本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将预测结果与输入记录关联
当针对大型数据集进行预测时,可以排除进行预测时不需要的属性。进行预测后,您可以将某些排除的属性和这些预测或报告中的其他输入数据关联起来。通过使用批量转换来执行这些数据处理步骤,您通常可以消除其他预处理或后处理。您只能使用 JSON 和 CSV 格式的输入文件。
将推理与输入记录相关联的工作流
下图显示将推理与输入记录相关联的工作流程。
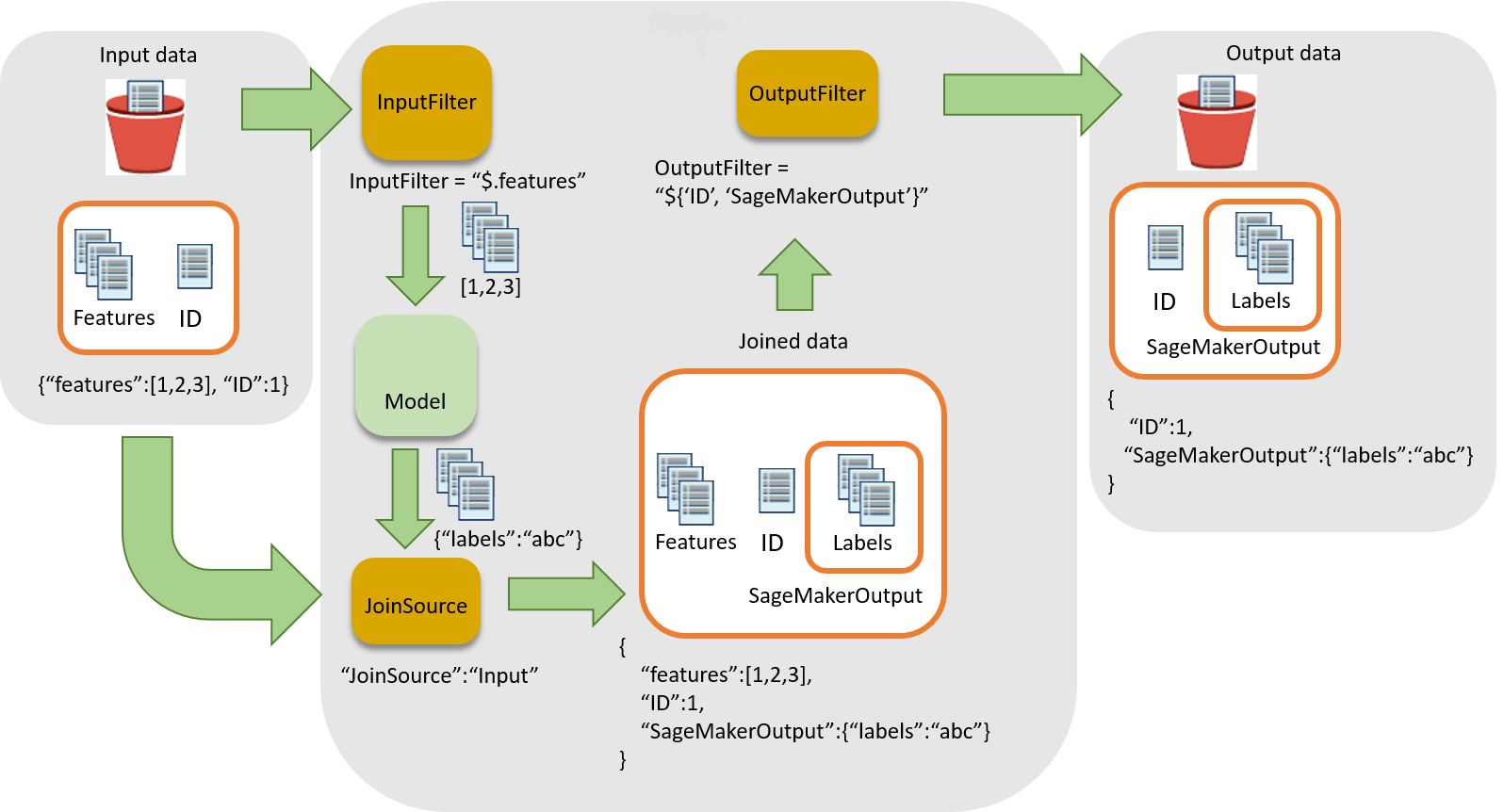
要将推理与输入数据相关联,有三个主要步骤:
-
筛选进行推理时不需要的输入数据,然后再将输入数据传递到批量转换作业。使用
InputFilter参数来确定要将哪些属性用作模型的输入。 -
将输入数据和推理结果关联。使用
JoinSource参数将输入数据与推理结合起来。 -
筛选联接的数据,以保留用来为解释报告中的预测提供上下文所需的输入。使用
OutputFilter存储输出文件中联接的数据集的指定部分。
在批量转换作业中使用数据处理
在使用 CreateTransformJob 创建批量转换作业来处理数据时:
-
使用
DataProcessing数据结构中的InputFilter参数指定要传输到模型中的输入的部分。 -
使用
JoinSource参数联接原始输入数据和转换后的数据。 -
使用
OutputFilter参数指定批量转换作业中哪部分联接输入数据和转换后的数据要包含在输出文件中。 -
选择 JSON 或 CSV-formatted 文件进行输入:
-
对于 JSON 或 JSON Lines-formatted 输入文件, SageMaker AI 要么将
SageMakerOutput属性添加到输入文件,要么使用SageMakerInput和SageMakerOutput属性创建一个新的 JSON 输出文件。有关更多信息,请参阅DataProcessing。 -
对于 CSV-formatted 输入文件,连接的输入数据后面是转换后的数据,输出是 CSV 文件。
-
如果您使用的是带有 DataProcessing 结构的算法,它必须“同时”对输入和输出文件支持您选择的格式。例如,对于 CreateTransformJob API 的 TransformOutput 字段,您必须同时将 ContentType 和 Accept 参数设置为以下值之一:text/csv、application/json 或 application/jsonlines。在 CSV 文件中指定列的语法与在 JSON 文件中指定属性的语法是不同的。使用错误的语法会导致错误。有关更多信息,请参阅 批量转换示例。有关用于内置算法的输入和输出文件格式的更多信息,请参阅Built-in Amazon 中的算法和预训练模型 SageMaker。
输入和输出的记录分隔符也必须符合所选的文件输入。SplitType 参数指示如何拆分输入数据集内的记录。AssembleWith 参数指示如何重组记录以便输出。如果您将输入和输出格式设置为 text/csv,还必须将 SplitType 和 AssembleWith 参数设置为 line。如果您将输入和输出格式设置为 application/jsonlines,则可以将 SplitType 和 AssembleWith 这两者设置为 line。
对于 CSV 文件,不能使用嵌入式换行符。对于 JSON 文件,属性名称 SageMakerOutput 预留用于输出。JSON 输入文件不得具有使用此名称的属性。否则,输入文件中的数据可能被覆盖。
支持的 JSONPath 运算符
要筛选并联接输入数据和推理,请使用 JSONPath 子表达式。 SageMaker AI 仅支持已定义的 JSONPath 运算符的子集。下表列出了支持的 JSONPath 运算符。对于 CSV 数据,每一行都被视为 JSON 数组,因此只能应用基于索引的 JSONPath,例如 $[0]、$[1:]。CSV 数据也应遵循 RFC 格式
| JSONPath 运算符 | 说明 | 示例 |
|---|---|---|
$ |
查询的根元素。所有路径表达式的开头都需要此运算符。 |
$ |
. |
一个以点表示的子元素。 |
|
* |
一个通配符。用来代替属性名称或数值。 |
|
[' |
一个括号表示的元素或多个子元素。 |
|
[ |
一个索引或索引数组。也支持否定索引值。 |
|
[ |
数组 Slice 运算符。数组 slice() 方法提取数组的一部分并返回一个新数组。如果省略 |
|
使用括号表示法指定给定字段的多个子元素时,不支持在括号内添加子元素。例如,支持 $.field1.['child1','child2'] 而不支持 $.field1.['child1','child2.grandchild']。
有关 JSONPath 运算符的更多信息,请参阅JsonPath
批量转换示例
以下示例显示了一些将输入数据与预测结果联接的常用方法。
示例:仅输出推理
默认情况下,DataProcessing 参数不将推理结果与输入联接。它仅输出推理结果。
如果您想明确指定不将结果与输入连接起来,请使用 Amaz SageMaker on Python 软件开发工具包
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
要使用适用于 Python 的 AWS 软件开发工具包输出推论,请在 CreateTransformJob 请求中添加以下代码。下面的代码模仿了默认行为。
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
示例:输出推理与输入数据联接
如果您使用 Amaz SageMaker on Python 软件开发工具包assemble_with和accept参数。使用转换调用时,请为 join_source 参数指定 Input,同时指定 split_type 和 content_type 参数。split_type 参数的值必须与 assemble_with 相同,content_type 参数的值必须与 accept 相同。有关参数及其可接受值的更多信息,请参阅 Amazon A SageMaker I Python SDK 中的 Transformer 页面。
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
如果您使用的是 Python AWS 开发工具包 (Boto 3),请在请求中添加以下代码,将所有输入数据与推理结合起来。CreateTransformJobAccept 和 ContentType 的值必须匹配,并且 AssembleWith 和 SplitType 的值也必须匹配。
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
对于 JSON 或 JSON 行输入文件,结果位于输入 JSON 文件的 SageMakerOutput 键中。例如,如果输入是一个 JSON 文件,其中包含键值对 {"key":1},则数据转换结果可能是 {"label":1}。
SageMaker AI 将两者都存储在SageMakerInput密钥的输入文件中。
{ "key":1, "SageMakerOutput":{"label":1} }
注意
JSON 的联接结果必须是键值对对象。如果输入不是键值对对象, SageMaker AI 会创建一个新的 JSON 文件。在新的 JSON 文件中,输入数据存储在 SageMakerInput 键中,而结果存储为 SageMakerOutput 值。
对于 CSV 文件,例如,如果记录 [1,2,3],且标签结果为 [1],则输出文件将包含 [1,2,3,1]。
示例:输出推理与输入数据联接并从输入中排除 ID 列 (CSV)
如果您使用 Amaz SageMaker on Python SDKinput_filter例如,如果您的输入数据包含五列,而第一列是 ID 列,则使用以下转换请求选择除 ID 列之外的所有列作为特征。转换器仍会输出与推理相联接的所有输入列。有关参数及其可接受值的更多信息,请参阅 Amazon A SageMaker I Python SDK 中的 Transformer 页面。
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
如果您使用的是 Python AWS 开发工具包 (Boto 3),请在
CreateTransformJob请求中添加以下代码。
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
要在 SageMaker AI 中指定列,请使用数组元素的索引。第一列是索引 0,第二列是索引 1,第六列是索引 5。
要从输入中排除第一列,请将 InputFilter 设置为 "$[1:]"。冒号 (:) 告诉 SageMaker AI 包含两个值之间的所有元素(包括在内)。例如,$[1:4] 指定第二列到第五列。
如果您省略冒号后的数字,例如 [5:],则子集包含第六列至最后一列的所有列。如果您省略冒号前的数字,例如 [:5],则子集包含第一列(索引 0)至第六列的所有列。
示例:输出与 ID 列联接的推理并从输入中排除 ID 列 (CSV)
如果您使用的是 Amaz SageMaker on Python 软件开发工具包output_filter的输出。output_filter 使用 JSONPath 子表达式来指定在将输入数据与推理结果联接后将哪些列作为输出返回。以下请求显示了如何在排除某个 ID 列的同时进行预测,然后将 ID 列与推理相联接。请注意,在以下示例中,输出的最后一列 (-1) 包含推理。如果您使用的是 JSON 文件, SageMaker AI 会将推理结果存储在属性SageMakerOutput中。有关参数及其可接受值的更多信息,请参阅 Amazon A SageMaker I Python SDK 中的 Transformer 页面。
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
如果您使用的是 Python AWS 开发工具包 (Boto 3),请在请求中添加以下代码,仅将 CreateTransformJobID 列与推断相连。
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
警告
如果您使用的是 JSON-formatted 输入文件,则该文件不能包含属性名称SageMakerOutput。此属性名称预留供输出文件中的推理使用。如果您的 JSON-formatted 输入文件包含具有此名称的属性,则推断可能会覆盖输入文件中的值。
