本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
rank 函数计算某个度量或维度相对于指定分区的排名。它计算一次每个项目(即使是重复的),并分配一个“带孔的”排名以考虑到重复的值。
语法
括号是必需的。要查看哪些参数是可选的,请参阅以下说明。
rank ([ sort_order_field ASC_or_DESC, ... ],[ partition_field, ... ])
参数
- 排序顺序字段
-
要在对数据排序时使用的一个或多个聚合度量和维度(以逗号分隔)。您可以指定升序 (
ASC) 或降序 (DESC) 排序顺序。如果包含多个单词,则将列表中的每个字段括在 {}(大括号)内。整个列表括在 [](方括号)内。
- 分区字段
-
(可选)要在分区时使用的一个或多个维度(以逗号分隔)。
如果包含多个单词,则将列表中的每个字段括在 {}(大括号)内。整个列表括在 [](方括号)内。
- 计算级别
-
(可选)指定要使用的计算级别:
-
PRE_FILTER– 在数据集筛选条件之前计算预筛选条件计算。 -
PRE_AGG– 在将聚合以及前 N 个和后 N 个筛选条件应用于视觉对象之前计算预聚合计算。 -
POST_AGG_FILTER–(默认)在显示视觉对象时计算表格计算。
留空时此值默认为
POST_AGG_FILTER。有关更多信息,请参阅 在 Amazon 中使用关卡感知计算 QuickSight。 -
示例
以下示例根据降序排序顺序按 State 和 City 在 State WA 中对 max(Sales) 进行排名。将为具有相同 max(Sales) 的任何城市分配相同的排名,但下一个排名包括所有以前存在的排名计数。例如,如果三个城市具有相同的排名,则第四个城市排名第四。
rank
(
[max(Sales) DESC],
[State, City]
)以下示例根据升序排序顺序按 State 对 max(Sales) 进行排名。将为具有相同 max(Sales) 的任何州/省分配相同的排名,但下一个排名包括所有以前存在的排名计数。例如,如果三个州/省具有相同的排名,则第四个州/省排名第四。
rank
(
[max(Sales) ASC],
[State]
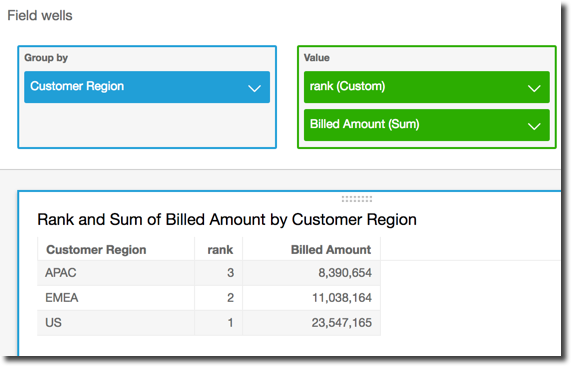
)以下示例按总数 Billed
Amount 对 Customer Region 进行排名。表计算中的字段位于视觉对象的字段井中。
rank(
[sum({Billed Amount}) DESC]
)在以下屏幕截图中显示了示例的结果以及总数 Billed Amount,因此,您可以了解每个区域是如何进行排名的。