本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
为模型构建准备数据
注意
现在,你可以使用 Data Wrangler 在 SageMaker Canvas 中进行高级数据准备,它为你提供了自然语言界面和 300 多种内置转换。有关更多信息,请参阅 数据准备。
在构建模型之前,您的机器学习数据集可能需要准备数据。由于各种问题(可能包括缺失值或异常值),您可能需要清理数据,并执行特征工程以提高模型的准确性。Amazon SageMaker Canvas 提供机器学习数据转换,您可以使用它来清理、转换和准备数据以进行模型构建。您无需任何代码即可在数据集中使用这些变换。 SageMaker Canvas 将你使用的变换添加到模型配方中,该配方记录了在构建模型之前对数据所做的准备工作。您使用的任何数据转换都只会修改用于构建模型的输入数据,而不会修改原始数据来源。
数据集的预览会显示数据集的前 100 行数据。如果数据集的行数超过 2 万行,Canvas 会随机抽取 2 万行样本,并预览该样本中的前 100 行数据。您只能从预览行中搜索和指定值,而筛选器功能只能筛选预览行,而不能筛选整个数据集。
Can SageMaker vas 中提供了以下变换,供您为构建数据做好准备。
注意
只能对基于表格数据集构建的模型使用高级转换。多元文本预测模型也排除在外。
删除列
您可以将某列拖放到 C SageMaker anvas 应用程序的 “构建” 选项卡中,将该列从模型构建中排除。取消选择要删除的列,在构建模型时该列将不包括在内。
注意
如果您删除列,然后使用模型进行批量预测, SageMaker Canvas 会将删除的列重新添加到可供您下载的输出数据集中。但是,对于时间序列模型, SageMaker Canvas 不会重新添加已删除的列。
筛选行
筛选功能可根据您指定的条件筛选预览行(数据集的前 100 行)。筛选行会创建数据的临时预览,不会影响模型构建。您可以通过筛选来预览缺失值、包含异常值或符合您所选列中自定义条件的行。
按缺失值筛选行
在机器学习数据集中,缺失值是一种常见情况。如果某些列中的行值为 null 值或为空值,则可能需要筛选和预览这些行。
要从预览数据中筛选缺失值,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “按行筛选” (
 )。
)。 -
选择要检查缺失值的列。
-
在操作中,选择是缺失值。
SageMaker 画布筛选所选列中包含缺失值的行,并提供筛选后的行的预览。

按异常值筛选行
异常值或数据分布和范围中的稀有值可能会对模型精度产生负面影响,并导致更长的构建时间。 SageMaker Canvas 允许您检测和筛选数字列中包含异常值的行。您可以选择使用标准差或自定义范围来定义异常值。
要筛选数据中的异常值,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “按行筛选” (
)。 -
选择要检查异常值的列。
-
在操作中,选择是异常值。
-
将异常值范围设置为标准差或自定义范围。
-
如果选择标准差,请指定 1–3 之间的 SD(标准差)值。如果选择自定义范围,请选择百分位数或数字,然后指定最小值和最大值。
标准差选项使用平均值和标准差来检测和筛选数值列中的异常值。您可以指定一个值必须与平均值相差多少个标准差才能被视为异常值。例如,如果您指定 SD 为 3,那么一个值必须偏离平均值 3 个标准差以上才会被视为异常值。
自定义范围选项使用最小值和最大值来检测和筛选数值列中的异常值。如果您知道划分异常值的阈值,请使用此方法。您可以将范围的类型设置为百分位数或数字。如果选择百分位数,则最小值和最大值应是您想要允许的百分位数范围 (0-100) 的最小值和最大值。如果选择数字,则最小值和最大值应为要在数据中筛选的最小和最大数值。

按自定义值筛选行
您可以筛选具有满足自定义条件的值的行。例如,您可能希望在删除价格值大于 100 的行之前预览这些行。使用此功能,您可以筛选超过您设置的阈值的行并预览已筛选的数据。
要使用自定义筛选功能,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “按行筛选” (
)。 -
选择要检查的列。
-
选择要使用的操作类型,然后为所选条件指定值。
对于操作,您可以选择以下选项之一。请注意,可用的操作取决于您选择的列的数据类型。例如,您无法为包含文本值的列创建 is greater than 操作。
| 操作 | 支持的数据类型 | 支持的特征类型 | 功能 |
|---|---|---|---|
|
等于 |
数值、文本 |
二进制、分类 |
筛选列中值等于指定值的行。 |
|
不等于 |
数值、文本 |
二进制、分类 |
筛选列中值不等于指定值的行。 |
|
小于 |
数值 |
不适用 |
筛选列中值小于指定值的行。 |
|
小于或等于 |
数值 |
不适用 |
筛选列中值小于或等于指定值的行。 |
|
大于 |
数值 |
不适用 |
筛选列中值大于指定值的行。 |
|
大于或等于 |
数值 |
不适用 |
筛选列中值大于或等于指定值的行。 |
|
介于 |
数值 |
不适用 |
筛选列中值介于或等于指定的两个值的行。 |
|
包含 |
文本 |
分类 |
筛选列中值包含指定值的行。 |
|
开始于 |
文本 |
分类 |
筛选列中值开始于指定值的行。 |
|
结束于 |
分类 |
分类 |
筛选列中值结束于指定值的行。 |
设置筛选操作后, SageMaker Canvas 会更新数据集的预览以显示筛选后的数据。

函数和运算符
您可以使用数学函数和运算符来探索和分配数据。您可以使用 SageMaker Canvas 支持的函数,也可以使用现有数据创建自己的公式,然后使用公式的结果创建新列。例如,您可以将两列的相应值相加,并将结果保存到新列中。
您可以嵌套语句来创建更复杂的函数。以下是您可能使用的嵌套函数的一些示例。
-
要计算 BMI,可以使用函数
weight / (height ^ 2)。 -
要对年龄进行分类,可以使用函数
Case(age < 18, 'child', age < 65, 'adult', 'senior')。
在构建模型之前,可以在数据准备阶段指定函数。要使用函数,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “查看全部”,然后选择 “自定义公式” 以打开 “自定义公式” 面板。
-
在自定义公式面板中,您可以选择要添加到模型配方中的公式。每个公式都应用于您指定的列中的所有值。对于接受两列或更多列作为参数的公式,请使用数据类型匹配的列;否则会出错或在新列中出现
null值。 -
指定公式后,在 “新列名” 字段中添加列名。 SageMaker Canvas 将此名称用于创建的新列。
(可选)选择预览以预览您的转换结果。
-
要将函数添加到模型配方中,请选择添加。
SageMaker Canvas 使用您在新列名中指定的名称将函数的结果保存到新列中。您可以从模型配方面板中查看或删除函数。
SageMaker Canvas 支持以下函数运算符。您可以使用文本格式或内联格式来指定函数。
| 运算符 | 描述 | 支持的数据类型 | 文本格式 | 内联格式 |
|---|---|---|---|---|
|
添加 |
返回各值之和 |
数值 |
Add(sales1, sales2) |
sales1 + sales2 |
|
Subtract |
返回值之间的差值 |
数值 |
Subtract(sales1, sales2) |
sales1 ‐ sales2 |
|
Multiply |
返回值的乘积 |
数值 |
Multiply(sales1, sales2) |
sales1 * sales2 |
|
Divide |
返回值的商 |
数值 |
Divide(sales1, sales2) |
sales1 / sales2 |
|
Mod |
返回取模运算符的结果(两个值相除后的余数) |
数值 |
Mod(sales1, sales2) |
sales1 % sales2 |
|
Abs |
返回值的绝对值 |
数值 |
Abs(sales1) |
不适用 |
|
Negate |
返回值的负值 |
数值 |
Negate(c1) |
‐c1 |
|
Exp |
返回 e(欧拉数)的幂值 |
数值 |
Exp(sales1) |
不适用 |
|
Log |
返回值的对数(以 10 为底) |
数值 |
Log(sales1) |
不适用 |
|
Ln |
返回值的自然对数(以 e 为底) |
数值 |
Ln(sales1) |
不适用 |
|
Pow |
返回值的幂级数 |
数值 |
Pow(sales1, 2) |
sales1 ^ 2 |
|
If |
根据指定的条件返回 true 或 false 标签 |
布尔值、数字、文本 |
If(sales1>7000, 'truelabel, 'falselabel') |
不适用 |
|
Or |
返回一个布尔值,表示指定值或条件之一是否为真 |
布尔值 |
Or(fullprice, discount) |
fullprice || discount |
|
并且 |
返回一个布尔值,表示两个指定的值或条件是否为真 |
布尔值 |
And(sales1,sales2) |
sales1 && sales2 |
|
Not |
返回与指定值或条件相反的布尔值 |
布尔值 |
Not(sales1) |
!sales1 |
|
Case |
根据条件语句返回布尔值(如果 cond1 为真,则返回 c1,如果 cond2 为真,则返回 c2,否则返回 c3) |
布尔值、数字、文本 |
Case(cond1, c1, cond2, c2, c3) |
不适用 |
|
Equal |
返回一个布尔值,表示两个值是否相等 |
布尔值、数字、文本 |
不适用 |
c1 = c2 c1 == c2 |
|
Not equal |
返回一个布尔值,表示两个值是否不相等 |
布尔值、数字、文本 |
不适用 |
c1 != c2 |
|
Less than |
返回一个布尔值,表示 c1 是否小于 c2 |
布尔值、数字、文本 |
不适用 |
c1 < c2 |
|
Greater than |
返回一个布尔值,表示 c1 是否大于 c2 |
布尔值、数字、文本 |
不适用 |
c1 > c2 |
|
Less than or equal |
返回一个布尔值,表示 c1 是否小于或等于 c2 |
布尔值、数字、文本 |
不适用 |
c1 <= c2 |
|
Greater than or equal |
返回一个布尔值,表示 c1 是否大于或等于 c2 |
布尔值、数字、文本 |
不适用 |
c1 >= c2 |
SageMaker Canvas 还支持聚合运算符,它可以执行诸如计算所有值的总和或查找列中的最小值之类的操作。可以在函数中将聚合运算符与标准运算符结合使用。例如,要计算值与均值的差,可以使用函数Abs(height –
avg(height))。 SageMaker Canvas 支持以下聚合运算符。
| 聚合运算符 | 描述 | 格式 | 示例 |
|---|---|---|---|
|
sum |
返回列中所有值的总和 |
sum |
sum(c1) |
|
minimum |
返回列的最小值 |
min |
min(c2) |
|
maximum |
返回列的最大值 |
max |
max(c3) |
|
average |
返回列的平均值 |
avg |
avg(c4) |
|
std |
返回列的样本标准差 | std |
std(c1) |
|
stddev |
返回列中值的标准差 | stddev |
stddev(c1) |
|
variance |
返回列中值的无偏方差 |
variance |
variance(c1) |
|
approx_count_distinct |
返回列中不同项的大致数量 | approx_count_distinct |
approx_count_distinct(c1) |
|
count |
返回列中的项数 | count |
count(c1) |
|
first |
返回列的第一个值 |
first |
first(c1) |
|
last |
返回列的最后一个值 |
last |
last(c1) |
|
stddev_pop |
返回列的总体标准差 | stddev_pop |
stddev_pop(c1) |
|
variance_pop |
返回列中值的总体方差 |
variance_pop |
variance_pop(c1) |
管理行
使用“管理行”转换,可以对数据集中的数据行进行排序、随机排列以及删除数据行。
排序行
要按给定列对数据集中的行进行排序,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理行”,然后选择 “对行进行排序”。
-
在排序列中,选择要作为排序依据的列。
-
在排序顺序中,选择升序或降序。
-
选择添加将该转换添加到模型配方中。
随机排列行
要随机排列数据集中的行,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理行”,然后选择 “随机排列”。
-
选择添加将该转换添加到模型配方中。
删除重复的行
要删除数据集中的重复行,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理行”,然后选择 “删除重复行”。
-
选择添加将该转换添加到模型配方中。
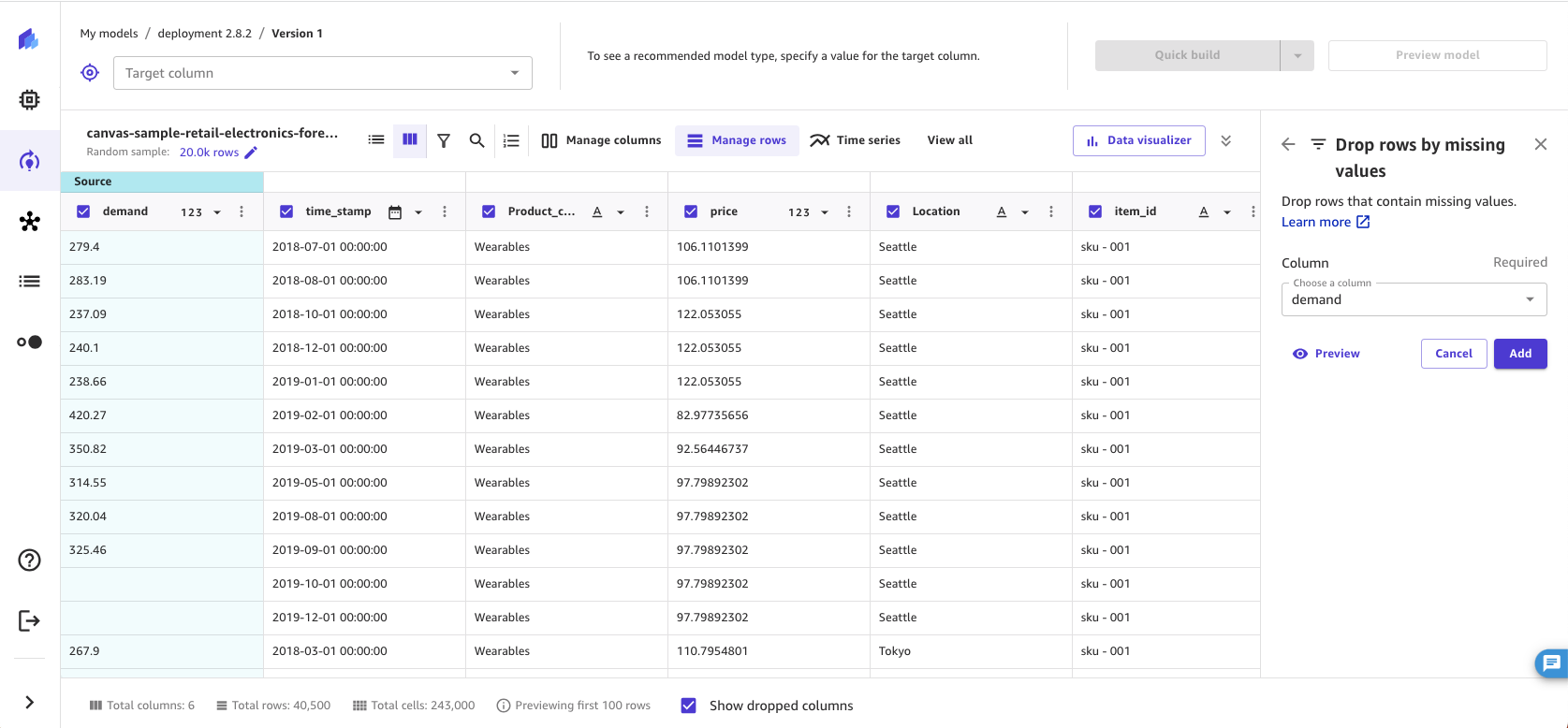
按缺失值删除行
缺失值在机器学习数据集中很常见,可能会影响模型的准确性。如果要删除某些列中为 null 值或空值的行,请使用此转换。
要删除指定列中包含缺失值的行,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理行”。
选择按缺失值删除行。
-
选择添加将该转换添加到模型配方中。
SageMaker Canvas 会删除所选列中包含缺失值的行。从数据集中移除行后, SageMaker Canvas 会在模型配方部分中添加变换。如果从模型配方部分中删除转换,则这些行将返回到您的数据集。
按异常值删除行
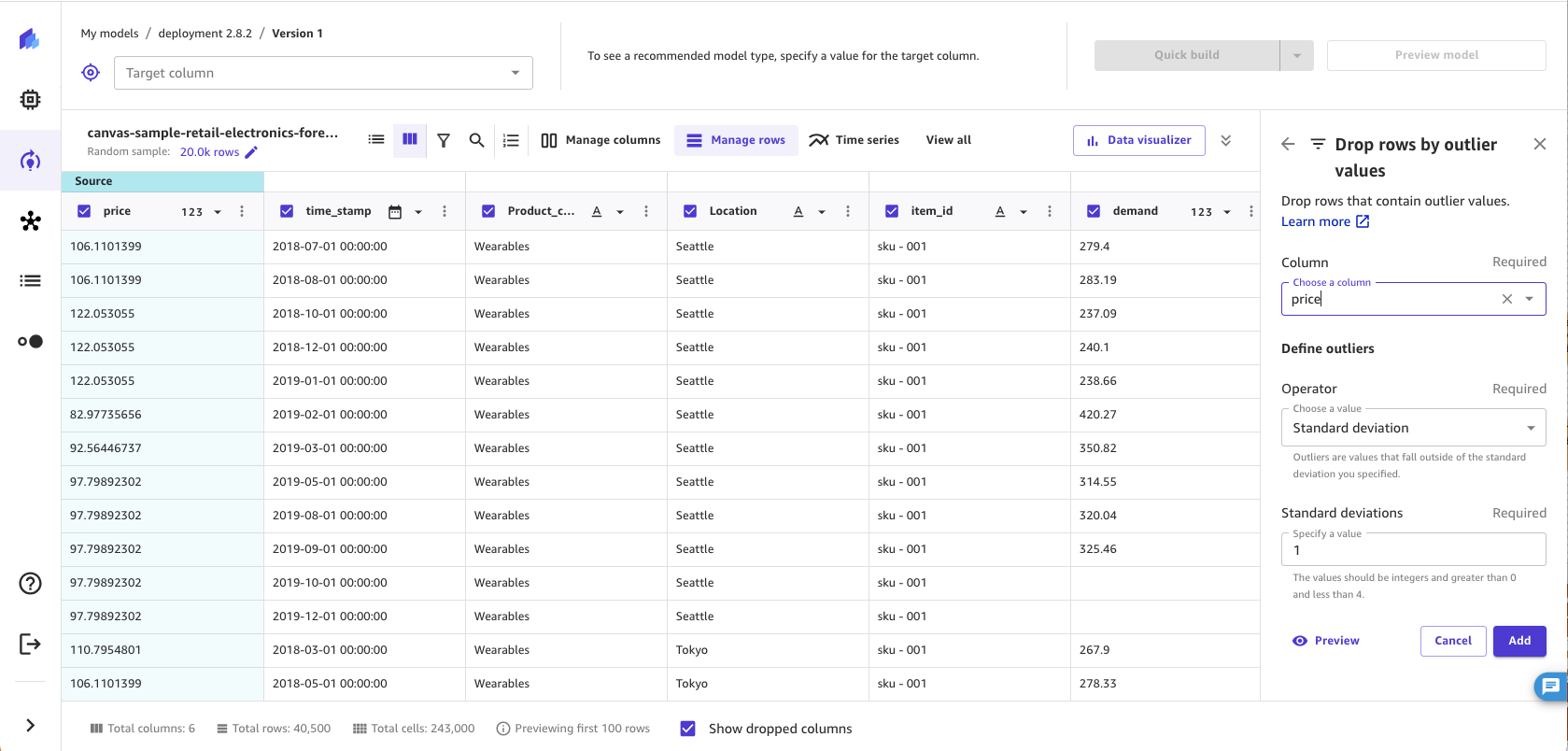
异常值或数据分布和范围中的罕见值会对模型的准确性产生负面影响,并导致构建时间延长。使用 SageMaker Canvas,您可以检测和删除数字列中包含异常值的行。您可以选择使用标准差或自定义范围来定义异常值。
要从数据中删除异常值,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理行”。
选择按异常值删除行。
-
选择要检查异常值的列。
-
将运算符设置为标准差、自定义数值范围或自定义分位数范围。
-
如果选择标准差,请指定 1–3 之间的标准差值。如果选择自定义数值范围或自定义分位数范围,请指定最小值和最大值(数值范围为数字,分位数范围为 0-100% 之间的百分位数)。
-
选择添加将该转换添加到模型配方中。
标准差选项使用平均值和标准差来检测和删除数值列中的异常值。您可以指定一个值必须与平均值相差多少个标准差才能被视为异常值。例如,如果您指定标准差为 3,那么一个值必须偏离平均值 3 个标准差以上才会被视为异常值。
自定义数值范围和自定义分位数范围选项使用最小值和最大值检测和删除数值列中的异常值。如果您知道划分异常值的阈值,请使用此方法。如果选择数值范围,则最小值和最大值应是数据中允许的最小和最大数值。如果选择分位数范围,则最小值和最大值应该是您希望允许的百分位数范围 (0–100) 的最小值和最大值。
从数据集中移除行后, SageMaker Canvas 会在模型配方部分中添加变换。如果从模型配方部分中删除转换,则这些行将返回到您的数据集。
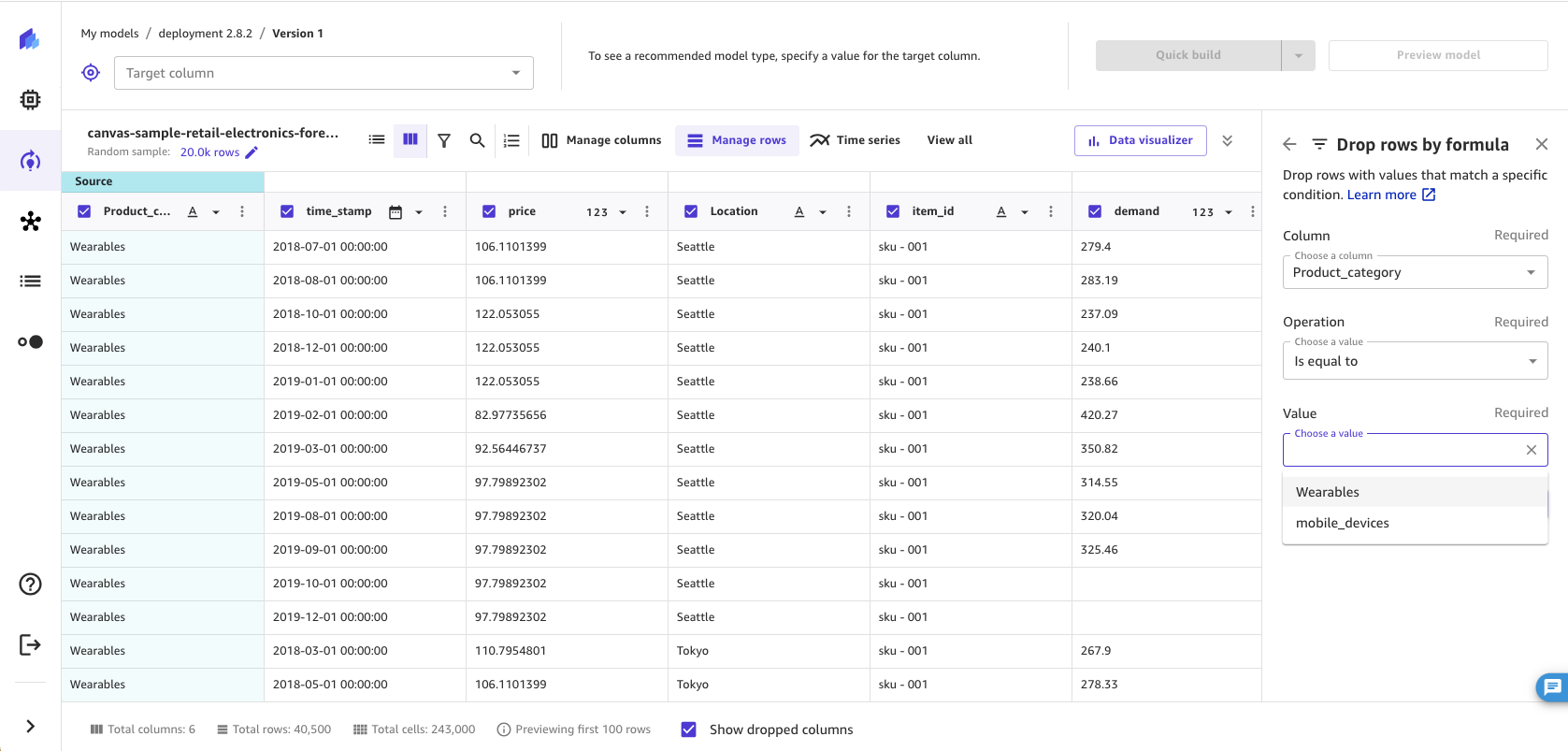
按自定义值删除行
您可以删除值符合自定义条件的行。例如,在构建模型时,您可能希望排除所有价格值大于 100 的行。通过这种转换,您可以创建一条规则,删除所有超过您设置的阈值的行。
要使用自定义删除转换,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理行”。
选择按公式删除行。
-
选择要检查的列。
-
选择要使用的操作类型,然后为所选条件指定值。
-
选择添加将该转换添加到模型配方中。
对于操作,您可以选择以下选项之一。请注意,可用的操作取决于您选择的列的数据类型。例如,您无法为包含文本值的列创建 is greater than 操作。
| 操作 | 支持的数据类型 | 支持的特征类型 | 功能 |
|---|---|---|---|
|
等于 |
数值、文本 |
二进制、分类 |
删除列中值等于指定值的行。 |
|
不等于 |
数值、文本 |
二进制、分类 |
删除列中值不等于指定值的行。 |
|
小于 |
数值 |
不适用 |
删除列中值小于指定值的行。 |
|
小于或等于 |
数值 |
不适用 |
删除列中值小于或等于指定值的行。 |
|
大于 |
数值 |
不适用 |
删除列中值大于指定值的行。 |
|
大于或等于 |
数值 |
不适用 |
删除列中值大于或等于指定值的行。 |
|
介于 |
数值 |
不适用 |
删除列中值介于或等于指定的两个值的行。 |
|
包含 |
文本 |
分类 |
删除列中值包含指定值的行。 |
|
开始于 |
文本 |
分类 |
删除列中值开始于指定值的行。 |
|
结束于 |
文本 |
分类 |
删除列中值结束于指定值的行。 |
从数据集中移除行后, SageMaker Canvas 会在模型配方部分中添加变换。如果从模型配方部分中删除转换,则这些行将返回到您的数据集。
重命名列
通过重命名列转换,您可以重命名数据中的列。当您重命名列时, SageMaker Canvas 会更改模型输入中的列名。
您可以通过双击 C SageMaker anvas 应用程序的 “构建” 选项卡中的列名称并输入新名称来重命名数据集中的列。按 Enter 键可提交更改,单击输入框外的任意位置可取消更改。您还可以单击列表视图中行末尾或网格视图中标题单元末尾的更多选项图标 (
![]() ),然后选择重命名来重命名列。
),然后选择重命名来重命名列。
列名不能超过 32 个字符,也不能有双下划线 (__),而且不能将一列重命名为与另一列相同的名称。您也不能重命名已删除的列。
以下屏幕截图显示了如何通过双击列名来重命名列。
重命名列时, SageMaker Canvas 会在模型配方部分中添加变换。如果从模型配方部分中删除转换,列就会恢复到原来的名称。
管理列
通过以下变换,您可以更改列的数据类型并替换特定列的缺失值或异常值。 SageMaker Canvas 在构建模型时使用更新的数据类型或值,但不会更改您的原始数据集。请注意,如果您使用删除列转换从数据集中删除了一列,则无法替换该列中的值。
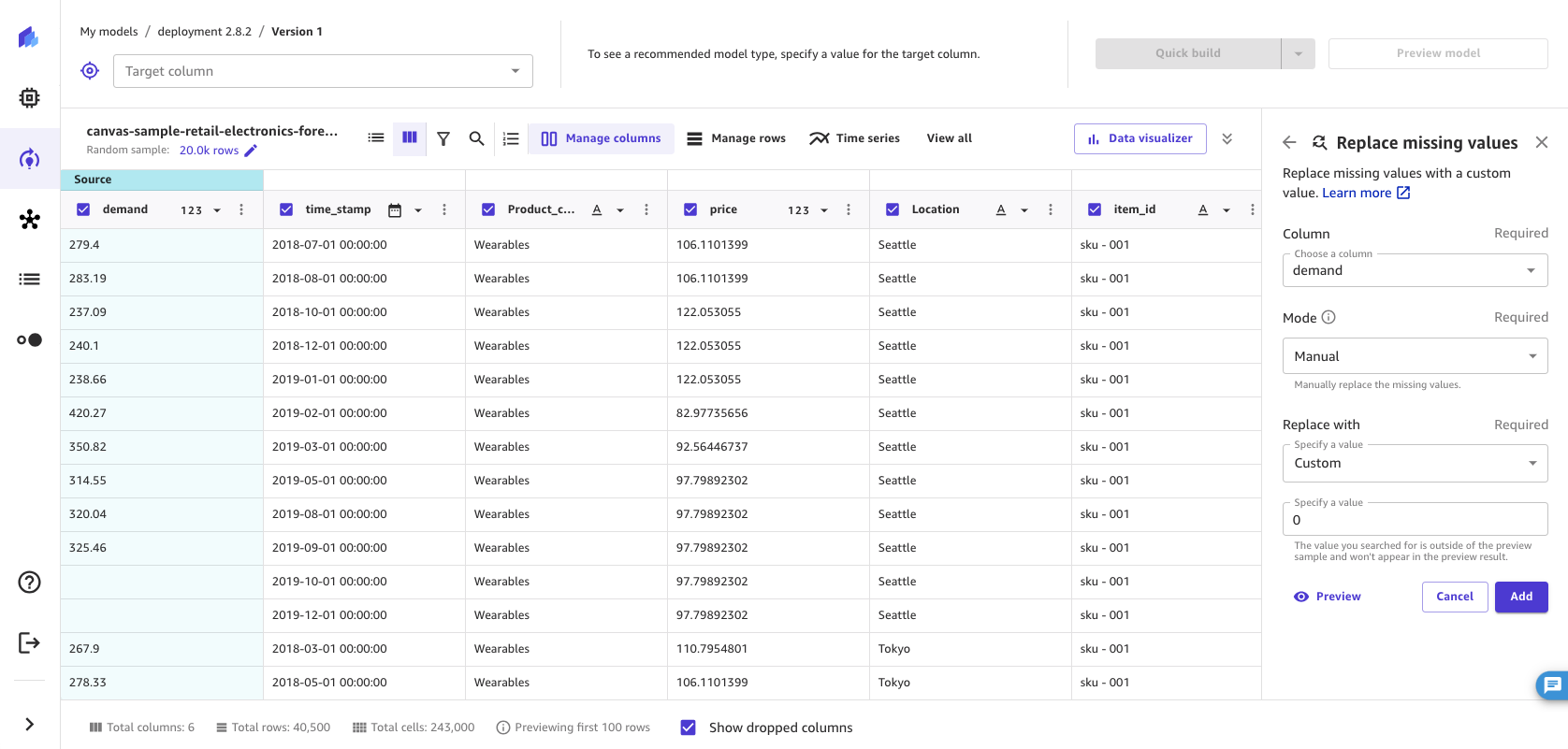
替换缺失值
缺失值在机器学习数据集中很常见,可能会影响模型的准确性。您可以选择删除具有缺失值的行,但如果您选择替换缺失值,您的模型会更准确。使用此转换,可以用列中数据的平均值或中位数替换数值列中的缺失值,也可以指定一个自定义值来替换缺失值。对于非数值列,可以用列的模式(最常用值)或自定义值替换缺失值。
如果要替换某些列中的 null 值或空值,请使用此转换。要替换指定列中的缺失值,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理列”。
选择替换缺失值。
-
选择要替换其中缺失值的列。
-
将模式设置为手动,将缺失值替换为您指定的值。在 “自动”(默认)设置中, SageMaker Canvas 会将缺失值替换为最适合您的数据的估算值。除非指定手动模式,否则每次构建模型时都会自动执行这种估算方法。
-
设置替换为值:
-
如果您的列是数值列,请选择平均值、中位数或自定义。平均值用该列的平均值替换缺失值,而中位数则用该列的中位数替换缺失值。如果选择自定义,则必须指定要用于替换缺失值的自定义值。
-
如果您的列不是数值列,请选择模式或自定义。模式将缺失值替换为列的模式或最常用值。对于自定义,指定要用来替换缺失值的自定义值。
-
-
选择添加将该转换添加到模型配方中。
替换数据集中的缺失值后, SageMaker Canvas 会在模型配方部分中添加变换。如果从模型配方部分中删除转换,则缺失值将返回到数据集中。
替换异常值
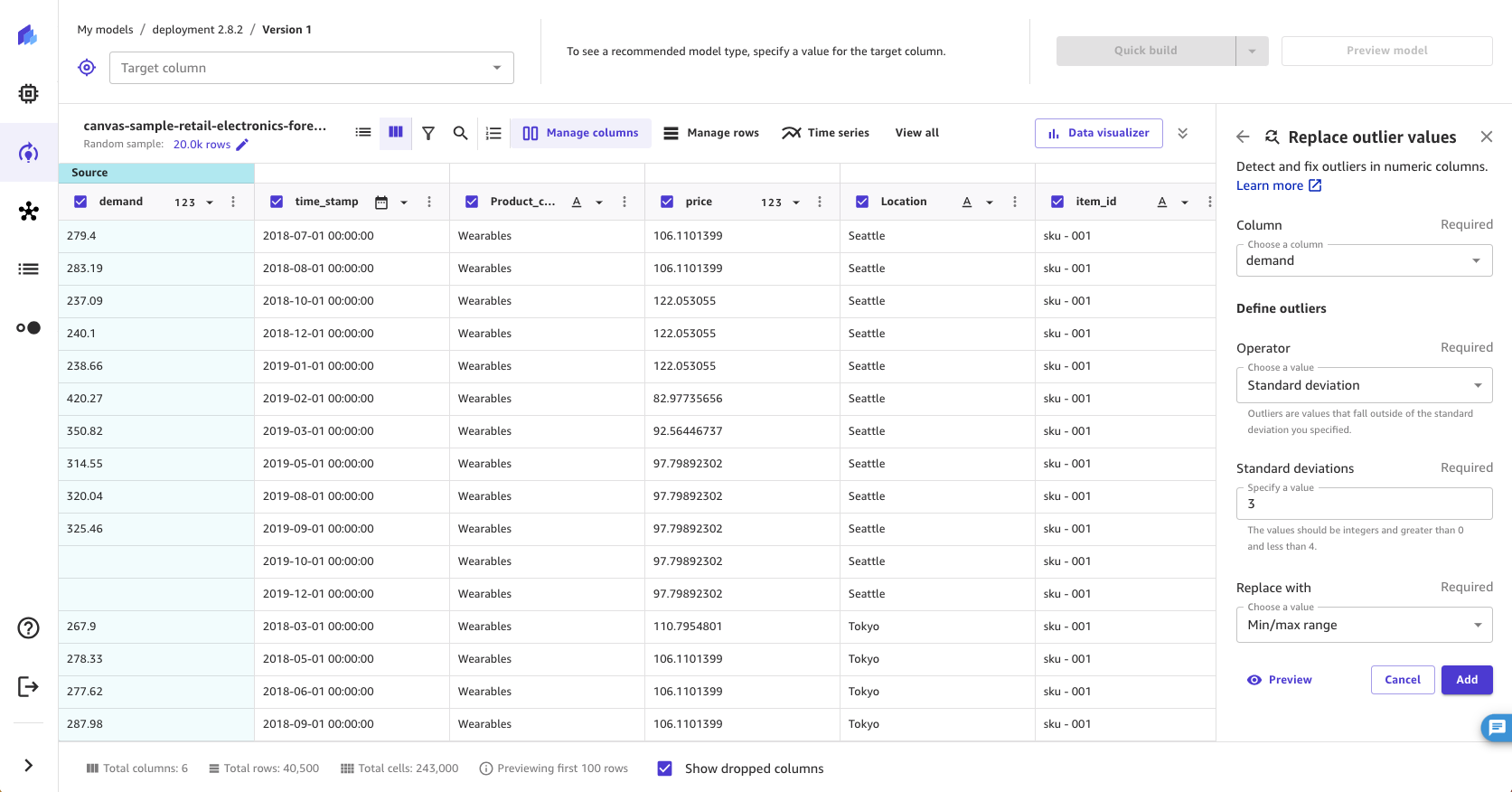
异常值或数据分布和范围中的稀有值可能会对模型精度产生负面影响,并导致更长的构建时间。 SageMaker Canvas 使您能够检测数字列中的异常值,并将异常值替换为位于数据中可接受范围内的值。您可以选择使用标准差或自定义范围来定义异常值,也可以将异常值替换为可接受范围内的最小值和最大值。
要替换数据中的异常值,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “管理列”。
选择替换异常值。
-
选择要替换其中异常值的列。
-
对于定义异常值,选择标准差、自定义数值范围或自定义分位数范围。
-
如果选择标准差,请指定 1–3 之间的标准差值。如果选择自定义数值范围或自定义分位数范围,请指定最小值和最大值(数值范围为数字,分位数范围为 0-100% 之间的百分位数)。
-
对于替换为,选择最小/最大范围。
-
选择添加将该转换添加到模型配方中。
标准差选项使用平均值和标准差来检测数值列中的异常值。您可以指定一个值必须与平均值相差多少个标准差才能被视为异常值。例如,如果您为标准差指定 3,则一个值必须与均值相差超过 3 个标准差才能被视为异常值。 SageMaker Canvas 用可接受范围内的最小值或最大值替换异常值。例如,如果您将标准差配置为仅包含 200—300 之间的值,则 SageMaker Canvas 会将值 198 更改为 200(最小值)。
自定义数值范围和自定义分位数范围选项使用最小值和最大值来检测数值列中的异常值。如果您知道划分异常值的阈值,请使用此方法。如果选择数值范围,则最小值和最大值应是您想要允许的最小和最大数值。 SageMaker Canvas 会将任何超出最小值和最大值的值替换为最小值和最大值。例如,如果您的范围仅允许 1—100 之间的值,则 SageMaker Canvas 会将值 102 更改为 100(最大值)。如果选择分位数范围,则最小值和最大值应该是您希望允许的百分位数范围 (0–100) 的最小值和最大值。
替换数据集中的值后, SageMaker Canvas 会在模型配方部分中添加变换。如果从模型配方部分中删除该转换,则原始值将返回到数据集中。
更改数据类型
SageMaker Canvas 使您能够在数字、文本和日期时间之间更改列的数据类型,同时还可以显示该数据类型的关联要素类型。数据类型是指数据的格式及其存储方式,而特征类型是指机器学习算法中使用的数据的特征,例如二进制或分类。这样,您就可以根据特征灵活地手动更改列中的数据类型。选择正确的数据类型的能力可确保在构建模型之前的数据完整性和准确性。这些数据类型用于构建模型。
注意
当前,不支持更改特征类型(例如,从二进制更改为分类)。
下表列出了 Canvas 支持的所有数据类型。
| 数据类型 | 描述 | 示例 |
|---|---|---|
数值 |
数值数据表示数值 |
1, 2, 3 1.1, 1.2。1.3 |
文本 |
文本数据表示字符序列,例如名称或描述 |
A, B, C, D apple, banana, orange 1A!, 2A!, 3A! |
日期时间 |
日期时间数据以时间戳格式表示日期和时间 |
2019-07-01 01:00:00, 2019-07-01 02:00:00, 2019-07-01 03:00:00 |
下表列出了 Canvas 支持的所有特征类型。
| 特征类型 | 描述 | 示例 |
|---|---|---|
二元 |
二元特征表示两个可能的值 |
0, 1, 0, 1, 0(2 个不同的值) true, false, true(2 个不同的值) |
分类 |
分类特征表示不同的类别或群组 |
apple, banana, orange, apple(3 个不同的值) A, B, C, D, E, A, D, C(5 个不同的值) |
要修改数据集中某列的数据类型,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,转到 “列” 视图或 “网格” 视图,然后为特定列选择数据类型下拉列表。
-
在数据类型下拉菜单中,选择要转换为的数据类型。以下屏幕截图显示了该下拉菜单。

-
对于列,选择或验证要更改其数据类型的列。
-
对于新数据类型,选择或验证要转换为的新数据类型。
-
如果新数据类型为
Datetime或Numeric,请在处理无效值下选择以下选项之一:替换为空值 – 用空值替换无效值
删除行 - 从数据集中删除具有无效值的行
替换为自定义值 - 用您指定的自定义值替换无效值。
-
选择添加将该转换添加到模型配方中。
您的列的数据类型现在应该已更新。
准备时间序列数据
使用以下功能准备时间序列数据,以构建时间序列预测模型。
重新采样时间序列数据
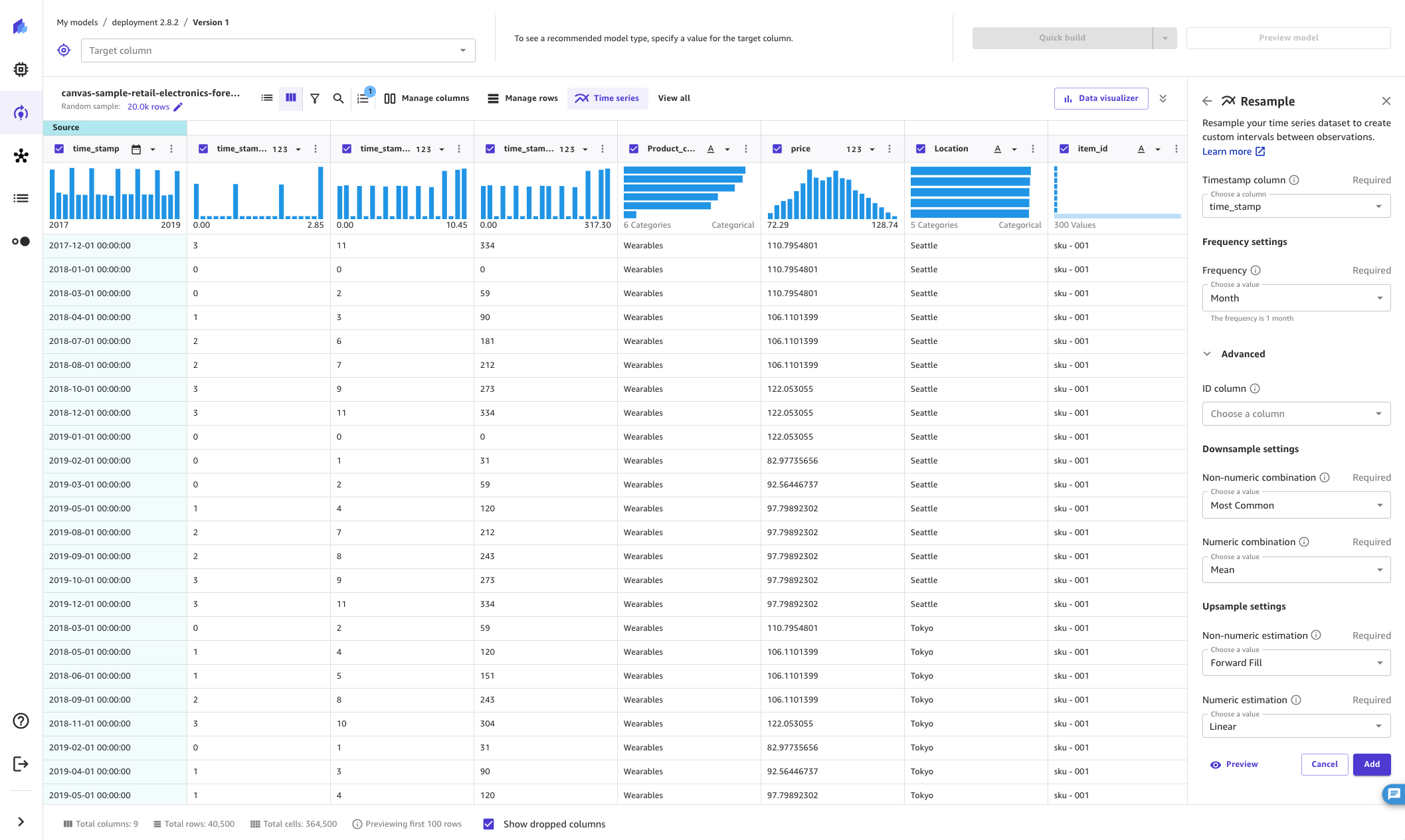
通过对时间序列数据进行重采样,您可以为时间序列数据集中的观测值建立固定的时间间隔。这在处理包含不规则间隔观测值的时间序列数据时特别有用。例如,您可以使用重采样将每隔一小时、两小时和三小时记录一次观测值的数据集转换为每隔一小时记录一次观测值的常规数据集。预测算法需要定期进行观测。
要对时间序列数据进行重新采样,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,选择 “时间序列”。
-
选择重新采样。
-
对于时间戳列,选择要对其应用转换的列。您只能选择日期时间类型的列。
-
在频率设置部分,选择频率和速率。频率是指频率单位,速率是指应用于列的频率单位的间隔。例如,如果为频率值选择
Calendar Day并为速率选择1,则会将间隔设置为每 1 个日历日增加一次,例如2023-03-26 00:00:00、2023-03-27 00:00:00、2023-03-28 00:00:00。有关频率值的完整列表,请参阅此过程后的表格。 -
选择添加将该转换添加到模型配方中。
下表列出了在对时间序列数据进行重采样时可以选择的所有频率类型。
| 频率 | 描述 | 示例值(假设速率为 1) |
|---|---|---|
|
工作日 |
将日期时间列中的观测值重采样为一周中的 5 个工作日(星期一、星期二、星期三、星期四、星期五) |
2023-03-24 00:00:00 2023-03-27 00:00:00 2023-03-28 00:00:00 2023-03-29 00:00:00 2023-03-30 00:00:00 2023-03-31 00:00:00 2023-04-03 00:00:00 |
|
日历日 |
将日期时间列中的观测值重采样为一周中的所有 7 天(星期一、星期二、星期三、星期四、星期五、星期六、星期日) |
2023-03-26 00:00:00 2023-03-27 00:00:00 2023-03-28 00:00:00 2023-03-29 00:00:00 2023-03-30 00:00:00 2023-03-31 00:00:00 2023-04-01 00:00:00 |
|
周 |
将日期时间列中的观测值重采样为每周的第一天 |
2023-03-13 00:00:00 2023-03-20 00:00:00 2023-03-27 00:00:00 2023-04-03 00:00:00 |
|
月 |
将日期时间列中的观测值重采样为每个月的第一天 |
2023-03-01 00:00:00 2023-04-01 00:00:00 2023-05-01 00:00:00 2023-06-01 00:00:00 |
|
年度季度 |
将日期时间列中的观测值重采样为每个季度的最后一天 |
2023-03-31 00:00:00 2023-06-30 00:00:00 2023-09-30 00:00:00 2023-12-31 00:00:00 |
|
Year |
将日期时间列中的观测值重采样为每年的最后一天 |
2022-12-31 0:00:00 2023-12-31 00:00:00 2024-12-31 00:00:00 |
|
小时 |
将日期时间列中的观测值重采样为每天的每个小时 |
2023-03-24 00:00:00 2023-03-24 01:00:00 2023-03-24 02:00:00 2023-03-24 03:00:00 |
|
分钟 |
将日期时间列中的观测值重采样为每小时的每一分钟 |
2023-03-24 00:00:00 2023-03-24 00:01:00 2023-03-24 00:02:00 2023-03-24 00:03:00 |
|
秒 |
将日期时间列中的观测值重采样为每分钟的每一秒 |
2023-03-24 00:00:00 2023-03-24 00:00:01 2023-03-24 00:00:02 2023-03-24 00:00:03 |
应用重采样转换时,可以使用高级选项来指定如何修改数据集中其余列(时间戳列除外)的结果值。这可以通过指定重采样方法来实现,对于数值列和非数值列,重采样方法可以是下采样或上采样。
下采样会延长数据集中观测值之间的间隔。例如,如果对每小时或每两小时记录的观测值进行下采样,那么数据集中的每个观测值将每两小时记录一次。使用组合方法将每小时观测值中其他列的值聚合为单个值。下表显示了使用均值作为组合方法对时间序列数据进行下采样的示例。数据采样从每两小时一次降到每小时一次。
下表显示了下采样之前一天内每小时的温度读数。
| Timestamp | 温度(摄氏度) |
|---|---|
12:00 pm |
30 |
1:00 am |
32 |
2:00 am |
35 |
3:00 am |
32 |
4:00 am |
30 |
下表显示了下采样至每两小时一次后的温度读数。
| Timestamp | 温度(摄氏度) |
|---|---|
12:00 pm |
30 |
2:00 am |
33.5 |
2:00 am |
35 |
4:00 am |
32.5 |
要对时间序列数据进行下采样,请执行以下操作:
-
展开重采样转换下的高级部分。
-
选择非数值组合以指定非数值列的组合方法。有关组合方法的完整列表,请参阅下表。
-
选择数值组合以指定数值列的组合方法。有关组合方法的完整列表,请参阅下表。
如果未指定组合方法,则非数值组合的默认值为Most Common,数值组合的默认值为Mean。下表列出了数值和非数值组合的方法。
| 下采样方法 | 组合方法 | 描述 |
|---|---|---|
非数值组合 |
最常用 |
按最常用值聚合非数值列中的值 |
非数值组合 |
最后一个 |
按非数值列中的最后一个值聚合该列中的值 |
非数值组合 |
第一个 |
按非数值列中的第一个值聚合该列中的值 |
数值组合 |
平均值 |
通过取数值列中所有值的平均值来聚合该列中的值 |
数值组合 |
中位数 |
通过取数值列中所有值的中位数来聚合该列中的值 |
数值组合 |
最小值 |
通过取数值列中所有值的最小值来聚合该列中的值 |
数值组合 |
最大值 |
通过取数值列中所有值的最大值来聚合该列中的值 |
数值组合 |
总和 |
通过将数值列中的所有值相加来聚合该列中的值 |
数值组合 |
分位数 |
通过取数值列中所有值的分位数来聚合该列中的值 |
上采样会缩短数据集中观测值之间的间隔。例如,如果您将每两小时采集的观测值上采样为每小时观测值,则每小时观测值中其他列的值将从每两小时采集的观测值中插值而来。
要对时间序列数据进行上采样,请执行以下操作:
-
展开重采样转换下的高级部分。
-
选择非数值估算以指定非数值列的估算方法。有关方法的完整列表,请参阅此过程之后的表格。
-
选择数值估算以指定数值列的估算方法。有关方法的完整列表,请参阅下表。
-
(可选)选择 ID 列以指定包含时间序列观测值的列。 IDs如果您的数据集有两个时间序列,请指定此选项。如果您有一列仅代表一个时间序列,请不要为此字段指定值。例如,您可以有一个包含列
id和purchase的数据集。id列具有以下值:[1, 2, 2, 1]。purchase列具有以下值:[$2, $3, $4, $1]。因此,数据集有两个时间序列,一个时间序列是1: [$2, $1],另一个时间序列是2: [$3, $4]。
如果未指定估算方法,则非数值估算的默认值为 Forward Fill,数值估算的默认值为 Linear。下表列出了各种估算方法。
| 上采样方法 | 估算方法 | 描述 |
|---|---|---|
非数值估算 |
前向填充 |
通过在非数值列中的所有值之后取连续值来插入该列中的值 |
非数值估算 |
后向填充 |
通过在非数值列中的所有值之前取连续值来插入该列中的值 |
非数值估算 |
保持缺失 |
通过显示空值来插入非数值列中的值 |
数值估算 |
Linear、Time、Index、Zero、S-Linear、Nearest、Quadratic、Cubic、Barycentric、Polynomial、Krogh、Piecewise Polynomial、Spline、P-chip、Akima、Cubic Spline、From Derivatives |
使用指定的插值器来插入数值列中的值。有关插值方法的信息,请参阅 pandas。 DataFrame.interpolate |
以下屏幕截图显示了高级设置,其中填写了下采样和上采样字段。
使用日期时间提取
使用日期时间提取转换,您可以将日期时间列中的值提取到单独的列。例如,如果您有一列包含购买日期,则可以将月份值提取到单独的列中,并在构建模型时使用新列。您还可以通过一次转换将多个值提取到不同的列中。
日期时间列必须使用支持的时间戳格式。有关 C SageMaker anvas 支持的格式列表,请参阅Amazon C SageMaker anvas 中的时间序列预测。如果您的数据集未使用任何支持的格式,请更新您的数据集以使用支持的时间戳格式,并在构建模型之前将其重新导入到 Amazon SageMaker Canvas。
要执行日期时间提取,请执行以下操作。
-
在 SageMaker Canvas 应用程序的 “构建” 选项卡中,在变换栏上,选择 “查看全部”。
选择提取特征。
-
选择要从中提取值的时间戳列。
-
在值中,选择一个或多个要从列中提取的值。您可以从时间戳列中提取的值包括年、月、日、小时、一年中的一周、一年中的一天和季度。
(可选)选择预览以预览转换结果。
-
选择添加将该转换添加到模型配方中。
SageMaker Canvas 会在数据集中为您提取的每个值创建一个新列。除年份值外, SageMaker Canvas 对提取的值使用基于 0 的编码。例如,如果提取月值,则一月份提取为 0,二月份提取为 1。
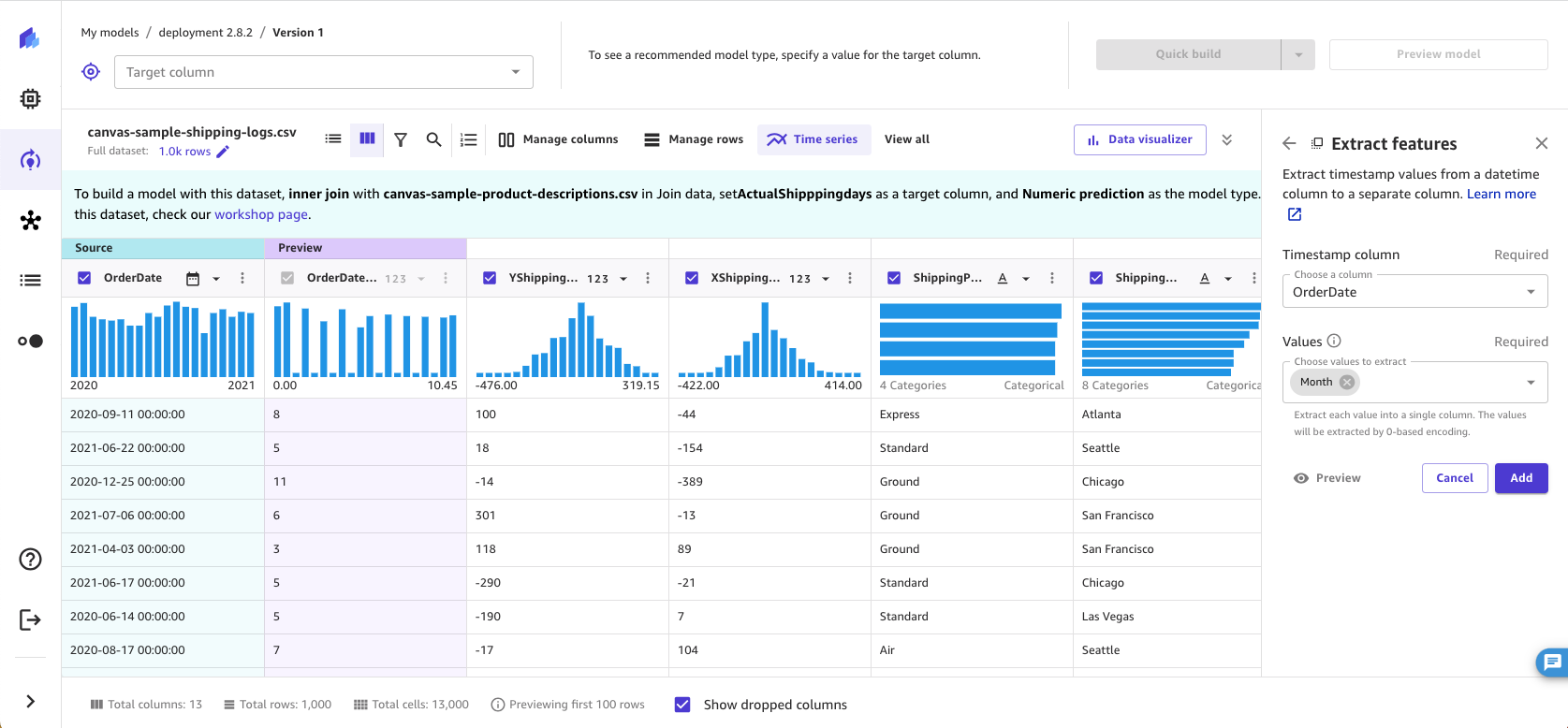
您可以看到在模型配方部分中列出了该转换。如果从模型配方部分中删除该转换,则会从数据集中删除新列。
