本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
异步推理
Amazon SageMaker 异步推理是 SageMaker AI 中的一项功能,它可以对传入的请求进行排队并异步处理这些请求。此选项非常适合具有较大负载(最大 1GB)、较长处理时间(最长 1 小时)以及接近实时延迟要求的请求。通过异步推理,您可以在没有请求要处理时自动将实例计数缩放到零,这样您只需在端点处理请求时才付费,从而节省成本。
工作方式
创建异步推理端点的方法类似于创建实时推理端点。您可以使用现有的 SageMaker AI 模型,只需在使用 CreateEndpointConfig API 中的EndpointConfig字段创建终端节点配置时指定AsyncInferenceConfig对象即可。下图显示了异步推理的架构和工作流。
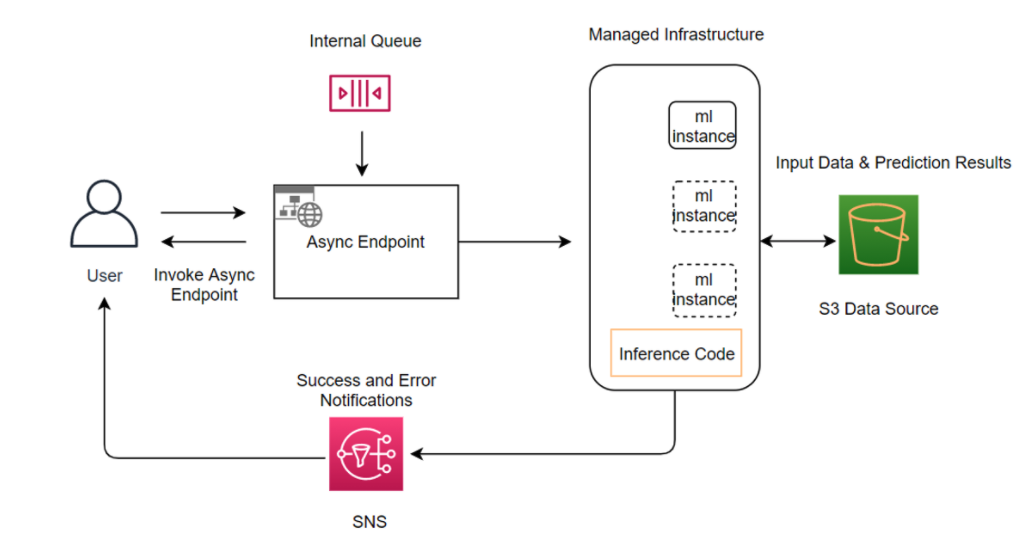
要调用端点,您需要将请求有效载荷放入 Amazon S3。您还需要在 InvokeEndpointAsync 请求中提供指向此有效载荷的指针。调用后, SageMaker AI 会将请求排队等候处理,并返回标识符和输出位置作为响应。处理后, SageMaker AI 会将结果放在 Amazon S3 的位置。您可以选择通过 Amazon SNS 接收成功或出错通知。有关如何设置异步通知的更多信息,请参阅检查预测结果。
注意
端点配置中存在异步推理配置 (AsyncInferenceConfig) 对象意味着端点只能接收异步调用。
怎样入门?
如果您是首次使用 Amazon SageMaker 异步推理,我们建议您执行以下操作:
-
阅读 异步端点操作,了解有关如何创建、调用、更新和删除异步端点的信息。
请注意,如果您的端点使用本排除项页面列出的任何功能,则无法使用异步推理。
