本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
REGEX_LOG_PARSE
REGEX_LOG_PARSE (<character-expression>,<regex-pattern>,<columns>)<regex-pattern> := <character-expression>[OBJECT] <columns> := <columnname> [ <datatype> ] {, <columnname> <datatype> }*
基于 java.util.regex.pattern
列基于正则表达式模式中定义的匹配组。每个组定义一列,并按从左到右的顺序处理这些组。不匹配会生成 NULL 值结果:如果正则表达式与作为第一个参数传递的字符串不匹配,则返回 NULL。
返回的列将是 COLUMN1 到 COLUMNn,其中 n 是正则表达式中的组数。这些列的类型将为 varchar(1024)。
示例
示例数据集
以下示例基于样本股票数据集,后者是 Amazon Kinesis Analytics 开发人员指南中的入门练习的一部分。要运行每个示例,您需要一个具有样本股票代码输入流的 Amazon Kinesis Analytics 应用程序。要了解如何创建 Analytics 应用程序和配置示例股票代码输入流,请参阅《Amazon Kinesis Analytics 开发人员指南》 中的入门练习。
具有以下架构的示例股票数据集。
(ticker_symbol VARCHAR(4), sector VARCHAR(16), change REAL, price REAL)
示例 1:从两个捕获组返回结果
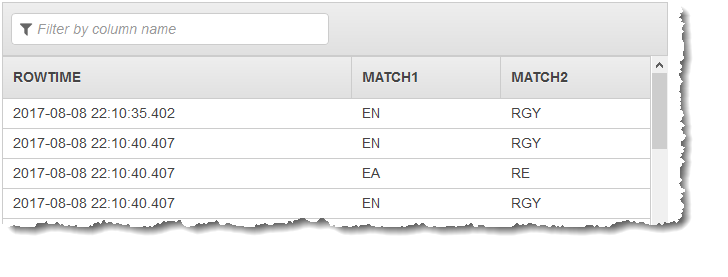
以下代码示例搜索 sector 字段的内容以查找字母 E 及其后面的字符,然后搜索字母 R,并返回该字母及其后面的所有字符:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (match1 VARCHAR(1024), match2 VARCHAR(1024)); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM T.REC.COLUMN1, T.REC.COLUMN2 FROM (SELECT STREAM SECTOR, REGEX_LOG_PARSE(SECTOR, '.*([E].).*([R].*)') AS REC FROM SOURCE_SQL_STREAM_001) AS T;
前面的代码示例生成类似于以下内容的结果:
示例 2:从两个捕获组返回一个流字段和结果
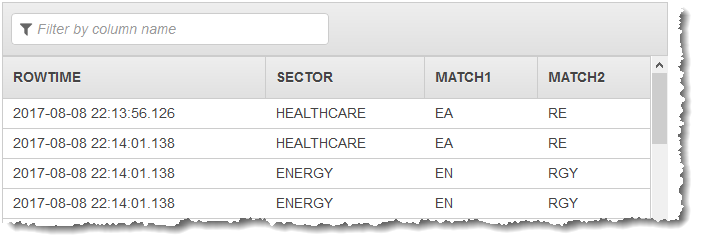
以下代码示例返回 sector 字段,搜索 sector 字段的内容以查找字母 E 并返回此字母及其后面的字符,然后搜索字母 R,并返回该字母及其后面的所有字符:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (sector VARCHAR(24), match1 VARCHAR(24), match2 VARCHAR(24)); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM T.SECTOR, T.REC.COLUMN1, T.REC.COLUMN2 FROM (SELECT STREAM SECTOR, REGEX_LOG_PARSE(SECTOR, '.*([E].).*([R].*)') AS REC FROM SOURCE_SQL_STREAM_001) AS T;
前面的代码示例生成类似于以下内容的结果:
有关更多信息,请参阅 FAST_REGEX_LOG_PARSER。
正则表达式快速参考
有关正则表达式的完整详细信息,请参阅 java.util.regex.pattern
|
[xyz] 查找 x、y 或 z 的单个字符 [^abc] 查找除了 x、y 或 z 之外的任何单个字符 [r-z] 查找 r-z 之间的任何单个字符 [r-zR-Z] 查找 r-z 或之间的任意单个字符 R-Z ^ 行首 $ 行尾 \A 字符串开始 \z 字符串结束 . 任何单个字符 \s 查找任何空格字符 \S 查找任何非空格字符 \d 查找任何数字 \D 查找任何非数字 |
\w 查找任何单词字符(字母、数字、下划线) \W 查找任何非单词字符 \b 查找任何单词边界 (...) 捕获括起来的所有内容 (x|y) 查找 x 或 y(也适用于诸如 \d 或 \s 之类的符号) x? 查找零个或一个 x(也适用于诸如 \d 或 \s 之类的符号) x* 查找零个或多个 x(也适用于诸如 \d 或 \s 之类的符号) x+ 查找一个或多个 x(也适用于诸如 \d 或 \s 之类的符号) x{3} 精确查找 3 个 x(也适用于诸如 \d 或 \s 之类的符号) x{3,} 查找 3 个或更多 x(也适用于诸如 \d 或 \s 之类的符号) x{3,6} 查找 3 到 6 个 x(也适用于诸如 \d 或 \s 之类的符号) |
