从补丁 198 开始,Amazon Redshift 将不再支持创建新的 Python UDF。现有的 Python UDF 将继续正常运行至 2026 年 6 月 30 日。有关更多信息,请参阅博客文章
Machine Learning
Amazon Redshift 机器学习 (Amazon Redshift ML) 是一种基于云的稳健服务,能够让所有技能水平的分析人员和数据科学家都能更轻松使用机器学习技术。Amazon Redshift ML 使用模型生成结果。您可以通过以下方式使用模型:
您可以向 Amazon Redshift 提供要用于训练模型的数据以及与数据输入相关的元数据。然后,Amazon Redshift ML 在 Amazon SageMaker AI 中创建模型来捕获输入数据中的模式。通过使用自己的数据建立模型,您可以使用 Amazon Redshift ML 来识别数据中的趋势,如客户流失预测、客户生命周期价值或收入预测。您可以使用这些模型为新输入数据生成预测结果,而无需支付额外费用。
您可以使用 Amazon Bedrock 提供的基础模型(FM)之一,如 Claude 或 Amazon Titan。使用 Amazon Bedrock,您只需几步就能将大型语言模型(LLM)的强大功能与 Amazon Redshift 中的分析数据结合起来。通过使用外部大型语言模型(LLM),您可以使用 Amazon Redshift 对数据执行自然语言处理(NLP)。您可以将 NLP 用于文本生成、情绪分析或翻译等应用。有关将 Amazon Bedrock 与 Amazon Redshift 结合使用的信息,请参阅 Amazon Redshift ML 与 Amazon Bedrock 集成。
注意
选择不使用您的数据来改进服务
如果您使用的是 Amazon Bedrock 模型,我们鼓励您阅读有关 Amazon Bedrock 服务如何处理您的数据的 AWS 策略。如果 Amazon Bedrock 将来会使用您的数据进行模型或服务改进,您应确定是否需要使用选择退出策略来阻止该服务实施此类功能。为确保服务不会将您的数据用于此类目的,请使用常规 AWS 选择退出策略。
有关更多信息,请参阅下列内容:
注意
LLM 可生成不准确或不完整的信息。我们建议核实 LLM 产生的信息,以确保其准确性和完整性。
Amazon Redshift ML 如何与 Amazon SageMaker AI 结合使用
Amazon Redshift 与 Amazon SageMaker AI Autopilot 结合使用,以自动获取最佳模型并使预测函数在 Amazon Redshift 中可用。
下图说明了 Amazon Redshift ML 的工作原理。
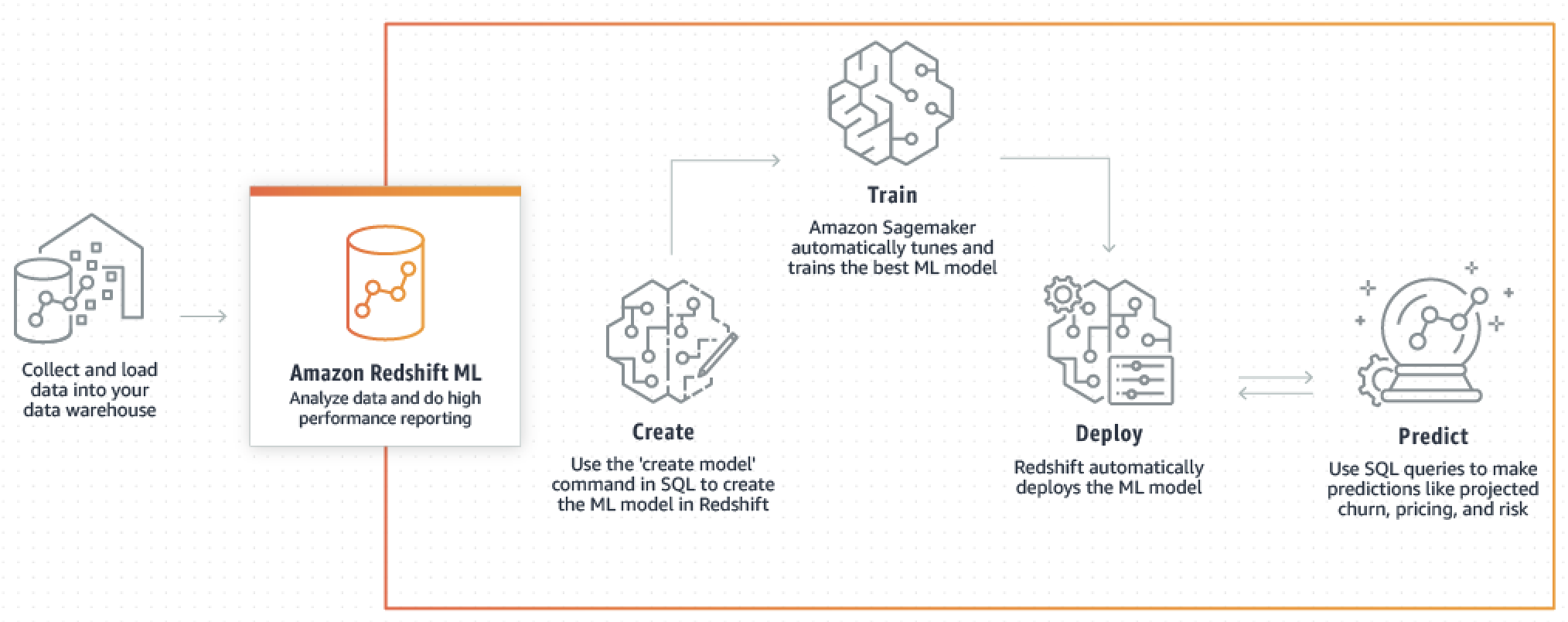
常见工作流程如下:
-
Amazon Redshift 将训练数据导出到 Simple Storage Service(Amazon S3)中。
-
Amazon SageMaker AI Autopilot 预处理训练数据。预处理执行重要功能,例如插入缺失值。它认识到有些列是分类的(如邮政编码),正确设置它们的格式以进行训练,并执行许多其他任务。选择要应用于训练数据集的最佳预处理器本身就是一个问题,Amazon SageMaker AI Autopilot 可自动执行其解决方案。
-
Amazon SageMaker AI Autopilot 查找算法和算法超参数,从而为模型提供最准确的预测结果。
-
Amazon Redshift 会在您的 Amazon Redshift 集群中将预测函数注册为 SQL 函数。
-
当您运行 CREATE MODEL 语句时,Amazon Redshift 使用 Amazon SageMaker AI 进行训练。因此,训练模型会产生相关的成本。这是 Amazon SageMaker AI 在您的 AWS 账单中的单独行项目。您还需要为 Simple Storage Service(Amazon S3)中用于存储训练数据的存储支付费用。使用可在 Redshift 集群上编译和运行的 CREATE MODEL 创建的模型进行推断不会产生费用。使用 Amazon Redshift ML 不会产生额外的 Amazon Redshift 费用。
主题
