终止支持通知:2026 年 5 月 31 日, AWS 将终止对的支持。 AWS Panorama 2026 年 5 月 31 日之后,您将无法再访问 AWS Panorama 控制台或 AWS Panorama 资源。有关更多信息,请参阅AWS Panorama 终止支持。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
开发 AWS Panorama 应用程序
您可以使用示例应用程序了解 AWS Panorama 应用程序结构,并作为您自己的应用程序的起点。
下图显示了在 AWS Panorama Appliance 上运行的应用程序的主要组件。应用程序代码使用 AWS Panorama 应用程序 SDK 获取图像并与模型交互,但无法直接访问模型。该应用程序会将视频输出到连接的显示器,但不会将图像数据发送到本地网络之外。
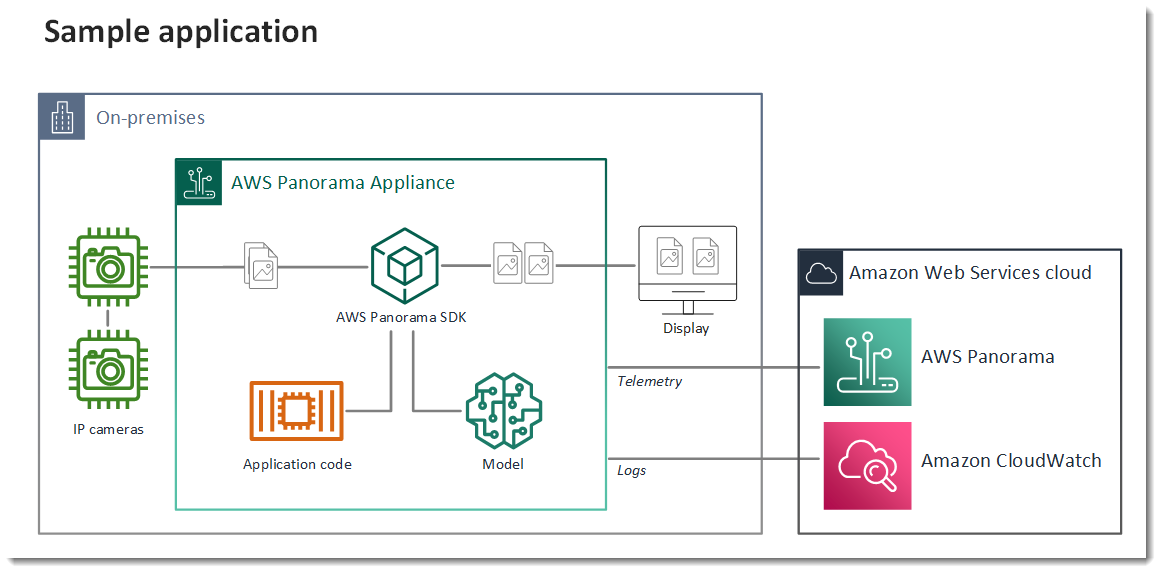
在此示例中,应用程序使用 AWS Panorama 应用程序 SDK 从摄像机获取视频帧,对视频数据进行预处理,然后将数据发送到可检测对象的计算机视觉模型。应用程序在连接到设备的 HDMI 显示器上显示结果。
应用程序清单
应用程序清单是 graphs 文件夹中名为 graph.json 的文件。清单定义了应用程序的组件,即程序包、节点和边缘。
软件包包括应用程序代码、模型、摄像头和显示器的代码、配置和二进制文件。此示例应用程序使用 4 个程序包:
例 graphs/aws-panorama-sample/graph.json - 程序包
"packages": [ { "name": "123456789012::SAMPLE_CODE", "version": "1.0" }, { "name": "123456789012::SQUEEZENET_PYTORCH_V1", "version": "1.0" }, { "name": "panorama::abstract_rtsp_media_source", "version": "1.0" }, { "name": "panorama::hdmi_data_sink", "version": "1.0" } ],
前两个程序包的定义见应用程序中的 packages 目录。包含此应用程序特有的代码和模型。后两个套餐是 AWS Panorama 服务提供的通用相机和显示器程序包。abstract_rtsp_media_source 程序包是摄像机的占位符,您可以在部署期间将其覆盖。hdmi_data_sink 程序包代表设备上的 HDMI 输出连接器。
节点是程序包的接口,也可以是非软件包参数的接口,这些参数有默认值,您可以在部署时将其覆盖。代码和模型程序包在指定输入和输出的 package.json 文件中定义接口,这些文件可以是视频流或基本数据类型,例如浮点、布尔或字符串类型。
例如,code_node 节点指的是 SAMPLE_CODE 程序包中的接口。
"nodes": [ { "name": "code_node", "interface": "123456789012::SAMPLE_CODE.interface", "overridable": false, "launch": "onAppStart" },
此接口是在程序包配置文件 package.json 中定义的。该接口指定程序包为业务逻辑,并将名为 video_in 的视频流和一个名为 threshold 的浮点数作为输入。该接口还规定,代码需要一个名为 video_out 的视频流缓冲才能将视频输出到显示器
例 packages/123456789012-SAMPLE_CODE-1.0/package.json
{ "nodePackage": { "envelopeVersion": "2021-01-01", "name": "SAMPLE_CODE", "version": "1.0", "description": "Computer vision application code.", "assets": [], "interfaces": [ { "name": "interface", "category": "business_logic", "asset": "code_asset", "inputs": [ { "name": "video_in", "type": "media" }, { "name": "threshold", "type": "float32" } ], "outputs": [ { "description": "Video stream output", "name": "video_out", "type": "media" } ] } ] } }
在应用程序清单中,camera_node 节点代表来自摄像机的视频流。该节点包括一个装饰器,在您部署应用程序时会出现在控制台中,提示您选择摄像机视频流。
例 graphs/aws-panorama-sample/graph.json - 摄像机节点
{ "name": "camera_node", "interface": "panorama::abstract_rtsp_media_source.rtsp_v1_interface", "overridable": true, "launch": "onAppStart", "decorator": { "title": "Camera", "description": "Choose a camera stream." } },
参数节点 threshold_param 定义应用程序代码使用的置信度阈值参数。默认值为 60,可在部署过程中覆盖。
例 graphs/aws-panorama-sample/graph.json - 参数节点
{ "name": "threshold_param", "interface": "float32", "value": 60.0, "overridable": true, "decorator": { "title": "Confidence threshold", "description": "The minimum confidence for a classification to be recorded." } }
应用程序清单的最后一部分 edges,是在节点之间建立连接。摄像机视频流和阈值参数连接到代码节点的输入端,代码节点的视频输出连接到显示器。
例 graphs/aws-panorama-sample/graph.json - 边缘
"edges": [ { "producer": "camera_node.video_out", "consumer": "code_node.video_in" }, { "producer": "code_node.video_out", "consumer": "output_node.video_in" }, { "producer": "threshold_param", "consumer": "code_node.threshold" } ]
使用示例应用程序构建
您可以将示例应用程序作为自己的应用程序的起点。
在您的账户中,每个程序包的名称必须是唯一的。如果您和您账户中的另一位用户都使用通用程序包名称(例如 code 或 model),则部署时可能会得到错误的程序包版本。将代码包的名称改为能代表您的应用程序的名称。
重命名代码包
-
重命名程序包文件夹:
packages/123456789012-。SAMPLE_CODE-1.0/ -
更新以下位置的程序包名称。
-
应用程序清单 -
graphs/aws-panorama-sample/graph.json -
程序包配置 -
packages/123456789012-SAMPLE_CODE-1.0/package.json -
生成脚本 -
3-build-container.sh
-
更新应用程序代码
-
在
packages/123456789012-SAMPLE_CODE-1.0/src/application.py中修改应用程序代码。 -
要构建容器,需运行
3-build-container.sh。aws-panorama-sample$./3-build-container.shTMPDIR=$(pwd) docker build -t code_asset packages/123456789012-SAMPLE_CODE-1.0 Sending build context to Docker daemon 61.44kB Step 1/2 : FROM public.ecr.aws/panorama/panorama-application ---> 9b197f256b48 Step 2/2 : COPY src /panorama ---> 55c35755e9d2 Successfully built 55c35755e9d2 Successfully tagged code_asset:latest docker export --output=code_asset.tar $(docker create code_asset:latest) gzip -9 code_asset.tar Updating an existing asset with the same name { "name": "code_asset", "implementations": [ { "type": "container", "assetUri": "98aaxmpl1c1ef64cde5ac13bd3be5394e5d17064beccee963b4095d83083c343.tar.gz", "descriptorUri": "1872xmpl129481ed053c52e66d6af8b030f9eb69b1168a29012f01c7034d7a8f.json" } ] } Container asset for the package has been succesfully built at ~/aws-panorama-sample-dev/assets/98aaxmpl1c1ef64cde5ac13bd3be5394e5d17064beccee963b4095d83083c343.tar.gzCLI 会自动从
assets文件夹中删除旧容器资产并更新程序包配置。 -
要上传程序包,请运行
4-package-application.py。 打开 AWS Panorama 控制台已部署的应用程序
页面。 选择应用程序。
-
选择替换。
-
完成以下步骤以部署应用程序。如果需要,您可以更改应用程序清单、摄像机视频流或参数。
更改计算机视觉模型
示例应用程序包括计算机视觉模型。要使用自己的模型,请修改模型节点的配置,然后使用 AWS Panorama 应用程序 CLI 将其作为资产导入。
以下示例使用 MXNet SSD ResNet 50 型号,您可以从本指南的 GitHub 存储库中下载该型号:ssd_512_resnet50_v1_voc.tar.gz
更改示例应用程序的模型
-
重命名程序包文件夹,以匹配您的模型。例如,前往
packages/。123456789012-SSD_512_RESNET50_V1_VOC-1.0/ -
更新以下位置的程序包名称。
-
应用程序清单 -
graphs/aws-panorama-sample/graph.json -
程序包配置 -
packages/123456789012-SSD_512_RESNET50_V1_VOC-1.0/package.json
-
-
在程序包配置文件 (
package.json) 中。将assets值改为空白数组。{ "nodePackage": { "envelopeVersion": "2021-01-01", "name": "SSD_512_RESNET50_V1_VOC", "version": "1.0", "description": "Compact classification model", "assets":[], -
打开程序包描述符文件 (
descriptor.json)。更新framework和shape值,以匹配您的模型。{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "MXNET", "inputs": [ { "name": "data", "shape": [1, 3, 512, 512] } ] } }shape 的值
1,3,512,512表示模型输入的图像数量 (1)、每张图像中的通道数(3 - 红色、绿色和蓝色)以及图像的尺寸(512 x 512)。数组的值和顺序因模型而异。 -
使用 AWS Panorama 应用程序 CLI 导入模型。AWS Panorama 应用程序 CLI 将模型和描述符文件复制到具有唯一名称的
assets文件夹中,并更新程序包配置。aws-panorama-sample$panorama-cli add-raw-model --model-asset-name model-asset \ --model-local-path{ "name": "model-asset", "implementations": [ { "type": "model", "assetUri": "b1a1589afe449b346ff47375c284a1998c3e1522b418a7be8910414911784ce1.tar.gz", "descriptorUri": "a6a9508953f393f182f05f8beaa86b83325f4a535a5928580273e7fe26f79e78.json" } ] }ssd_512_resnet50_v1_voc.tar.gz\ --descriptor-path packages/123456789012-SSD_512_RESNET50_V1_VOC-1.0/descriptor.json \ --packages-path packages/123456789012-SSD_512_RESNET50_V1_VOC-1.0 -
要上传模型,请运行
panorama-cli package-application。$panorama-cli package-applicationUploading package SAMPLE_CODE Patch Version 1844d5a59150d33f6054b04bac527a1771fd2365e05f990ccd8444a5ab775809 already registered, ignoring upload Uploading package SSD_512_RESNET50_V1_VOC Patch version for the package 244a63c74d01e082ad012ebf21e67eef5d81ce0de4d6ad1ae2b69d0bc498c8fd upload: assets/b1a1589afe449b346ff47375c284a1998c3e1522b418a7be8910414911784ce1.tar.gz to s3://arn:aws:s3:us-west-2:454554846382:accesspoint/panorama-123456789012-wc66m5eishf4si4sz5jefhx 63a/123456789012/nodePackages/SSD_512_RESNET50_V1_VOC/binaries/b1a1589afe449b346ff47375c284a1998c3e1522b418a7be8910414911784ce1.tar.gz upload: assets/a6a9508953f393f182f05f8beaa86b83325f4a535a5928580273e7fe26f79e78.json to s3://arn:aws:s3:us-west-2:454554846382:accesspoint/panorama-123456789012-wc66m5eishf4si4sz5jefhx63 a/123456789012/nodePackages/SSD_512_RESNET50_V1_VOC/binaries/a6a9508953f393f182f05f8beaa86b83325f4a535a5928580273e7fe26f79e78.json { "ETag": "\"2381dabba34f4bc0100c478e67e9ab5e\"", "ServerSideEncryption": "AES256", "VersionId": "KbY5fpESdpYamjWZ0YyGqHo3.LQQWUC2" } Registered SSD_512_RESNET50_V1_VOC with patch version 244a63c74d01e082ad012ebf21e67eef5d81ce0de4d6ad1ae2b69d0bc498c8fd Uploading package SQUEEZENET_PYTORCH_V1 Patch Version 568138c430e0345061bb36f05a04a1458ac834cd6f93bf18fdacdffb62685530 already registered, ignoring upload -
更新应用程序代码。大部分代码可以重复使用。模型响应的特定代码包含在
process_results方法中。def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" for class_tuple in inference_results: indexes = self.topk(class_tuple[0]) for j in range(2): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.25 + 0.1*j)根据您的模型,您可能还需要更新
preprocess方法。
预处理图像
在应用程序将图像发送到模型之前,它会调整图像大小并将颜色数据规范化,为推理做好准备。应用程序使用的模型需要具有三个颜色通道的 224 x 224 像素图像,以匹配其第一层的输入数。应用程序将每个颜色值转换为 0 到 1 之间的数字,减去该颜色的平均值,再除以标准差,以调整每个颜色值。最后,它合并颜色通道并将其转换为模型可以处理的 NumPy 数组。
例 application.py
def preprocess(self, img, width): resized = cv2.resize(img, (width, width)) mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] img = resized.astype(np.float32) / 255. img_a = img[:, :, 0] img_b = img[:, :, 1] img_c = img[:, :, 2] # Normalize data in each channel img_a = (img_a - mean[0]) / std[0] img_b = (img_b - mean[1]) / std[1] img_c = (img_c - mean[2]) / std[2] # Put the channels back together x1 = [[[], [], []]] x1[0][0] = img_a x1[0][1] = img_b x1[0][2] = img_c return np.asarray(x1)
此过程在以 0 为中心的可预测范围内给出模型值。它与应用于训练数据集中图像的预处理相匹配,这是一种标准方法,但每个模型可能会有所不同。
使用 SDK for Python 上传指标
该示例应用程序使用适用于 Python 的软件开发工具包将指标上传到亚马逊 CloudWatch。
例 application.py
def process_streams(self): """Processes one frame of video from one or more video streams.""" ... logger.info('epoch length: {:.3f} s ({:.3f} FPS)'.format(epoch_time, epoch_fps)) logger.info('avg inference time: {:.3f} ms'.format(avg_inference_time)) logger.info('max inference time: {:.3f} ms'.format(max_inference_time)) logger.info('avg frame processing time: {:.3f} ms'.format(avg_frame_processing_time)) logger.info('max frame processing time: {:.3f} ms'.format(max_frame_processing_time)) self.inference_time_ms = 0 self.inference_time_max = 0 self.frame_time_ms = 0 self.frame_time_max = 0 self.epoch_start = time.time()self.put_metric_data('AverageInferenceTime', avg_inference_time) self.put_metric_data('AverageFrameProcessingTime', avg_frame_processing_time)def put_metric_data(self, metric_name, metric_value): """Sends a performance metric to CloudWatch.""" namespace = 'AWSPanoramaApplication' dimension_name = 'Application Name' dimension_value = 'aws-panorama-sample' try: metric = self.cloudwatch.Metric(namespace, metric_name) metric.put_data( Namespace=namespace, MetricData=[{ 'MetricName': metric_name, 'Value': metric_value, 'Unit': 'Milliseconds', 'Dimensions': [ { 'Name': dimension_name, 'Value': dimension_value }, { 'Name': 'Device ID', 'Value': self.device_id } ] }] ) logger.info("Put data for metric %s.%s", namespace, metric_name) except ClientError: logger.warning("Couldn't put data for metric %s.%s", namespace, metric_name) except AttributeError: logger.warning("CloudWatch client is not available.")
其权限来自您在部署过程中分配的运行时角色。角色在aws-panorama-sample.yml CloudFormation 模板中定义。
例 aws-panorama-sample.yml
Resources: runtimeRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - panorama.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: cloudwatch-putmetrics PolicyDocument: Version: 2012-10-17 Statement:- Effect: Allow Action: 'cloudwatch:PutMetricData' Resource: '*'Path: /service-role/
示例应用程序使用 pip 安装 SDK for Python 和其他依赖项。构建应用程序容器时,Dockerfile 会运行命令在基础映像的基础上安装库。
例 Dockerfile
FROM public.ecr.aws/panorama/panorama-application WORKDIR /panorama COPY . . RUN pip install --no-cache-dir --upgrade pip && \ pip install --no-cache-dir -r requirements.txt
要在应用程序代码中使用 AWS SDK,请先修改模板以添加应用程序使用的所有 API 操作的权限。1-create-role.sh每次进行更改时都要运行来更新 CloudFormation 堆栈。然后,将更改部署到应用程序代码中。
对于修改或使用现有资源的操作,最佳做法是在单独的语句中为目标 Resource 指定名称或模式,以尽量缩小此策略的范围。有关每项服务支持的操作和资源的详细信息,请参阅服务授权参考中的操作、资源和条件键
后续步骤
有关使用 AWS Panorama 应用程序 CLI 从头开始构建应用程序和创建程序包的说明,请参阅 CLI 的 README 文件。
如需了解更多示例代码和测试工具,以便在部署前验证应用程序代码,请访问 AWS Panorama 示例存储库。
