本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
从 Amazon S3 表中加载流数据
您可以使用 Lambda 将数据从 Amazon S3 发送到您的 OpenSearch 服务域。到达 S3 存储桶的新数据将触发事件通知到 Lambda,这将运行自定义代码以执行编制索引。
这种流式传输数据的方式极其灵活。可以为对象元数据编制索引
先决条件
继续操作之前,必须具有以下资源。
| 先决条件 | 说明 |
|---|---|
| 亚马逊 S3 存储桶 | 有关更多信息,请参阅 Amazon Simple Storage Service 用户指南中的创建您的第一个 S3 存储桶。存储桶必须与您的 OpenSearch 服务域位于同一区域。 |
| OpenSearch 服务域 | Lambda 函数处理数据之后数据的目的地。有关更多信息,请参阅 创建 OpenSearch 服务域。 |
创建 Lambda 部署程序包
部署程序包为 ZIP 或 JAR 文件,其中包含代码及其依赖项。此节包括 Python 示例代码。对于其他编程语言,请参阅 AWS Lambda 开发人员指南中的 Lambda 部署程序包。
-
创建目录。在此示例中,我们使用名称
s3-to-opensearch。 -
在名为
sample.py的目录中创建一个文件:import boto3 import re import requests from requests_aws4auth import AWS4Auth region = '' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = '' # the OpenSearch Service domain, e.g. https://search-mydomain.us-west-1.es.amazonaws.com index = 'lambda-s3-index' datatype = '_doc' url = host + '/' + index + '/' + datatype headers = { "Content-Type": "application/json" } s3 = boto3.client('s3') # Regular expressions used to parse some simple log lines ip_pattern = re.compile('(\d+\.\d+\.\d+\.\d+)') time_pattern = re.compile('\[(\d+\/\w\w\w\/\d\d\d\d:\d\d:\d\d:\d\d\s-\d\d\d\d)\]') message_pattern = re.compile('\"(.+)\"') # Lambda execution starts here def handler(event, context): for record in event['Records']: # Get the bucket name and key for the new file bucket = record['s3']['bucket']['name'] key = record['s3']['object']['key'] # Get, read, and split the file into lines obj = s3.get_object(Bucket=bucket, Key=key) body = obj['Body'].read() lines = body.splitlines() # Match the regular expressions to each line and index the JSON for line in lines: line = line.decode("utf-8") ip = ip_pattern.search(line).group(1) timestamp = time_pattern.search(line).group(1) message = message_pattern.search(line).group(1) document = { "ip": ip, "timestamp": timestamp, "message": message } r = requests.post(url, auth=awsauth, json=document, headers=headers)编辑
region和host的变量。 -
安装 pip
(如果您尚未安装,则将依赖项安装到 package目录:cd s3-to-opensearch pip install --target ./package requests pip install --target ./package requests_aws4auth所有 Lambda 执行环境都已安装 Boto3
,因此无需将其包含在部署程序包中。 -
打包应用程序代码和依赖项:
cd package zip -r ../lambda.zip . cd .. zip -g lambda.zip sample.py
创建 Lambda 函数
创建部署程序包之后,可以创建 Lambda 函数。创建函数时,选择名称、运行时 (例如,Python 3.8) 和 IAM 角色。IAM 角色定义对函数的权限。有关详细说明,请参阅 AWS Lambda 开发人员指南中的通过控制台创建 Lambda 函数。
此示例假定使用的是控制台。选择 Python 3.9 以及具有 S3 读取权限和 OpenSearch 服务写入权限的角色,如以下屏幕截图所示:
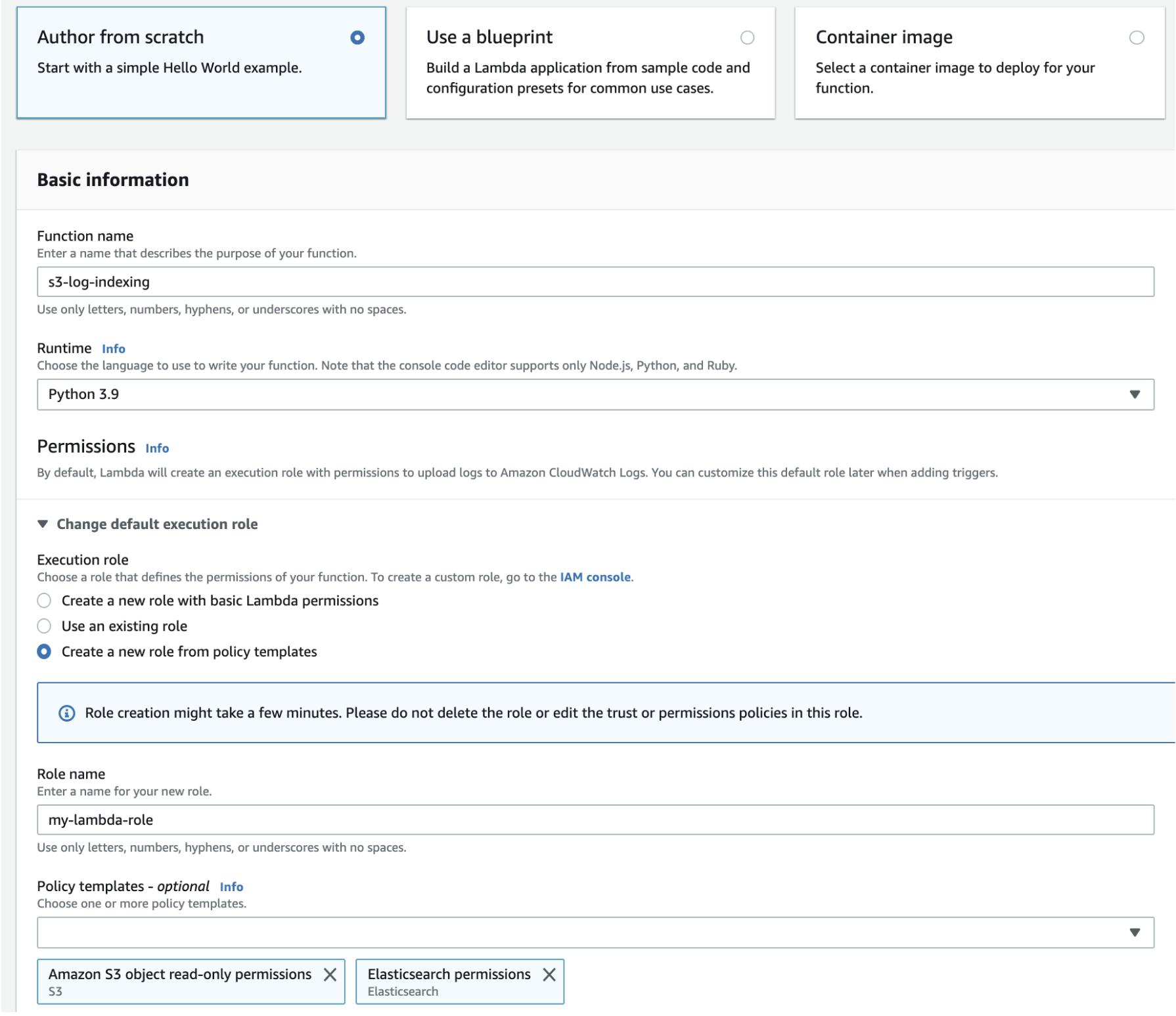
在创建此函数后,必须添加一个触发器。在此示例中,我们希望代码在日志文件到达 S3 存储桶中时执行:
-
选择添加触发器并选择 S3。
-
选择存储桶。
-
对于 Event type (事件类型),选择 PUT。
-
对于 Prefix (前缀),键入
logs/。 -
对于后缀,键入
.log。 -
确认递归调用警告,然后选择添加。
最后,可以上传部署程序包:
-
选择上载自和 .zip 文件,然后按照提示上传部署程序包。
-
上载完成后,编辑 Runtime 设置并更改处理程序为
sample.handler。此设置告知 Lambda 在触发之后应执行的文件 (sample.py) 和方法 (handler)。
此时,您拥有一整套资源:一个用于存储日志文件的存储桶、一个在向存储桶中添加日志文件时运行的函数、执行解析和索引的代码,以及一个用于搜索和可视化的 OpenSearch 服务域。
测试 Lambda 函数
在创建此函数之后,可以通过将文件上传到 Amazon S3 存储桶来测试此函数。使用以下示例日志行创建一个名为 sample.log 的文件:
12.345.678.90 - [10/Oct/2000:13:55:36 -0700] "PUT /some-file.jpg" 12.345.678.91 - [10/Oct/2000:14:56:14 -0700] "GET /some-file.jpg"
将文件上传到 S3 存储桶的 logs 文件夹。有关说明,请参阅 Amazon Simple Storage Service 用户指南中的将对象上传到存储桶。
然后使用 OpenSearch 服务控制台或 OpenSearch 仪表板验证lambda-s3-index索引是否包含两个文档。还可以发出标准搜索请求:
GET https://domain-name/lambda-s3-index/_search?pretty
{
"hits" : {
"total" : 2,
"max_score" : 1.0,
"hits" : [
{
"_index" : "lambda-s3-index",
"_type" : "_doc",
"_id" : "vTYXaWIBJWV_TTkEuSDg",
"_score" : 1.0,
"_source" : {
"ip" : "12.345.678.91",
"message" : "GET /some-file.jpg",
"timestamp" : "10/Oct/2000:14:56:14 -0700"
}
},
{
"_index" : "lambda-s3-index",
"_type" : "_doc",
"_id" : "vjYmaWIBJWV_TTkEuCAB",
"_score" : 1.0,
"_source" : {
"ip" : "12.345.678.90",
"message" : "PUT /some-file.jpg",
"timestamp" : "10/Oct/2000:13:55:36 -0700"
}
}
]
}
}