 和配置 AWS CLI 。
本教程中的示例命令是为 Linux 和其他 Unix-based 系统编写的。如果你使用的是 Windows,有关语法差异的更多信息,请参阅为 AWS 命令行界面指定参数值。
如果命令包含 JSON 字符串,本教程提供了在单行包含 JSON 的示例。在某些系统上,使用此格式可能会更高效地编辑和运行命令。
本教程包含以下概括步骤:
完成本教程大约需要 30 分钟。
步骤 1:创建 Lambda 函数部署程序包
在此步骤中,您创建包含 Python 函数代码和依赖项的 Lambda 函数部署包。您稍后在 AWS Lambda中创建 Lambda 函数时上传此程序包。Lambda 函数使用 AWS IoT Greengrass 核心软件开发工具包来创建本地流并与之交互。
注意
用户定义的 Lambda 函数必须使用 AWS IoT Greengrass 核心开发工具包与流管理器交互。有关 Greengrass 流管理器的要求的更多信息,请参阅 Greengrass 流管理器要求。
-
下载适用于 Python 的AWS IoT Greengrass Core 开发工具包 v1.5.0 或更高版本。
-
解压缩下载的程序包以获取软件开发工具包。软件开发工具包是
greengrasssdk文件夹。 -
安装程序包依赖项以将其包含在 Lambda 函数部署程序包的开发工具包中。
-
导航到包含该
requirements.txt文件的开发工具包目录。此文件列出了依赖项。 -
安装开发工具包依赖项。例如,运行以下
pip命令将它们安装在当前目录中:pip install --target . -r requirements.txt
-
-
将以下 Python 代码函数保存在名为
transfer_stream.py的本地文件中。提示
有关使用 Java 和 NodeJS 的示例代码,请参阅适用于 J ava 的 Core SDK AWS IoT Greengrass 和AWS IoT Greengrass 上的
Core SDK。 Node.js GitHub import asyncio import logging import random import time from greengrasssdk.stream_manager import ( ExportDefinition, KinesisConfig, MessageStreamDefinition, ReadMessagesOptions, ResourceNotFoundException, StrategyOnFull, StreamManagerClient, ) # This example creates a local stream named "SomeStream". # It starts writing data into that stream and then stream manager automatically exports # the data to a customer-created Kinesis data stream named "MyKinesisStream". # This example runs forever until the program is stopped. # The size of the local stream on disk will not exceed the default (which is 256 MB). # Any data appended after the stream reaches the size limit continues to be appended, and # stream manager deletes the oldest data until the total stream size is back under 256 MB. # The Kinesis data stream in the cloud has no such bound, so all the data from this script is # uploaded to Kinesis and you will be charged for that usage. def main(logger): try: stream_name = "SomeStream" kinesis_stream_name = "MyKinesisStream" # Create a client for the StreamManager client = StreamManagerClient() # Try deleting the stream (if it exists) so that we have a fresh start try: client.delete_message_stream(stream_name=stream_name) except ResourceNotFoundException: pass exports = ExportDefinition( kinesis=[KinesisConfig(identifier="KinesisExport" + stream_name, kinesis_stream_name=kinesis_stream_name)] ) client.create_message_stream( MessageStreamDefinition( name=stream_name, strategy_on_full=StrategyOnFull.OverwriteOldestData, export_definition=exports ) ) # Append two messages and print their sequence numbers logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "ABCDEFGHIJKLMNO".encode("utf-8")), ) logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "PQRSTUVWXYZ".encode("utf-8")), ) # Try reading the two messages we just appended and print them out logger.info( "Successfully read 2 messages: %s", client.read_messages(stream_name, ReadMessagesOptions(min_message_count=2, read_timeout_millis=1000)), ) logger.info("Now going to start writing random integers between 0 and 1000 to the stream") # Now start putting in random data between 0 and 1000 to emulate device sensor input while True: logger.debug("Appending new random integer to stream") client.append_message(stream_name, random.randint(0, 1000).to_bytes(length=4, signed=True, byteorder="big")) time.sleep(1) except asyncio.TimeoutError: logger.exception("Timed out while executing") except Exception: logger.exception("Exception while running") def function_handler(event, context): return logging.basicConfig(level=logging.INFO) # Start up this sample code main(logger=logging.getLogger()) -
将以下项目压缩到名为
transfer_stream_python.zip的文件中。此即 Lambda 函数部署程序包。-
transfer_stream.py。应用程序逻辑。
-
greengrasssdk。发布 MQTT 消息的 Python Greengrass Lambda 函数所需的库。
适用于 Python 的 AWS IoT Greengrass 核心 SDK 版本 1.5.0 或更高版本中提供了@@ 流管理器操作。
-
你为适用于 Python 的 AWS IoT Greengrass 核心 SDK 安装的依赖项(例如,
cbor2目录)。
创建
zip文件时,仅包含这些项目,而不是包含文件夹。 -
第 2 步:创建 Lambda 函数
-
创建 IAM 角色,以便您可以在创建该函数时传入角色 ARN。
注意
AWS IoT Greengrass 不使用这个角色,因为你的 Greengrass Lambda 函数的权限是在 Greengrass 群组角色中指定的。对于本教程,您将创建一个空角色。
-
从输出中复制
Arn。 -
使用 AWS Lambda API 创建
TransferStream函数。以下命令假定该 zip 文件位于当前目录中。-
将
role-arn替换为复制的Arn。
aws lambda create-function \ --function-name TransferStream \ --zip-file fileb://transfer_stream_python.zip \ --rolerole-arn\ --handler transfer_stream.function_handler \ --runtime python3.7 -
-
发布该函数的版本。
aws lambda publish-version --function-name TransferStream --description 'First version' -
为发布的版本创建别名。
Greengrass 组可以按别名(推荐)或版本引用 Lambda 函数。使用别名,您可以更轻松地管理代码更新,因为您在更新函数代码时,不必更改订阅表或组定义。相反,您只需将别名指向新的函数版本。
aws lambda create-alias --function-name TransferStream --name GG_TransferStream --function-version 1注意
AWS IoT Greengrass 不支持 $LATEST 版本的 Lambda 别名。
-
从输出中复制
AliasArn。在为配置函数时,您可以使用此值 AWS IoT Greengrass。
现在,您已准备好为配置该函数 AWS IoT Greengrass。
步骤 3:创建函数定义和版本
此步骤将创建引用系统 GGStreamManager Lambda 函数和用户定义的 TransferStream Lambda 函数的函数定义版本。要在使用 AWS IoT Greengrass API 时启用流管理器,您的函数定义版本必须包含该GGStreamManager函数。
-
创建一个包含初始版本的函数定义,该初始版本包含系统和用户定义的 Lambda 函数。
以下定义版本启用了具有默认参数设置的流管理器。要配置自定义设置,您必须为相应的流管理器参数定义环境变量。有关示例,请参阅启用、禁用或配置流管理器 (CLI)。 AWS IoT Greengrass 对省略的参数使用默认设置。
MemorySize至少应该是128000。Pinned必须设置为true。注意
长寿命(或固定)的 Lambda 函数在启动后 AWS IoT Greengrass 自动启动,并继续在自己的容器中运行。这与按需 Lambda 函数相反,后者在调用时启动,并在没有要运行的任务时停止。有关更多信息,请参阅 Greengrass Lambda 函数的生命周期配置。
-
arbitrary-function-id替换为函数的名称,例如stream-manager。 -
alias-arn替换为AliasArn您在创建TransferStreamLambda 函数别名时复制的。
注意
Timeout是函数定义版本所需的,但GGStreamManager不使用它。有关Timeout和其他组级别设置的更多信息,请参阅 使用组特定的配置控制 Greengrass Lambda 函数的执行。 -
-
从输出中复制
LatestVersionArn。您将使用此值向部署到核心的组版本添加函数定义版本。
步骤 4:创建记录器定义和版本
配置组的日志记录设置。在本教程中,您将配置 AWS IoT Greengrass 系统组件、用户定义的 Lambda 函数和连接器,以将日志写入核心设备的文件系统。您可以使用日志对可能遇到的任何问题进行故障排除。有关更多信息,请参阅 使用 进行监控 AWS IoT Greengrass logs。
-
创建一个包含初始版本的记录器定义。
-
从输出中复制记录器定义的
LatestVersionArn。您将使用此值向部署到核心的组版本添加记录器定义版本。
步骤 5:获取核心定义版本的 ARN
获取要添加到新组版本的核心定义版本的 ARN。要部署组版本,该组版本必须引用包含确切一个核心的核心定义版本。
-
获取目标 Greengrass 组和组版本的 ID。此过程假定这是最新的组和组版本。以下查询将返回最近创建的组。
aws greengrass list-groups --query "reverse(sort_by(Groups, &CreationTimestamp))[0]"或者,您也可以按名称查询。系统不要求组名称是唯一的,所以可能会返回多个组。
aws greengrass list-groups --query "Groups[?Name=='MyGroup']"注意
您也可以在 AWS IoT 控制台中找到这些值。组 ID 显示在组的设置页面上。组版本 ID 显示在组的部署选项卡上。
-
从输出中复制目标组的
Id。您将使用此值获取核心定义版本及部署组的时间。 -
从输出中复制
LatestVersion,这是添加到组的最后一个版本的 ID。您将使用此值获取核心定义版本。 -
获取核心定义版本的 ARN:
-
获取组版本。
-
group-id替换为你为Id该群组复制的。 -
group-version-id替换为你为LatestVersion该群组复制的。
aws greengrass get-group-version \ --group-idgroup-id\ --group-version-idgroup-version-id -
-
从输出中复制
CoreDefinitionVersionArn。您将使用此值向部署到核心的组版本添加核心定义版本。
-
步骤 6:创建组版本
现在,您已准备就绪,可以创建一个包含您要部署的实体的组版本。要实现此目的,需要创建一个引用每种组件类型的目标版本的组版本。在本教程中,您将包括核心定义版本、函数定义版本和记录器定义版本。
-
创建组版本。
-
group-id替换为你为Id该群组复制的。 -
core-definition-version-arn替换CoreDefinitionVersionArn为你为核心定义版本复制的。 -
function-definition-version-arn替换为你LatestVersionArn为新函数定义版本复制的函数。 -
logger-definition-version-arn替换为你为新LatestVersionArn的 Logger 定义版本复制的。
aws greengrass create-group-version \ --group-idgroup-id\ --core-definition-version-arncore-definition-version-arn\ --function-definition-version-arnfunction-definition-version-arn\ --logger-definition-version-arnlogger-definition-version-arn -
-
从输出中复制
Version。这是新组版本的 ID。
步骤 7:创建部署
将组部署到核心设备。
-
创建 部署。
group-id替换为你为Id该群组复制的。group-version-id替换为你Version为新群组版本复制的版本。
aws greengrass create-deployment \ --deployment-type NewDeployment \ --group-idgroup-id\ --group-version-idgroup-version-id -
从输出中复制
DeploymentId。 -
获取部署状态。
group-id替换为你为Id该群组复制的。deployment-id替换为您DeploymentId为部署复制的。
aws greengrass get-deployment-status \ --group-idgroup-id\ --deployment-iddeployment-id如果状态为
Success,则部署成功。有关问题排查帮助,请参阅问题排查 AWS IoT Greengrass。
步骤 8:测试应用程序
TransferStream Lambda 函数生成模拟的设备数据。它将数据写入流管理器导出到目标 Kinesis 数据流的流。
-
在 Amazon Kinesis 控制台的 Kinesi s 数据流下,选择。MyKinesisStream
注意
如果您在运行教程时没有目标 Kinesis 数据流, 请检查流管理器的日志文件 (
GGStreamManager)。如果它在错误消息中包含export stream MyKinesisStream doesn't exist,则测试成功。此错误意味着服务试图导出到流,但流不存在。 -
在MyKinesisStream页面上,选择监控。如果测试成功,您应在 Put Records (放置记录) 图表中看到数据。根据您的连接,显示数据可能需要一分钟时间。
重要
测试完成后,删除 Kinesis 数据流以避免产生更多费用。
运行以下命令以停止 Greengrass 守护程序。这样可以防止核心发送消息,直到您准备好继续测试。
cd /greengrass/ggc/core/ sudo ./greengrassd stop -
从核心中移除 TransferStreamLambda 函数。
按照步骤 6:创建组版本创建新的组版本,但删除
create-group-version命令中的--function-definition-version-arn选项。或者,创建一个不包含 TransferStreamLambda 函数的函数定义版本。注意
通过省略部署的组版本中的系统
GGStreamManagerLambda 函数,可以禁用核心上的流管理。-
按照步骤 7:创建部署以部署新的组版本。
要查看日志记录信息或解决流的问题,请检查日志中的 TransferStream 和 GGStreamManager 函数。您必须具有读取文件系统 AWS IoT Greengrass 日志的root权限。
TransferStream将日志条目写入greengrass-root/ggc/var/log/user/region/account-id/TransferStream.logGGStreamManager将日志条目写入greengrass-root/ggc/var/log/system/GGStreamManager.log
如果需要更多疑难解答信息,可以将 Lambda 日志记录级别设置为 DEBUG,然后创建并部署新的组版本。
另请参阅
-
AWS Identity and Access Management 命令参考@@ 中的 (IAM)AWS CLI 命令
-
AWS Lambda 命令参考中的AWS CLI 命令
-
AWS IoT Greengrass 命令参考中的AWS CLI 命令
