本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
集群缓存管理
缓存是任何数据库 (DB) 最重要的功能之一,因为它有助于减少磁盘 I/O。最常访问的数据存储在称为缓冲区缓存的内存区域中。当查询频繁运行时,它会直接从缓存中检索数据,而不是从磁盘检索数据。这速度更快,可提供更好的可扩展性和应用程序性能。您可以使用shared_buffers参数配置 PostgreSQL 缓存大小。有关更多信息,请参阅内存
故障转移后,Amazon Aurora PostgreSQL 兼容版中的集群缓存管理 (CCM) 旨在提高应用程序和数据库的恢复性能。在没有 CCM 的典型故障转移情况下,您可能会看到暂时的但明显的性能下降。发生性能下降,是因为当故障转移数据库实例启动时,缓冲区缓冲区是空的。空缓存也称为冷缓存。数据库实例必须从磁盘读取,这比从缓存读取要慢。
在实现 CCM 时,选择首选的读取器数据库实例,CCM 会持续将其缓存内存与主数据库实例或写入器数据库实例的缓存内存同步。如果发生故障转移,首选读取器数据库实例将升级为新写入器数据库实例。由于它已经具有缓存内存,称为热缓存,因此可以最大限度地减少故障转移对应用程序性能的影响。
集群缓存管理是如何运作的?
故障转移数据库实例与主 writer 数据库实例位于不同的可用区域。首选 reader 数据库实例是优先级故障转移目标,通过为其分配 Tier-0 优先级来指定。
注意
提升层优先级 是指定在发生故障后将 Aurora 读取器提升为写入器数据库实例的顺序。有效值为 0–15,0 是第一个优先级,15 是最后一个。有关提升层的更多信息,请参阅 Aurora 数据库集群的容错能力。修改提升层不会导致中断。
CCM 将写入器数据库实例中的缓存同步到首选读取器数据库实例。读取器数据库实例将当前缓存的一组缓冲区地址作为布隆过滤器发送到 writer 数据库实例。Bloom 过滤器是一种概率的、内存效率高的数据结构,用于测试元素是否是集合的成员。使用布隆过滤器可防止读取器数据库实例重复向写入器数据库实例发送相同的缓冲区地址。当 writer 数据库实例收到布隆过滤器时,它会比较其缓冲区缓存中的数据块,并将常用的缓冲区发送到读取器数据库实例。默认情况下,如果缓冲区的使用次数大于三,则认为该缓冲区的使用次数是经常使用的。
下图显示 CCM 如何将 writer 数据库实例的缓冲区缓存与首选读取器数据库实例同步。
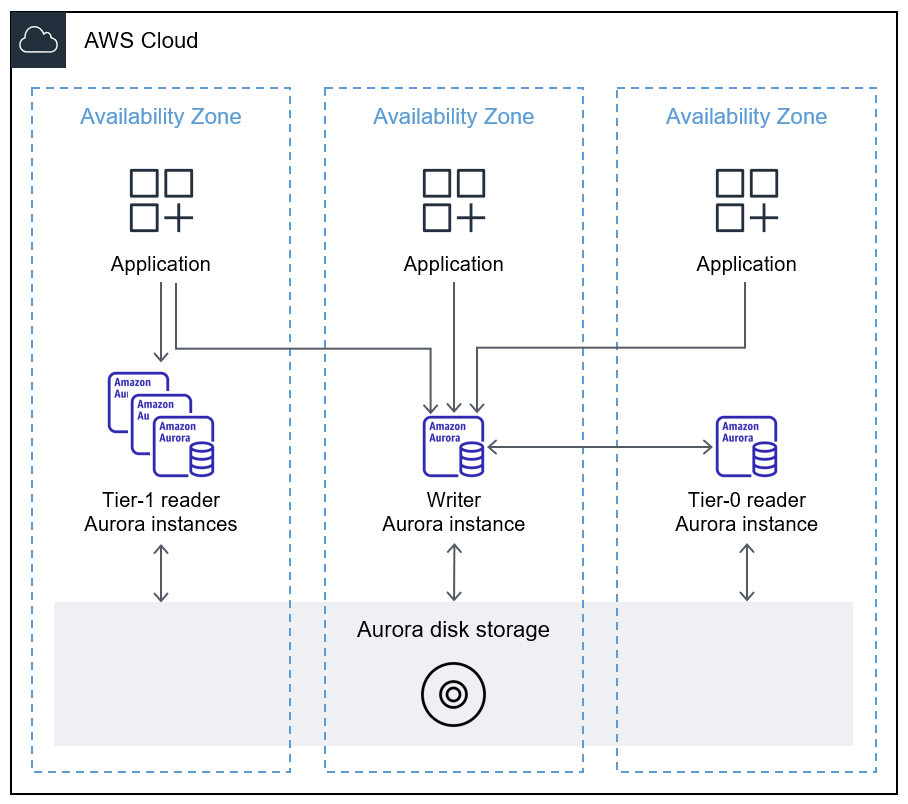
有关 CCM 的更多信息,请参阅 Aurora PostgreSQL 的集群缓存管理在故障转移后快速恢复(Aurora 文档)和 Aurora PostgreSQL 集群缓存管理简介
限制
CCM 功能具有以下限制:
-
读取器数据库实例必须具有与写入器数据库实例相同的数据库实例相同的数据库实例类类型和大小,例如
r5.2xlarge或db.r5.xlarge。 -
作为 Aurora 全局数据库一部分的 Aurora PostgreSQL 数据库集群不支持 CCM。
集群缓存管理的使用案例
对于某些行业,例如零售、银行和金融,仅几毫秒的延迟就会导致应用程序性能问题并导致重大业务损失。由于 CCM 通过持续将主数据库实例的缓冲缓存同步到首选备份实例来帮助恢复应用程序和数据库性能,因此它可以帮助防止与故障转移相关的业务损失。
