我们不再更新 Amazon Machine Learning 服务,也不再接受新用户使用该服务。本文档可供现有用户使用,但我们不会再对其进行更新。有关更多信息,请参阅什么是 Amazon Machine Learning。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
多类别模型洞察
解释预测
多类别分类算法的实际输出是一组预测分数。这些分数指示模型的给定观察属于各个类别的确定性。与二进制分类问题不同,您不需要选择分数截断值以进行预测。预测的答案是预测分数最高的类别(例如,label)。
衡量 ML 模型准确度
多类别中使用的典型指标与对所有类别进行平均化之后二进制分类案例中使用的指标相同。在 Amazon ML 中,宏平均 F1 分数用于评估多类别指标的预测准确性。
宏平均 F1 分数
F1 分数是考虑二进制指标精度和重新调用的二进制分类指标。它是精度和重新调用之间的调和平均数。范围为 0 至 1。值越大说明预测准确度越高:
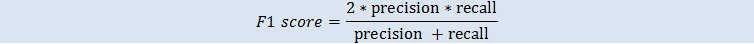
宏平均 F1 分数是多类别案例中所有类别的 F1 分数的未加权平均数。它不会考虑类别在评估数据集中出现的频率。较大的值表示更好的预测准确度。以下示例显示了评估数据源中的 K 类别:
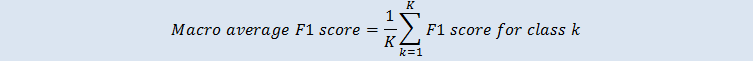
基准宏平均 F1 分数
Amazon ML 提供了多类别模型的基准指标。它是假想多类别模型的宏平均 F1 分数,该模型始终将最常见的类别预测为答案。例如,如果您在预测电影流派时,您训练数据中最常见的流派是爱情片,则基准模型会始终将流派预测为爱情片。您可以根据此基准来比较您的 ML 模型,以验证您的 ML 模型是否优于预测此常量答案的 ML 模型。
使用性能可视化
Amazon ML 提供混淆矩阵来直观地呈现多类别分类预测模型的准确性。混淆矩阵通过比较观察的预测类别及其真正的类别,在表中列出了各类别正确和错误预测的数量或百分比。
例如,如果您尝试将电影归入某个流派,预测模型可能预测其流派(类别)是爱情片。但其真正的流派可能是惊悚片。当您评估多类别分类 ML 模型的准确度时,Amazon ML 会识别错误分类并在混淆矩阵中显示结果,如下图所示。
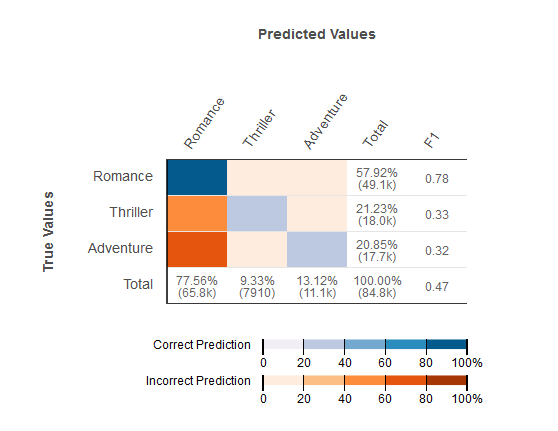
系统会在混淆矩阵中显示以下信息:
-
每个类别的正确和错误预测的数量:混淆矩阵中的每一行都对应一个真正类别的指标。例如,第一行显示了实际流派为爱情片的电影,多类别 ML 模型正确预测了 80% 以上的案例。它将不到 20% 的案例的流派错误地预测为惊悚片,并将不到 20% 的案例的流派错误地预测为冒险片。
-
类域 F1 分数:最后一个列显示每个类别的 F1 分数。
-
评估数据中的真正类别频率:第二列至最后一列显示,在评估数据集中,评估数据中有 57.92% 的观察为爱情片,21.23% 为惊悚片,20.85% 为冒险片。
-
评估数据的预测类别频率:最后一行显示预测中每个类的频率。77.56% 的观察被预测为爱情片,9.33% 被预测为惊悚片,13.12% 被预测为冒险片。
Amazon ML 控制台提供了可见显示,最多可在混淆矩阵中包含 10 个类别,这些类别将按照评估数据中最常见类别到最不常见类别的顺序列出。如果您的评估数据包含 10 个以上的类别,将会在混淆矩阵中看到前 9 个最常见的类别,所有其他类别都折叠为名为“others”的类别。借助 Amazon ML,您还能通过多类别可视化页面上的链接下载完整混淆矩阵。
