本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Neptune ML 中的 Gremlin 推理查询
如Neptune ML 功能中所述,Neptune ML 支持可以执行以下类型的推理任务的训练模型:
节点分类 - 预测顶点属性的分类特征。
节点回归 - 预测顶点的数值属性。
边缘分类 - 预测边缘属性的分类特征。
边缘回归 - 预测边缘的数值属性。
链接预测 - 根据源节点和传出边缘预测目标节点,或者根据目标节点和传入边缘预测源节点。
我们可以通过使用 R GroupLens es
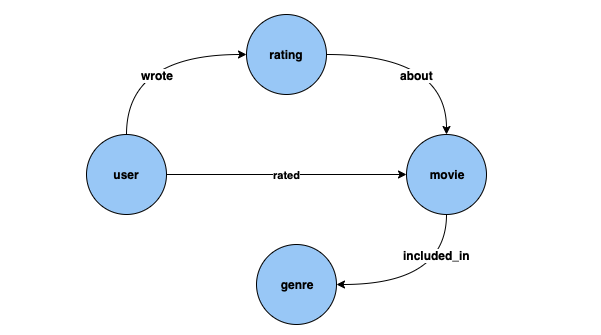
节点分类:在上面的数据集中,Genre 是一种通过 included_in 边缘与顶点类型 Movie 相连的顶点类型。但是,如果我们调整数据集以使 Genre 成为顶点类型 Movie 的分类Genre 的问题。
节点回归:如果我们考虑具有如 timestamp 和 score 等属性的顶点类型 Rating,则可以使用节点回归模型来解决对于 Rating 推理数值 Score 的问题。
边缘分类:同样,对于 Rated 边缘,如果我们有一个属性 Scale 可以具有值(Love、Like、Dislike、Neutral、Hate)之一,就可以使用边缘分类模型来解决对于新电影/评分的 Rated 边缘推理 Scale 的问题。
边缘回归:同样,对于同一 Rated 边缘,如果我们有一个属性 Score 可以保存评分的数值,那么可以从边缘回归模型中推理出来。
链接预测:诸如查找最有可能对给定电影进行评分的前十名用户,或者找到给定用户最有可能评分的前十部电影之类的问题,属于链接预测的范围。
注意
对于 Neptune ML 用例,我们有一套非常丰富的笔记本,旨在让您亲身了解每个用例。当你使用 Neptune ML AWS CloudFormation 模板创建 Neptune 机器学习集群时,你可以将这些笔记本与 Neptune 集群一起创建。这些笔记本也可以在 github
主题
