我们不再更新 Amazon Machine Learning 服务,也不再接受新用户使用该服务。本文档可供现有用户使用,但我们不会再对其进行更新。有关更多信息,请参阅什么是 Amazon Machine Learning。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
二进制模型洞察
解释预测
许多二进制分类算法的实际输出是预测分数。该分数指示给定观察属于正类的系统确定性(实际目标值为 1)。Amazon ML 中的二进制分类模型输出一个介于 0 和 1 之间的分数。作为此分数的使用者,为了决定观察应分类为 1 还是 0,需要选取分类阈值或者选取截断值,并与分数进行对比,以此来解释分数。当目标等于 1 时,将预测其分数高于截断值的任何观察;当目标等于 0 时,将预测其分数低于截断值的观察。
在 Amazon ML 中,默认的分数截断值为 0.5。您可以选择更新此截断值以满足您的业务需求。您可以在控制台中使用可视化内容来了解截断值的选择将对您的应用程序造成怎样的影响。
衡量 ML 模型准确度
Amazon ML 为二进制分类模型提供行业标准的准确度指标,称为(受试者操作特征)曲线下面积 (AUC)。AUC 衡量模型为正面示例预测出相比负面示例更高分数的能力。由于它独立于分数截断值,因此您可以从 AUC 指标感受到模型的预测准确度,无需选取阈值。
AUC 指标返回从 0 到 1 的数值。接近 1 的 AUC 值指示高度准确的 ML 模型。接近 0.5 的值指示 ML 模型比随便猜测好不了多少。值接近 0 的情况很少见,这通常表示数据有问题。基本上,接近 0 的 AUC 表示 ML 模型已学习了正确的模式,但使用它们来预测会得到与实际颠倒的结果(将“0”预测为“1”或者将“1”预测为“0”)。有关 AUC 的更多信息,请转到 Wikipedia 上的受试者操作特征
二进制模型的基线 AUC 指标为 0.5。这是随机预测 1 或 0 答案的假想 ML 模型的值。您的二进制 ML 模型要想有价值,表现得应该比此值要好才行。
使用性能可视化
要探究 ML 模型的准确度,您可以查看 Amazon ML 控制台的评估页面上的图表。此页显示两个直方图:a) 实际正例分数的直方图(目标为 1)以及 b) 实际负例分数的直方图(目标为 0)。
具有良好预测准确度的 ML 模型对于实际的 1 将预测较高的分数,对实际的 0 将预测较低的分数。完美的模型将在 x 轴两端具有两个直方图,实际正例全部得到高分,实际负例全部得到低分。但是,ML 模型会出错,一般的图表会显示两个直方图在某些分数重叠。性能极差的模型会无法区分正类和负类,这两个类的直方图重叠最多。
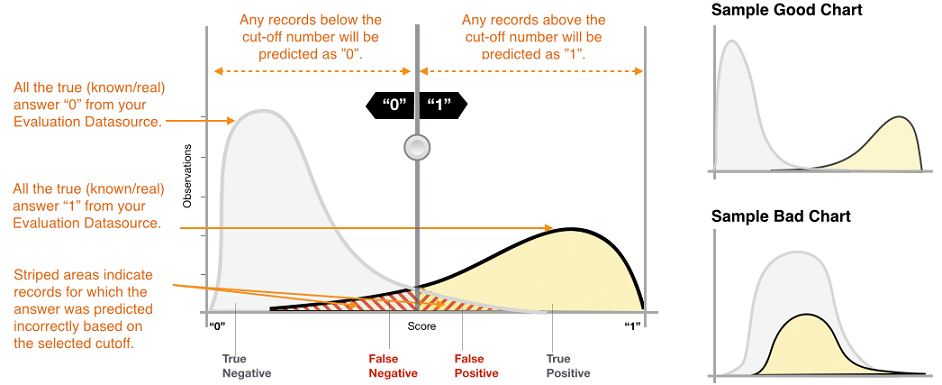
利用可视化内容可以确定属于两种正确预测类型的预测数以及属于两种不正确预测类型的预测数。
正确预测
-
真正 (TP):Amazon ML 预测的值为 1,真正的值为 1。
-
真负 (TN):Amazon ML 预测的值为 0,真正的值为 0。
错误预测
-
假正 (FP):Amazon ML 预测的值为 1,但真正的值为 0。
-
假负 (FN):Amazon ML 预测的值为 0,但真正的值为 1。
注意
TP、TN、FP 和 FN 的数量取决于所选分数阈值,对这些类型中的任意一种进行优化都意味着需要对其他类型作出让步。较高的数量 TPs 通常会导致较高的数量 FPs 和较低的数量 TNs。
调整分数截断值
ML 模型的工作方式是生成数字预测分数,然后应用截断值将这些分数转换为二进制 0/1 标签。通过更改分数截断值,您可以在模型出错时调整其行为。在 Amazon ML 控制台的评估页面上,您可以查看不同分数截断值的影响,并可以保存希望用于模型的分数截断值。
在您调整分数截断值阈值时,请观察两种错误类型之间的平衡。将截断值向左侧移动将会获得更多“真正”数,但同时“假正”数也会增加。将其向右侧移动将获得较少的“假正”错误数,但同时也会失去一些“真正”数。对于您的预测应用程序,您需要通过选择合适的截断值分数来确定更能容忍哪种类型的错误。
查看高级指标
Amazon ML 提供以下额外指标来测量 ML 模型的预测准确度:准确度、精度、召回率和假正率。
准确度
准确度 (ACC) 衡量正确预测的比率。范围为 0 至 1。值越大说明预测准确度越高:
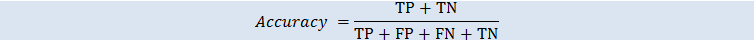
精度
精度衡量实际正例与预测为正例的比率。范围为 0 至 1。值越大说明预测准确度越高:
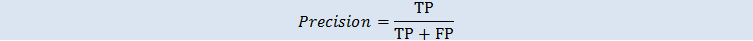
召回率
召回率衡量预测为正例的实际正例的比率。范围为 0 至 1。值越大说明预测准确度越高:
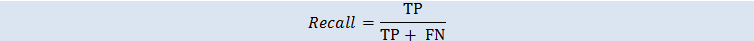
假正率
假正率 (FPR) 衡量错误警报率或预测为正例的实际负例的比率。范围为 0 至 1。值越小说明预测准确度越高:
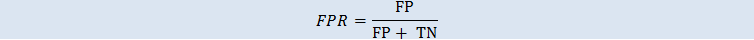
根据您的业务问题,您可能会对在这些指标的特定部分中表现良好的模型更感兴趣。例如,两个业务应用程序可能对其 ML 模型有着迥然不同的要求:
-
一个应用程序可能需要严格保证正面预测实际为正面(高精度),并能够承受将一些正面示例错误分类为负面示例(中等召回率)。
-
另一个应用程序可能需要尽可能多地正确预测正面示例(高召回率),并可以接受将一些负面示例错误分类为正面示例(中等精度)。
Amazon ML 允许您选择与之前任意高级指标的特定值相对应的分数截断值。它还显示由于优化任意一项指标而导致作出的让步。例如,如果您选择一个与高精度对应的截断值,则通常不得不接受较低的召回率。
注意
您必须为其保存分数截断值,这样才能用于分类 ML 模型未来的任何预测。
