本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过使用自定义数据标识符,您可以定义用于检测 Amazon Simple Storage Service (Amazon S3) 对象中的敏感数据的自定义标准。您可以补充 Amazon Macie 提供的托管数据标识符,并检测反映组织的特定场景、知识产权或专有数据的敏感数据。
每个自定义数据标识符都指定了检测标准,以及标识符生成的调查发现的严重性设置(可选)。检测标准指定了一个正则表达式,用于定义要与 S3 对象匹配的文本模式。该标准还可以指定字符序列和邻近规则,以优化结果。严重性设置指定了要分配给调查发现的严重性。严重性可以根据符合标识符检测标准的文本的出现次数来确定。
检测标准
在创建自定义数据标识符时,指定一个正则表达式 (regex) 来定义要匹配的文本模式。您还可以指定字符序列,例如字词和短语,以及一个邻近规则来优化结果。字符序列可以是:关键字,即必须出现在与正则表达式匹配的文本附近的单词或短语;或忽略单词,即从结果中排除的单词或短语。
对于 regex,Amazon Macie 支持 Perl 兼容正则表达式 (PCRE)
-
反向引用
-
捕获组
-
条件模式
-
嵌入式代码
-
全局模式标志,如
/i、/m和/x -
递归模式
-
正向和负向后视和前视零宽度断言,如
?=、?!、?<=和?<!
正则表达式可以包含多达 512 个字符。
要为自定义数据标识符创建有效的正则表达式模式,请注意以下提示和建议:
-
仅当您希望模式出现在文件的开头或结尾而不是行的开头或结尾时,才使用锚点(
^或$)。 -
出于性能考虑,Macie 限制了有界重复组的大小。例如,
\d{100,1000}无法在 Macie 中进行编译。为了近似于此功能,您可以使用开放式重复,如\d{100,}。 -
要使模式的某些部分不区分大小写,可以使用
(?i)构造代替/i标志。 -
无需手动优化前缀或者替代项。例如,将
/hello|hi|hey/更改为/h(?:ello|i|ey)/不会提高性能。 -
出于性能考虑,Macie 限制了重复通配符的数量。例如,
a*b*a*无法在 Macie 中进行编译。
为了防范格式错误或长时间运行的表达式,Macie 会在您创建自定义数据标识符时自动根据示例文本样本集测试正则表达式模式。如果正则表达式有问题,Macie 会返回一个描述问题的错误。
除了 regex,您还可以选择指定字符序列和接近规则来优化结果。
- 关键字
-
这些是特定的字符序列,必须靠近匹配正则表达式模式的文本。接近要求会随 S3 对象的存储格式或文件类型而变化:
-
结构化列式数据 — 如果文本与正则表达式模式相匹配,并且关键字位于存储文本的字段或列的名称中,或者文本前面有相同字段或单元格值中某个关键字的最大匹配距离且在最大匹配距离之内,Macie 就会包含结果。这种情况包括 Microsoft Excel 工作簿、CSV 文件和 TSV 文件。
-
基于记录的结构化数据 — 如果文本与正则表达式模式匹配且文本在关键字的最大匹配距离之内,Macie 会包含结果。关键字可以是存储文本的字段或数组路径中某个元素的名称,也可以位于存储文本的字段或数组中的相同值之前并成为该值的一部分。这种情况包括 Apache Avro 对象容器、Apache Parquet 文件、JSON 文件和 JSON Lines 文件。
-
非结构化数据:如果文本匹配 regex 模式并且文本前面有关键字的最大匹配距离并在其范围内,则 Macie 将包括结果。这种情况包括 Adobe 便携式文档格式文件、Microsoft Word 文档、电子邮件消息和非二进制文本文件(CSV、JSON、JSON Lines 和 TSV 文件除外)。这包括这些类型的文件中的任何结构化数据,例如表。
您最多可以指定 50 个关键字。每个关键字可以包含 3–90 个 UTF-8 字符。关键字不区分大小写。
-
- 最大匹配距离
-
这是基于字符的关键字邻近规则。Macie 使用此设置来确定关键字是否位于与正则表达式模式匹配的文本之前。该设置定义了完整关键字的结尾与匹配正则表达式模式的文本结尾之间可以存在的最大字符数。如果文本包含以下内容,Macie 会给出结果:
-
与正则表达式匹配,
-
在至少完整输入一个关键字后出现,并且
-
在关键字的指定范围内出现。
否则,Macie 会从结果中排除文本。
您可以指定 1–300 个字符的距离。默认距离为 50 个字符。为了获得最佳结果,此距离应大于正则表达式设计用于检测的最小文本字符数。如果只有部分文本在关键字的最大匹配距离之内,则 Macie 不会将其包含在结果中。
-
- 忽略字词
-
这些是要从结果中排除的特定字符序列。如果文本与正则表达式模式匹配但包含忽略词,则 Macie 不会将其包含在结果中。
您最多可以指定 10 个忽略字词。每个忽略字词可以包含 4–90 个 UTF-8 字符。忽略字词区分大小写。
注意
在创建自定义数据标识符之前,我们强烈建议您使用样本数据测试和完善其检测标准。由于敏感数据发现任务使用自定义数据标识符,因此您无法在创建自定义数据标识符后对其进行更改。这有助于确保您拥有敏感数据调查发现和发现结果的不可变历史记录,以便您执行数据隐私和保护的审计或调查。
您可以通过使用 Amazon Macie 控制台或 Amazon Macie API 来测试检测标准。要使用控制台测试标准,请在创建自定义数据标识符时使用评估部分中的选项。要以编程方式测试标准,请使用亚马逊 Macie API 的TestCustomDataIdentifier操作。如果您使用的是 AWS Command Line Interface,请运行test-custom-data-identifier命令来测试标准。
要演示关键字如何帮助您查找敏感数据并避免误报,请观看以下视频:
调查发现的严重性设置
在创建自定义数据标识符时,您还可以为标识符生成的敏感数据调查发现指定自定义严重性设置。默认情况下,Amazon Macie 将自定义数据标识符生成的所有调查发现都定为中等严重性。如果一个 S3 对象至少包含一次符合检测标准的文本,则 Macie 会自动将调查发现定为中等严重性。
使用自定义严重性设置,您可以根据与检测标准匹配的文本的出现次数指定要分配的严重性。您可以为多达三个严重性级别定义出现次数阈值:低(最不严重)、中和高(最严重)。出现次数阈值是 S3 对象中必须存在的最小匹配数,以生成具有指定严重性的调查发现。如果指定多个阈值,则这些阈值必须按严重性从低到高升序排列。
例如,下图显示了严重性设置,该标识符指定了三个出现次数阈值,Macie 支持的每个严重性级别对应一个阈值。
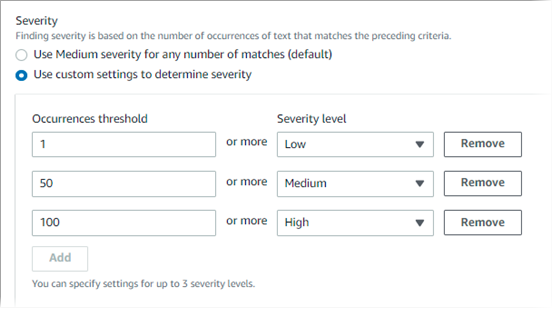
下表显示了自定义数据标识符生成的调查发现的严重性。
| 出现次数阈值 | 严重性级别 | 结果 |
|---|---|---|
| 1 | 低 | 如果 S3 对象包含 1-49 次符合检测标准的文本,则产生的调查发现的严重性为低。 |
| 50 | 中 | 如果 S3 对象包含 50-99 次符合检测标准的文本,则产生的调查发现的严重性为中。 |
| 100 | 高 | 如果 S3 对象包含 100 次或更多次符合检测标准的文本,则产生的调查发现的严重性为高。 |
您也可以使用严重性设置来指定是否要创建调查发现。如果 S3 对象包含的出现次数少于最低出现次数阈值,则 Macie 不会创建调查发现。
