本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon 上训练和部署支持 GPU 的自定义机器学习模型 SageMaker
创建者:Ankur Shukla(AWS)
环境:PoC 或试点 | 技术:机器学习和人工智能;容器和微服务 | AWS 服务:亚马逊 ECS;亚马逊 SageMaker |
Summary
训练和部署支持图形处理单元 (GPU) 的机器学习 (ML) 模型需要对某些环境变量进行初始设置和初始化,才能充分发挥 NVIDIA GPU 的优势。但是,在亚马逊网络服务 (AWS) 云上设置环境并使其与亚马逊 SageMaker 架构兼容可能很耗时。
此模式可帮助您使用 Amazon 训练和构建支持 GPU 的自定义机器学习模型。 SageMaker它提供了训练和部署基于开源 Amazon Reviews 数据集构建的自定义 CatBoost 模型的步骤。然后,您可以在 p3.16xlarge Amazon Elastic Compute Cloud(Amazon EC2)实例上对其性能进行基准测试。
如果您的组织想要在上部署支持 GPU 的现有机器学习模型,则此模式非常有用。 SageMaker数据科学家可以按照此模式中的步骤创建支持 NVIDIA GPU 的容器,并在这些容器上部署 ML 模型。
先决条件和限制
先决条件
一个有效的 Amazon Web Services account。
Amazon Simple Storage Service(Amazon S3)源存储桶,用于存储模型构件和预测。
了解 SageMaker 笔记本实例和 Jupyter 笔记本。
了解如何创建具有基本 SageMaker 角色权限、S3 存储桶访问和更新权限以及亚马逊弹性容器注册表 (Amazon ECR) Container Registry (Amazon ECR) Registry 的额外权限的 AWS 身份和访问管理 (IAM) 角色。
限制
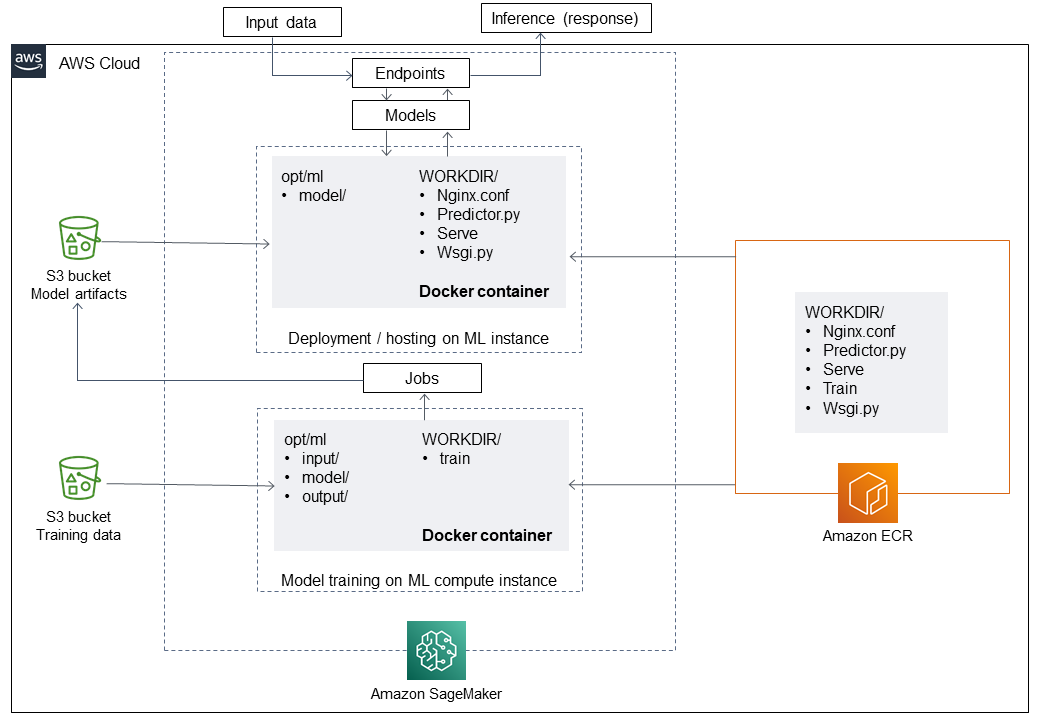
架构
技术堆栈
工具
Amazon ECR – Amazon Elastic Container Registry (Amazon ECR) 是一项 AWS 托管容器映像注册表服务,它安全、可扩展且可靠。
Amazon SageMaker — SageMaker 是一项完全托管的机器学习服务。
Docker – 是软件平台,可以快速构建、测试和部署应用程序。
Python – Python 是一种编程语言。
代码
此模式的代码可在使用 Catboost 和 SageMaker存储库 GitHub 实现审查分类模型中找到。
操作说明
| 任务 | 描述 | 所需技能 |
|---|
创建 IAM 角色并向其附加所需策略。 | 登录 AWS 管理控制台,打开 IAM 控制台并创建新的 IAM 角色。附加以下策略到 IAM 角色: 有关这方面的更多信息,请参阅 Amazon SageMaker 文档中的创建笔记本实例。 | 数据科学家 |
创建 SageMaker 笔记本实例。 | 打开 SageMaker 控制台,选择笔记本实例,然后选择创建笔记本实例。对于 IAM 角色,选择您之前创建的 IAM 角色。根据要求配置笔记本实例,然后选择创建笔记本实例。 有关详细步骤和说明,请参阅 Amazon SageMaker 文档中的创建笔记本实例。 | 数据科学家 |
克隆存储库。 | 在 SageMaker 笔记本实例中打开终端,运行以下命令克隆使用 Catboost 和 SageMaker存储库 GitHub实现评论分类模型: git clone https://github.com/aws-samples/review-classification-using-catboost-sagemaker.git
| |
启动 Jupyter 笔记本。 | 启动 Review classification model with Catboost and SageMaker.ipynb Jupyter 笔记本,其中包含预定义的步骤。 | 数据科学家 |
| 任务 | 描述 | 所需技能 |
|---|
在 Jupyter 笔记本中运行命令。 | 打开 Jupyter 笔记本并运行以下情节中的命令,准备用于训练 ML 模型的数据。 | 数据科学家 |
从 S3 存储桶读取数据。 | import pandas as pd
import csv
fname = 's3://amazon-reviews-pds/tsv/amazon_reviews_us_Digital_Video_Download_v1_00.tsv.gz'
df = pd.read_csv(fname,sep='\t',delimiter='\t',error_bad_lines=False)
| 数据科学家 |
预处理数据。 | import numpy as np
def pre_process(df):
df.fillna(value={'review_body': '', 'review_headline': ''}, inplace=True)
df.fillna( value={'verified_purchase': 'Unk'}, inplace=True)
df.fillna(0, inplace=True)
return df
df = pre_process(df)
df.review_date = pd.to_datetime(df.review_date)
df['target'] = np.where(df['star_rating']>=4,1,0)
注意:此代码将 'review_body' 中的空值替换为空字符串,并将该 'verified_purchase' 列替换为 'Unk',这意味着“未知”。 | 数据科学家 |
将数据拆分为训练、验证和测试数据集。 | 要保持目标标签在拆分集中的分布相同,必须使用 scikit-learn library 对采样进行分层。 from sklearn.model_selection import StratifiedShuffleSplit
sss = StratifiedShuffleSplit(n_splits=2, test_size=0.10, random_state=0)
sss.get_n_splits(df, df['target'])
for train_index, test_index in sss.split(df, df['target']):
X_train_vallid , X_test = df.iloc[train_index], df.iloc[test_index]
sss.get_n_splits(X_train_vallid, X_train_vallid['target'])
for train_index, test_index in sss.split(X_train_vallid, X_train_vallid['target']):
X_train , X_valid = X_train_vallid.iloc[train_index], X_train_vallid.iloc[test_index]
| 数据科学家 |
| 任务 | 描述 | 所需技能 |
|---|
准备并推送 Docker 映像。 | 在 Jupyter 笔记本中,运行以下情节中的命令来准备 Docker 映像并将其推送到 Amazon ECR。 | 机器学习工程师 |
在 Amazon ECR 中创建存储库。 | %%sh
algorithm_name=sagemaker-catboost-github-gpu-img
chmod +x code/train
chmod +x code/serve
account=$(aws sts get-caller-identity --query Account --output text)
# Get the region defined in the current configuration (default to us-west-2 if none defined)
region=$(aws configure get region)
region=${region:-us-east-1}
fullname="${account}.dkr.ecr.${region}.amazonaws.com/${algorithm_name}:latest"
aws ecr create-repository --repository-name "${algorithm_name}" > /dev/nul
| 机器学习工程师 |
在本地构建 Docker 映像。 | docker build -t "${algorithm_name}" .
docker tag ${algorithm_name} ${fullname}
| 机器学习工程师 |
运行 Docker 映像并将其推送到 Amazon ECR。 | docker push ${fullname}
| 机器学习工程师 |
| 任务 | 描述 | 所需技能 |
|---|
创建 SageMaker 超参数调整作业。 | 在 Jupyter 笔记本中,运行以下故事中的命令,使用你的 Docker 镜 SageMaker 像创建超参数调整作业。 | 数据科学家 |
创建 SageMaker 估算器。 | 使用 Docker 镜像的名称创建SageMaker 估算器。 import sagemaker as sage
from time import gmtime, strftime
sess = sage.Session()
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
account = sess.boto_session.client('sts').get_caller_identity()['Account']
region = sess.boto_session.region_name
image = '{}.dkr.ecr.{}.amazonaws.com/sagemaker-catboost-github-gpu-img:latest'.format(account, region)
tree_hpo = sage.estimator.Estimator(image,
role, 1,
'ml.p3.16xlarge',
train_volume_size = 100,
output_path="s3://{}/sagemaker/DEMO-GPU-Catboost/output".format(bucket),
sagemaker_session=sess)
| 数据科学家 |
创建 HPO 作业。 | 使用参数范围创建超参数优化(HPO)调整作业,并将训练集和验证集作为参数传递给函数。 hyperparameter_ranges = {'iterations': IntegerParameter(80000, 130000),
'max_depth': IntegerParameter(6, 10),
'max_ctr_complexity': IntegerParameter(4, 10),
'learning_rate': ContinuousParameter(0.01, 0.5)}
objective_metric_name = 'auc'
metric_definitions = [{'Name': 'auc',
'Regex': 'auc: ([0-9\\.]+)'}]
tuner = HyperparameterTuner(tree_hpo,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
objective_type='Maximize',
max_jobs=50,
max_parallel_jobs=2)
| 数据科学家 |
运行 HPO 作业。 | train_location = 's3://'+bucket+'/sagemaker/DEMO-GPU-Catboost/data/train/'
valid_location = 's3://'+bucket+'/sagemaker/DEMO-GPU-Catboost/data/valid/'
tuner.fit({'train': train_location,
'validation': valid_location })
| 数据科学家 |
接收表现最好的训练作业。 | import sagemaker as sage
from time import gmtime, strftime
sess = sage.Session()
best_job =tuner.best_training_job()
| 数据科学家 |
| 任务 | 描述 | 所需技能 |
|---|
对测试数据创建 SageMaker 批量转换作业,以进行模型预测。 | 在 Jupyter 笔记本中,运行以下故事中的命令,通过 SageMaker 超参数调整作业创建模型,并提交对测试数据的 SageMaker 批量转换作业以进行模型预测。 | 数据科学家 |
创建 SageMaker 模型。 | 使用最佳训练作业在 SageMaker 模型中创建模型。 attached_estimator = sage.estimator.Estimator.attach(best_job)
output_path ='s3://'+bucket+'/sagemaker/DEMO-GPU-Catboost/data/test-predictions/'
input_path ='s3://'+bucket+'/sagemaker/DEMO-GPU-Catboost/data/test/'
transformer = attached_estimator.transformer(instance_count=1,
instance_type='ml.p3.16xlarge',
assemble_with='Line',
accept='text/csv',
max_payload=1,
output_path=output_path,
env = {'SAGEMAKER_MODEL_SERVER_TIMEOUT' : '3600' })
| 数据科学家 |
创建批量转换作业。 | 在测试数据集上创建批量转换作业。 transformer.transform(input_path,
content_type='text/csv',
split_type='Line')
| 数据科学家 |
| 任务 | 描述 | 所需技能 |
|---|
阅读结果并评估模型的性能。 | 在 Jupyter 笔记本中,运行以下情节中的命令,阅读结果并评估模型在 ROC 曲线下面积(ROC-AUC)模型和精确率-召回率曲线下面积(PR-AUC)模型指标的性能。 有关这方面的更多信息,请参阅 Amazon Machine Learning (Amazon ML) 文档中的 Amazon 机器学习关键概念。 | 数据科学家 |
阅读批量转换作业结果。 | 将批量转换作业结果读入数据框。 file_name = 's3://'+bucket+'/sagemaker/DEMO-GPU-Catboost/data/test-predictions/file_1.out'
results = pd.read_csv(file_name, names=['review_id','target','score'] ,sep='\t',escapechar ='\\' , quoting=csv.QUOTE_NONE,
lineterminator='\n',quotechar='"').dropna()
| 数据科学家 |
评估性能指标。 | 在 ROC-AUC 和 PR-AUC 上评估模型的性能。 from sklearn import metrics
import matplotlib
import pandas as pd
matplotlib.use('agg', warn=False, force=True)
from matplotlib import pyplot as plt
%matplotlib inline
def analyze_results(labels, predictions):
precision, recall, thresholds = metrics.precision_recall_curve(labels, predictions)
auc = metrics.auc(recall, precision)
fpr, tpr, _ = metrics.roc_curve(labels, predictions)
roc_auc_score = metrics.roc_auc_score(labels, predictions)
print('Neural-Nets: ROC auc=%.3f' % ( roc_auc_score))
plt.plot(fpr, tpr, label="data 1, auc=" + str(roc_auc_score))
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
plt.legend(loc=4)
plt.show()
lr_precision, lr_recall, _ = metrics.precision_recall_curve(labels, predictions)
lr_auc = metrics.auc(lr_recall, lr_precision)
# summarize scores
print('Neural-Nets: PR auc=%.3f' % ( lr_auc))
# plot the precision-recall curves
no_skill = len(labels[labels==1.0]) / len(labels)
plt.plot([0, 1], [no_skill, no_skill], linestyle='--', label='No Skill')
plt.plot(lr_recall, lr_precision, marker='.', label='Neural-Nets')
# axis labels
plt.xlabel('Recall')
plt.ylabel('Precision')
# show the legend
plt.legend()
# show the plot
plt.show()
return auc
analyze_results(results['target'].values,results['score'].values)
| 数据科学家 |
相关资源
其他信息
以下列表显示了 Dockerfile 的不同元素,这些元素在构建、运行 Docker 映像并将其推送到 Amazon ECR操作说明中运行。
使用 aws-cli 安装 Python。
FROM amazonlinux:1
RUN yum update -y && yum install -y python36 python36-devel python36-libs python36-tools python36-pip && \
yum install gcc tar make wget util-linux kmod man sudo git -y && \
yum install wget -y && \
yum install aws-cli -y && \
yum install nginx -y && \
yum install gcc-c++.noarch -y && yum clean all
安装 Python 软件包
RUN pip-3.6 install --no-cache-dir --upgrade pip && \pip3 install --no-cache-dir --upgrade setuptools && \
pip3 install Cython && \
pip3 install --no-cache-dir numpy==1.16.0 scipy==1.4.1 scikit-learn==0.20.3 pandas==0.24.2 \
flask gevent gunicorn boto3 s3fs matplotlib joblib catboost==0.20.2
安装 CUDA 和 CuDNN
RUN wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda_9.0.176_384.81_linux-run \
&& chmod u+x cuda_9.0.176_384.81_linux-run \
&& ./cuda_9.0.176_384.81_linux-run --tmpdir=/data --silent --toolkit --override \
&& wget https://custom-gpu-sagemaker-image.s3.amazonaws.com/installation/cudnn-9.0-linux-x64-v7.tgz \
&& tar -xvzf cudnn-9.0-linux-x64-v7.tgz \
&& cp /data/cuda/include/cudnn.h /usr/local/cuda/include \
&& cp /data/cuda/lib64/libcudnn* /usr/local/cuda/lib64 \
&& chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn* \
&& rm -rf /data/*
为创建所需的目录结构 SageMaker
RUN mkdir /opt/ml /opt/ml/input /opt/ml/input/config /opt/ml/input/data /opt/ml/input/data/training /opt/ml/model /opt/ml/output /opt/program
设置 NVIDIA 环境变量
ENV PYTHONPATH=/opt/program
ENV PYTHONUNBUFFERED=TRUE
ENV PYTHONDONTWRITEBYTECODE=TRUE
ENV PATH="/opt/program:${PATH}"
# Set NVIDIA mount environments
ENV LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:$LD_LIBRARY_PATH
ENV NVIDIA_VISIBLE_DEVICES="all"
ENV NVIDIA_DRIVER_CAPABILITIES="compute,utility"
ENV NVIDIA_REQUIRE_CUDA "cuda>=9.0"
将训练和推理文件复制到 Docker 映像中
COPY code/* /opt/program/
WORKDIR /opt/program