我们不再更新 Amazon Machine Learning 服务,也不再接受新用户使用该服务。本文档可供现有用户使用,但我们不会再对其进行更新。有关更多信息,请参阅什么是 Amazon Machine Learning。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数据洞察
Amazon ML 计算输入数据的描述性统计信息,您可以使用这些信息来了解自己的数据。
描述性统计信息
Amazon ML 针对不同属性类型计算以下描述性统计信息:
数值:
-
分布直方图
-
无效值的数量
-
最小值、中值、平均值和最大值
二进制和分类:
-
计数(每个类别的不同值)
-
值分布直方图
-
最常用值
-
唯一值计数
-
true 值的百分比(仅限二进制)
-
最突出单词
-
最常用单词
文本:
-
属性的名称
-
与目标的相关性(如果已设置目标)
-
总单词数
-
唯一单词数
-
一行中单词数的范围
-
单词长度范围
-
最突出单词
在 Amazon ML 控制台上访问数据洞察
在 Amazon ML 控制台上,您可以选择任意数据源的名称或 ID 以查看其数据洞察页面。此页面提供一些指标和可视化内容,让您了解与数据源关联的输入数据,包括以下信息:
-
数据摘要
-
目标分布
-
缺失值
-
无效值
-
按数据类型列出的变量摘要统计信息
-
按数据类型列出的变量分布
以下各部分更详细地描述了各指标和可视化内容。
数据摘要
数据源的数据摘要报告显示摘要信息,包括数据源 ID、名称、其完成位置、当前状态、目标属性、输入数据信息(S3 存储桶位置、数据格式、处理的记录数和处理期间遇到的错误记录数)以及按数据类型列出的变量数。
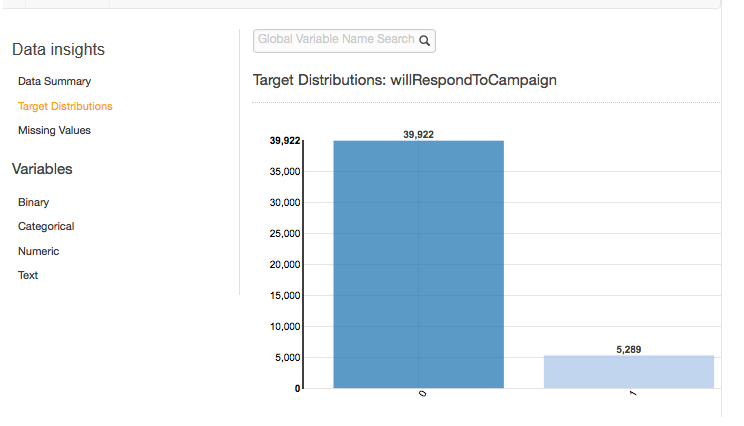
目标分布
目标分布报告显示数据源的目标属性的分布。在以下示例中,有 39,922 个观测值的RespondToCampaign 目标属性等于 0。这是未响应电子邮件营销活动的客户数。有 5,289 个观测值其中 will RespondToCampaign 等于 1。这是响应电子邮件营销活动的客户数。
缺失值
缺失值报告列出输入数据中缺失值的属性。只有具有数字数据类型的属性才能具有缺失值。由于缺失值会影响 ML 模型的训练质量,我们建议尽可能提供缺失值。
在 ML 模型训练期间,如果目标属性缺失,Amazon ML 会拒绝对应的记录。如果记录中存在目标属性,但其他数字属性的值缺失,则 Amazon ML 会忽略缺失值。在这种情况下,Amazon ML 创建替代属性并将其设置为 1,指示此属性缺失。这使得 Amazon ML 可以根据缺失值的出现来了解模式。
无效值
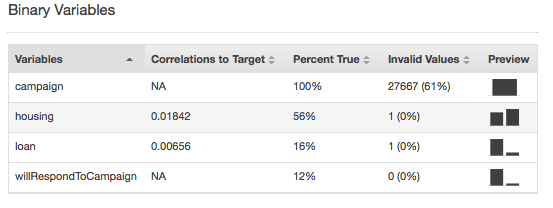
只有数字和二进制数据类型会出现无效的值。您可以通过在数据类型报告中查看变量的摘要统计信息来查找无效值。在以下示例中,持续时间数字属性中有一个无效值,二进制数据类型中有两个无效值(一个在 housing 属性中,一个在 loan 属性中)。

Variable-Target 相关性
创建数据源之后,Amazon ML 可以评估数据源,并确定变量与目标之间的相关性或影响。例如,产品的价格可能会对是否为最佳卖家产生巨大影响,而产品尺寸带来的预测能力则可能很小。
通常的最佳实践是在训练数据中包括尽可能多的变量。但是,引入预测能力很小的多个变量会带来干扰,从而会对 ML 模型的质量和准确性产生负面影响。
在训练模型时,您可以移除影响较小的变量,从而提升模型的预测性能。您可以在配方中定义哪些变量可供机器学习过程使用,这是 Amazon ML 的转换机制。要了解有关配方的更多信息,请参阅机器学习的数据转换。
按数据类型列出的属性摘要统计信息
在数据洞察报告中,您可以按以下数据类型查看属性摘要统计信息:
-
二元
-
分类
-
数值
-
文本
二进制数据类型的摘要统计信息显示所有二进制属性。Correlations to target 列显示在目标列与属性列之间共享的信息。Percent true 列显示值为 1 的观察的百分比。Invalid values 列显示无效值的数量以及各属性的无效值的百分比。Preview 列提供各属性的分布图的链接。
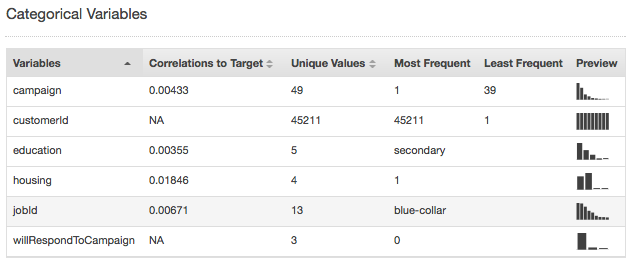
分类数据类型的摘要统计信息显示所有分类属性以及唯一值的数量、最常用的值以及最不常用的值。Preview 列提供各属性的分布图的链接。
数字数据类型的摘要统计信息显示所有数字属性以及缺失值的数量、无效值、值范围、平均值和中值。Preview 列提供各属性的分布图的链接。
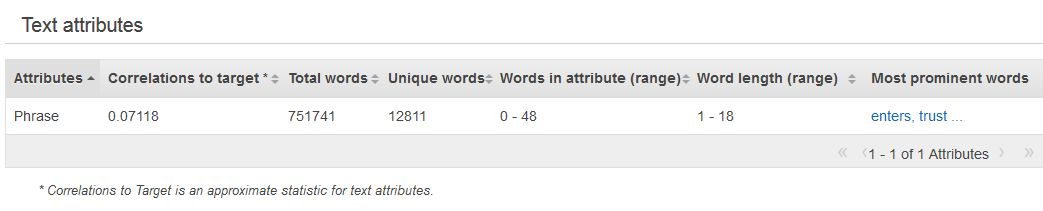
文本数据类型的摘要统计信息显示所有文本属性、该属性中的单词总数、该属性中的唯一单词数、属性中的单词数范围、单词长度的范围以及最突出单词。Preview 列提供各属性的分布图的链接。
下一个示例显示了名为“review”的文本变量的文本数据类型统计信息,它有四条记录。
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
此示例的各列将显示以下信息。
-
Attributes 列显示变量的名称。在本示例中,此列将显示“review”。
-
只有指定了目标,才存在 Correlations to target 列。相关性用于衡量此属性提供的有关目标的信息量。相关性越高,此属性揭示的有关目标的信息也越多。相关性按照文本属性与目标的简化表示形式之间的交互信息来衡量。
-
Total words 列显示通过令牌化各个记录生成的单词(以空格分隔单词)数量。在本示例中,此列将显示“12”。
-
Unique words 列显示属性的唯一单词数。在本示例中,此列将显示“10”。
-
Words in attribute (range) 列显示属性的单行中的单词数。在本示例中,此列将显示“0-6”。
-
Word length (range) 列显示单词中字符数的范围。在本示例中,此列将显示“2-11”。
-
Most prominent words 列显示在属性中显示的单词排名列表。如果存在目标属性,则单词按照与目标的相关性排名,也就是相关性最高的单词列在最前。如果数据中没有目标,则单词按照其熵排名。
了解分类和二进制属性的分布
您可单击与某个分类属性或二进制属性关联的 Preview 链接来查看属性的分布,以及输入文件中属性的各分类值的示例数据。
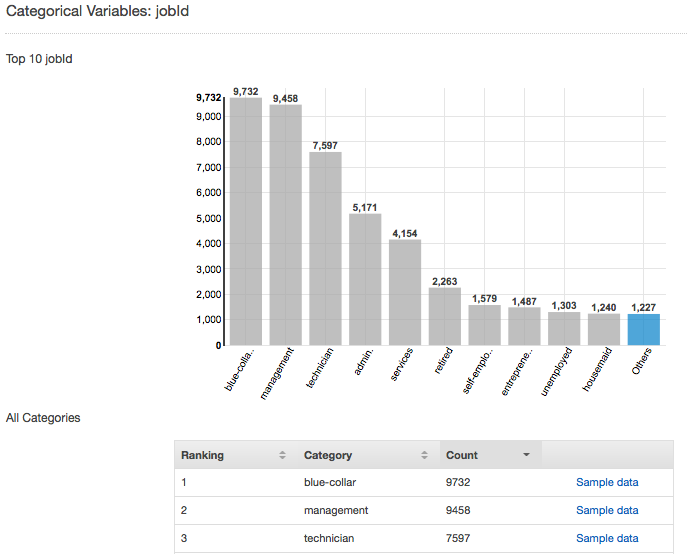
例如,以下屏幕截图显示分类属性 jobId 的分布。分布显示了前 10 个分类值,所有其他值归为“other”组。它对前 10 的各个分类值与输入文件中包含相应值的观察数进行排名,并提供查看输入数据文件中示例观察的链接。
了解数字属性的分布
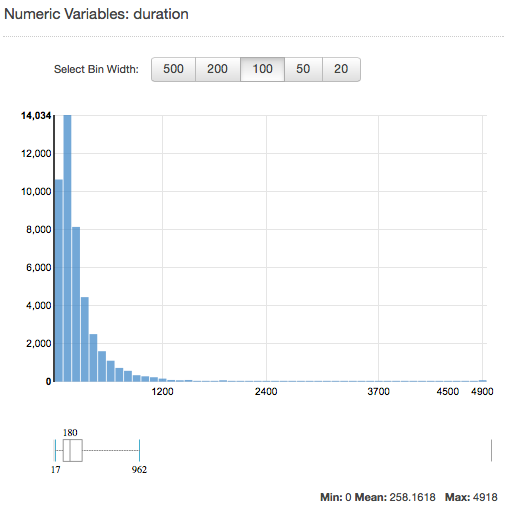
要查看数字属性的分布,请单击属性的 Preview 链接。查看数字属性的分布时,您可以选择 500、200、100、50 或 20 的箱大小。箱大小越大,将显示的条形图的数量就越少。此外,较大的箱大小会导致较粗糙的分布分辨率。与之相对,将存储桶大小设置为 20 会提升所示分布的分辨率。
图中还将显示最小值、平均值和最大值,如以下屏幕截图中所示。
了解文本属性的分布
要查看文本属性的分布,请单击属性的 Preview 链接。查看文本属性的分布时,您会看到以下信息。
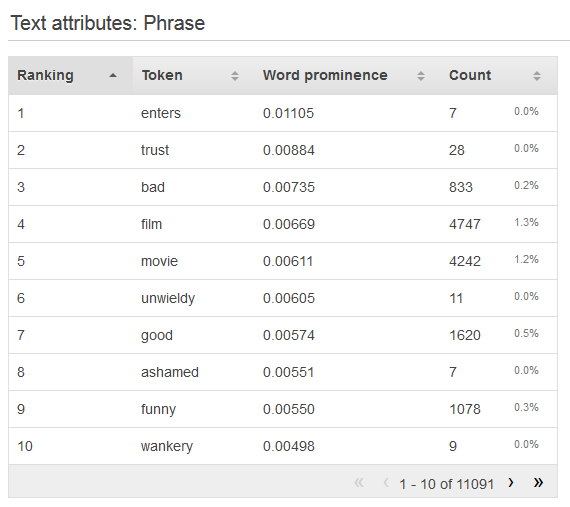
- 排名
-
文本令牌按照所传达的信息量排名,从最具信息性到最不具信息性。
- 令牌
-
令牌显示统计信息行所相关的输入文本中的单词。
- 单词突出部分
-
如果存在目标属性,单词按照与目标的相关性排名,这样相关性最高的单词列在最前。如果数据中不存在目标,则单词按照其熵(即它们可以传达的信息量)排名。
- 计数
-
计数显示其中出现了令牌的输入记录的数量。
- 计数百分比
-
计数百分比显示其中出现了令牌的输入数据行的百分比。
