本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
STEP
STEP ( <time-unit> BY INTERVAL '<integer-literal>' <interval-literal> ) STEP ( <integer-expression> BY <integer-literal> )
STEP 将输入值(<time-unit> 或 <integer-expression>)向下舍入到 <integer-literal> 的最接近的倍数。
STEP 函数适用于日期时间数据类型或整数类型。STEP 是一个标量函数,用于执行类似于 FLOOR 的操作。但是,通过使用 STEP,您可以指定一个任意时间或整数间隔来向下舍入第一个参数。
如果任何输入参数为 null,则 STEP 返回 null。
具有整数参数的 STEP
当使用整数参数调用时,STEP 返回 <interval-literal> 参数的满足以下条件的最大整数倍数:即等于或小于 <integer-expression> 参数。例如,STEP(23 BY 5) 返回 20,因为 20 是 5 的满足以下条件的最大倍数:即小于 23。
STEP ( <integer-expression > BY <integer-literal> ) 等效于以下内容。
( <integer-expression> / <integer-literal> ) * <integer-literal>
示例
在以下示例中,返回值是 <integer-literal> 的满足以下条件的最大倍数:即等于或小于 <integer-expression>。
|
函数 |
结果 |
|---|---|
|
STEP(23 BY 5) |
20 |
|
STEP(30 BY 10) |
30 |
具有日期类型参数的 STEP
当通过日期、时间或时间戳参数调用时,STEP 将返回小于或等于输入的最大值,具体取决于 <time unit> 指定的精度。
STEP(<datetimeExpression> BY <intervalLiteral>) 等效于以下内容。
(<datetimeExpression> - timestamp '1970-01-01 00:00:00') / <intervalLiteral> ) * <intervalLiteral> + timestamp '1970-01-01 00:00:00'
<intervalLiteral> 可以是以下项之一:
YEAR
MONTH
DAY
HOUR
MINUTE
SECOND
示例
在以下示例中,返回值是以 <integer-literal> 指定的单位表示的 <intervalLiteral> 最新倍数,它等于或早于 <datetime-expression>。
|
函数 |
结果 |
|---|---|
|
STEP(CAST('2004-09-30 13:48:23' as TIMESTAMP) BY INTERVAL '10' SECOND) |
'2004-09-30 13:48:20' |
|
STEP(CAST('2004-09-30 13:48:23' as TIMESTAMP) BY INTERVAL '2' HOUR) |
'2004-09-30 12:00:00' |
|
STEP(CAST('2004-09-30 13:48:23' as TIMESTAMP) BY INTERVAL '5' MINUTE) |
'2004-09-30 13:45:00' |
|
STEP(CAST('2004-09-27 13:48:23' as TIMESTAMP) BY INTERVAL '5' DAY) |
'2004-09-25 00:00:00.0' |
|
STEP(CAST('2004-09-30 13:48:23' as TIMESTAMP) BY INTERVAL '1' YEAR) |
'2004-01-01 00:00:00.0' |
GROUP BY 子句中的 STEP(滚动窗口)
在此示例中,聚合查询具有一个 GROUP BY 子句,该子句将 STEP 应用于将流分组为有限行的 ROWTIME。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( ticker_symbol VARCHAR(4), sum_price DOUBLE); -- CREATE OR REPLACE PUMP to insert into output CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM ticker_symbol, SUM(price) AS sum_price FROM "SOURCE_SQL_STREAM_001" GROUP BY ticker_symbol, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND);
结果
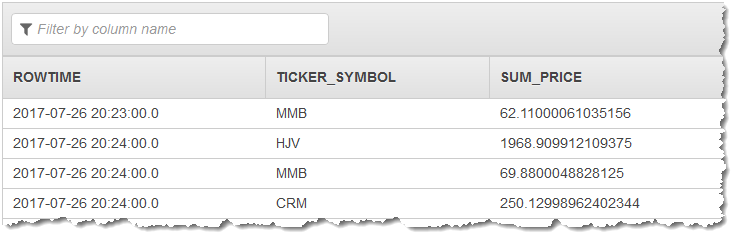
上一示例输出的流与以下内容类似。
OVER 子句中的 STEP(滑动窗口)
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( ingest_time TIMESTAMP, ticker_symbol VARCHAR(4), ticker_symbol_count integer); --Create pump data into output CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" -- select the ingest time used in the GROUP BY clause SELECT STREAM STEP(source_sql_stream_001.approximate_arrival_time BY INTERVAL '10' SECOND) as ingest_time, ticker_symbol, count(*) over w1 as ticker_symbol_count FROM source_sql_stream_001 WINDOW w1 AS ( PARTITION BY ticker_symbol, -- aggregate records based upon ingest time STEP(source_sql_stream_001.approximate_arrival_time BY INTERVAL '10' SECOND) -- use process time as a trigger, which can be different time window as the aggregate RANGE INTERVAL '10' SECOND PRECEDING);
结果
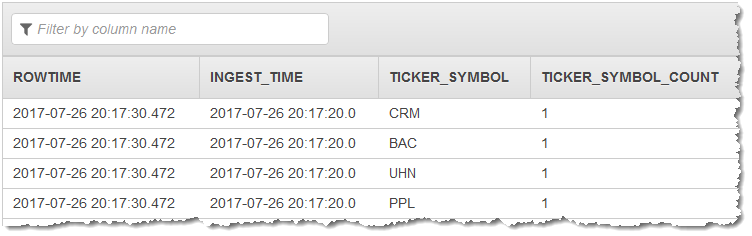
上一示例输出的流与以下内容类似。
注意
STEP ( <datetime expression> BY <literal expression> ) 是 Amazon Kinesis Data Analytics 扩展。
您可以使用 STEP 通过滚动窗口聚合结果。有关滚动窗口的详细信息,请参阅滚动窗口概念。
