本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
C SageMaker larify 处理作业完成后,您可以下载输出文件进行检查,也可以在 SageMaker Studio Classic 中对结果进行可视化。以下主题介绍了 Clarify 生成的分析结果,例如由偏差分析、SHAP 分析、计算机视觉可解释性分析和部分依赖图 () PDPs 分析生成的架构和报告。 SageMaker 如果配置分析包含用于计算多个分析的参数,则结果将聚合到一个分析和一个报告文件中。
C SageMaker larify 处理作业输出目录包含以下文件:
-
analysis.json- 一个文件,其中包含 JSON 格式的偏差指标和特征重要性。 -
report.ipynb- 一个静态笔记本,其中包含有助于可视化偏差指标和特征重要性的代码。 -
explanations_shap/out.csv- 根据您的特定分析配置创建的目录,其中包含自动生成的文件。例如,如果激活save_local_shap_values参数,则每个实例的局部 SHAP 值将保存到explanations_shap目录。再举一个例子,如果您analysis configuration不包含 SHAP 基线参数的值,Clarify 可解释性作业将 SageMaker 通过对输入数据集进行聚类来计算基线。然后,它会将生成的基准保存到该目录。
有关更多详细信息,请参阅以下章节。
偏差分析
Amaz SageMaker on Clarify 使用中记录的术语Amazon SageMaker 澄清偏见和公平条款来讨论偏见和公平性。
分析文件的架构
分析文件采用 JSON 格式,分为两部分:训练前偏差指标和训练后偏差指标。训练前和训练后偏差指标的参数如下。
-
pre_training_bias_metrics - 训练前偏差指标的参数。有关更多信息,请参阅训练前偏差指标和分析配置文件。
-
label - 由分析配置的
label参数定义的 Ground Truth 标签名称。 -
label_value_or_threshold - 一个字符串,其中包含由分析配置的
label_values_or_threshold参数定义的标签值或间隔。例如,如果为二进制分类问题提供了值1,则字符串将是1。如果为多类问题提供了多个值[1,2],则字符串将是1,2。如果为回归问题提供了阈值40,则字符串将是内部字符串,比如(40, 68],其中68是输入数据集中标签的最大值。 -
facets - 该部分包含多个键值对,其中键对应于分面配置的
name_or_index参数定义的分面名称,值是分面对象数组。每个分面对象都具有以下成员:-
value_or_threshold - 一个字符串,其中包含由分面配置的
value_or_threshold参数定义的分面值或区间。 -
metrics - 该部分包含偏差指标元素数组,每个偏差指标元素都具有以下属性:
-
name - 偏差指标的简称。例如,
CI。 -
description - 偏差指标的全名。例如,
Class Imbalance (CI)。 -
value - 偏差指标值,如果出于特定原因未计算偏差指标,则为 JSON null 值。值 ±∞ 分别表示为字符串
∞和-∞。 -
error - 一条可选的错误消息,解释了未计算偏差指标的原因。
-
-
-
-
post_training_bias_metrics - 该部分包含训练后偏差指标,其布局和结构与训练前部分类似。有关更多信息,请参阅 训练后数据和模型偏差指标。
以下是将计算训练前和训练后偏差指标的分析配置示例。
{
"version": "1.0",
"pre_training_bias_metrics": {
"label": "Target",
"label_value_or_threshold": "1",
"facets": {
"Gender": [{
"value_or_threshold": "0",
"metrics": [
{
"name": "CDDL",
"description": "Conditional Demographic Disparity in Labels (CDDL)",
"value": -0.06
},
{
"name": "CI",
"description": "Class Imbalance (CI)",
"value": 0.6
},
...
]
}]
}
},
"post_training_bias_metrics": {
"label": "Target",
"label_value_or_threshold": "1",
"facets": {
"Gender": [{
"value_or_threshold": "0",
"metrics": [
{
"name": "AD",
"description": "Accuracy Difference (AD)",
"value": -0.13
},
{
"name": "CDDPL",
"description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)",
"value": 0.04
},
...
]
}]
}
}
}偏差分析报告
偏差分析报告包括几个表格和图表,其中包含详细的解释和描述。这包括但不限于标签值分布、分面值分布、高级模型性能图、偏差指标表及其描述。有关偏见指标及其解释方法的更多信息,请参阅了解 Amazon Clarify SageMaker 如何帮助检测偏见
SHAP 分析
SageMaker 澄清处理作业使用内核 SHAP 算法来计算特征归因。Cl SageMaker arify 处理任务会生成本地和全局 SHAP 值。它们有助于确定每项特征对模型预测的贡献。局部 SHAP 值表示每个实例的特征重要性,而全局 SHAP 值则聚合数据集中所有实例的局部 SHAP 值。有关 SHAP 值及其解析方法的更多信息,请参阅使用 Shapley 值的特征归因。
SHAP 分析文件的架构
全局 SHAP 分析结果存储在分析文件的解释部分,置于 kernel_shap 方法之下。SHAP 分析文件的不同参数如下所示:
-
explanations - 分析文件中包含特征重要性分析结果的部分。
-
kernal_shap - 分析文件中包含全局 SHAP 分析结果的部分。
-
global_shap_values - 分析文件中包含多个键值对的部分。键值对中的每个键都代表输入数据集中的一个特征名称。键值对中的每个值都对应于该特征的全局 SHAP 值。全局 SHAP 值是通过使用
agg_method配置聚合特征的每个实例 SHAP 值来获得的。如果use_logit配置激活,则使用逻辑回归系数计算该值,这些系数可以解释为对数几率比。 -
expected_value - 基准数据集的平均预测值。如果
use_logit配置激活,则使用逻辑回归系数计算该值。 -
global_top_shap_text:用于 NLP 可解释性分析。分析文件中包含一组键值对的部分。 SageMaker 澄清处理任务汇总每个令牌的 SHAP 值,然后根据其全局 SHAP 值选择排名靠前的代币。
max_top_tokens配置定义了要选择的令牌数量。每个选定的主要令牌都有一个键值对。键值对中的键对应于主要令牌的文本特征名称。键值对中的每个值都是主要令牌的全局 SHAP 值。有关
global_top_shap_text键值对的示例,请参阅以下输出。
-
-
下面的示例显示了 SHAP 分析表格数据集的输出结果。
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"Target": {
"global_shap_values": {
"Age": 0.022486410860333206,
"Gender": 0.007381025261958729,
"Income": 0.006843906804137847,
"Occupation": 0.006843906804137847,
...
},
"expected_value": 0.508233428001
}
}
}
}下面的示例显示了 SHAP 分析文本数据集的输出结果。与 Comments 列对应的输出是在分析文本特征后生成的输出示例。
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"Target": {
"global_shap_values": {
"Rating": 0.022486410860333206,
"Comments": 0.058612104851485144,
...
},
"expected_value": 0.46700941970297033,
"global_top_shap_text": {
"charming": 0.04127962903247833,
"brilliant": 0.02450240786522321,
"enjoyable": 0.024093569652715457,
...
}
}
}
}
}生成的基准文件的架构
如果未提供 SHAP 基线配置,则 Clarif SageMaker y 处理作业会生成基线数据集。 SageMaker Clarify 使用基于距离的聚类算法,根据输入数据集创建的聚类生成基线数据集。生成的基准数据集保存在 CSV 文件中,位于 explanations_shap/baseline.csv。此输出文件包含一个标题行和几个实例,这些实例基于分析配置中指定的 num_clusters 参数。基准数据集仅包含特征列。下面的示例显示了通过对输入数据集进行集群而创建的基线。
Age,Gender,Income,Occupation
35,0,2883,1
40,1,6178,2
42,0,4621,0表格数据集可解释性分析中局部 SHAP 值的架构
对于表格数据集,如果使用单个计算实例,Clarify 处理作业会将本地 SHAP 值保存到名为的 CSV 文件中。 SageMaker explanations_shap/out.csv如果使用多个计算实例,则局部 SHAP 值将保存到 explanations_shap 目录中的多个 CSV 文件。
包含局部 SHAP 值的输出文件中有一行包含标题定义的每列的局部 SHAP 值。标题遵循 Feature_Label 命名约定,即特征名称后面加下划线,后跟目标变量的名称。
对于多类问题,标题中的特征名称会先变化,然后是标签。例如,有两项特征 F1, F2 和两个类 L1 和 L2,那么在标题中显示为 F1_L1、F2_L1、F1_L2 和 F2_L2。如果分析配置包含 joinsource_name_or_index 参数的值,则联接中使用的键列将附加到标题名称的末尾。这允许将局部 SHAP 值映射到输入数据集的实例。以下是包含 SHAP 值的输出文件的示例。
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
NLP 可解释性分析中局部 SHAP 值的架构
对于 NLP 可解释性分析,如果使用单个计算实例,Clarify 处理任务会将本 SageMaker 地 SHAP 值保存到名为的 JSON Lines 文件中。explanations_shap/out.jsonl如果使用多个计算实例,则局部 SHAP 值将保存到 explanations_shap 目录中的多个 JSON 行文件。
每个包含局部 SHAP 值的文件都有几行数据,每行都是一个有效的 JSON 对象。JSON 对象具有以下属性:
-
explanations - 分析文件中包含单个实例 Kernel SHAP 解释数组的部分。数组中的每个元素都具有以下成员:
-
feature_name - 标题配置提供的特征的标题名称。
-
data_type — Clarify 处理作业推断出的要素类型 SageMaker 。文本特征的有效值包括
numerical、categorical和free_text(适用于文本特征)。 -
attributions - 特定于特征的归因对象数组。一个文本特征可以有多个归因对象,每个对象对应一个由
granularity配置定义的单元。归因对象具有以下成员:-
attribution - 特定于类的概率值数组。
-
description -(适用于文本特征)文本单元的描述。
-
p@@ artial_text — 由 SageMaker 澄清处理任务解释的文本部分。
-
start_idx - 一个零基索引,用于标识表示部分文本片段开头的数组位置。
-
-
-
以下是局部 SHAP 值文件中单行的示例,为提高可读性而进行了美化。
{
"explanations": [
{
"feature_name": "Rating",
"data_type": "categorical",
"attributions": [
{
"attribution": [0.00342270632248735]
}
]
},
{
"feature_name": "Comments",
"data_type": "free_text",
"attributions": [
{
"attribution": [0.005260534499999983],
"description": {
"partial_text": "It's",
"start_idx": 0
}
},
{
"attribution": [0.00424190349999996],
"description": {
"partial_text": "a",
"start_idx": 5
}
},
{
"attribution": [0.010247314500000014],
"description": {
"partial_text": "good",
"start_idx": 6
}
},
{
"attribution": [0.006148907500000005],
"description": {
"partial_text": "product",
"start_idx": 10
}
}
]
}
]
}SHAP 分析报告
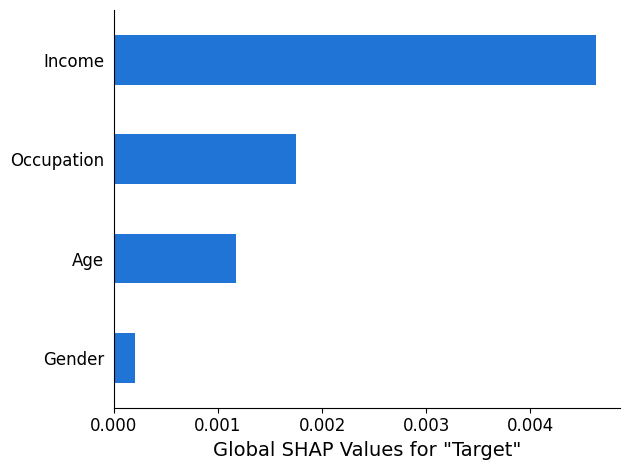
SHAP 分析报告提供了一张条形图,图中最多有 10 个主要全局 SHAP 值。以下图表示例显示了 4 项主要特征的 SHAP 值。
计算机视觉 (CV) 可解释性分析
SageMaker Clarity 计算机视觉可解释性采用由图像组成的数据集,并将每张图像视为超级像素的集合。分析后,Cl SageMaker arify 处理作业会输出一个图像数据集,其中每张图像都显示超级像素的热图。
以下示例在左侧显示了输入限速标志,右侧的热图显示了 SHAP 值的大小。这些 SHAP 值是通过图像识别 Resnet-18 模型计算得出,该模型经过训练可以识别德国交通标志

有关更多信息,请参阅 “使用 Clarify 解释图片分类” 和 “使用 SageMaker
部分依赖图 (PDPs) 分析
部分依赖图显示预测的目标响应对一组相关输入特征的依赖性。这些特征在所有其他输入特征值的基础上进行边缘化,被称为补充特征。直观地说,您可以将部分依赖性解释为目标响应,它是每个相关输入特征的预期函数。
分析文件的架构
PDP 值存储在分析文件 explanations 部分的 pdp 方法下。explanations 的参数设置如下所示:
-
explanations - 分析文件中包含特征重要性分析结果的部分。
-
pdp - 分析文件中包含单个实例的 PDP 解释数组的部分。数组的每个元素都具有以下成员:
-
feature_name -
headers配置提供的特征的标题名称。 -
data_type — Clarify 处理作业推断出的要素类型 SageMaker 。
data_type的有效值包括数值和分类。 -
feature_values - 包含特征中存在的值。如果 Clarif SageMaker y 的
data_type推断是分类的,则feature_values包含该特征可能具有的所有唯一值。如果 Clarifydata_typeSageMaker 推断的值是数值,则feature_values包含生成的存储桶的中心值列表。grid_resolution参数确定用于对特征列值进行分组的存储桶数量。 -
data_distribution - 百分比数组,其中每个值都是存储桶所包含的实例的百分比。
grid_resolution参数决定了存储桶数量。特征列值分组到这些存储桶中。 -
model_predictions - 模型预测数组,其中数组的每个元素都是一个预测数组,对应于模型输出中的一个类。
label_headers -
label_headers配置提供的标签标题。 -
error - 如果由于特定原因未计算 PDP 值,则会生成一条错误消息。此错误消息替换
feature_values、data_distributions和model_predictions字段中包含的内容。
-
-
以下是包含 PDP 分析结果的分析文件的输出示例。
{
"version": "1.0",
"explanations": {
"pdp": [
{
"feature_name": "Income",
"data_type": "numerical",
"feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1],
"data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01],
"model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]],
"label_headers": ["Target"]
},
...
]
}
}PDP 分析报告
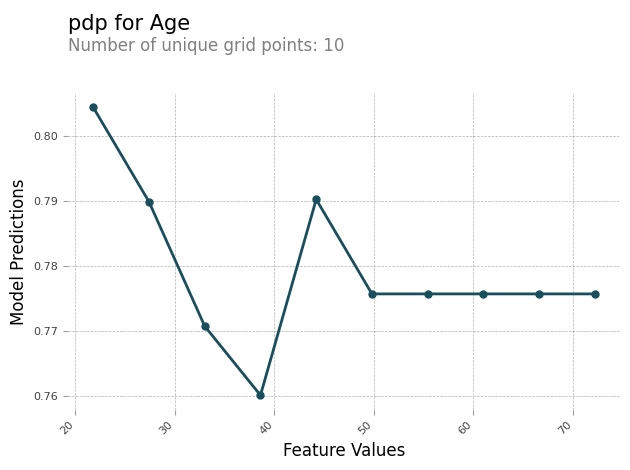
您可以生成包含每项特征的 PDP 图表的分析报告。PDP 图表沿 x 轴绘制 feature_values,沿 y 轴绘制 model_predictions。对于多类模型,model_predictions 是一个数组,该数组的每个元素都对应于一个模型预测类。
以下是特征 Age 的 PDP 图表示例。在示例输出中,PDP 显示了分组到存储桶中的特征值的数量。存储桶的数量由 grid_resolution 决定。根据模型预测绘制特征值存储桶。在本例中,较高的特征值具有相同的模型预测值。
非对称 Shapley 值
SageMaker 澄清处理作业使用非对称 Shapley 值算法来计算时间序列预测模型解释属性。该算法可确定每个时间步长的输入功能对预测结果的贡献。
非对称 Shapley 值分析文件的模式
非对称 Shapley 值结果存储在 Amazon S3 存储桶中。您可以在分析文件的解释部分找到该存储桶的位置。本节包含功能重要性分析结果。非对称 Shapley 值分析文件中包含以下参数。
asymmetric_shapley_value:分析文件中包含解释作业结果元数据的部分,包括以下内容:
explanation_results_path:含有解释结果的 Amazon S3 位置
方向:用户为
direction的配置值提供的配置粒度:用户为
granularity的配置值提供的配置。
下面的代码段显示了分析文件示例中前面提到的参数:
{
"version": "1.0",
"explanations": {
"asymmetric_shapley_value": {
"explanation_results_path": EXPLANATION_RESULTS_S3_URI,
"direction": "chronological",
"granularity": "timewise",
}
}
}下文将介绍解释结果结构如何取决于配置中的 granularity 值。
时间粒度
当粒度为 timewise 时,输出将以如下结构表示。scores 值表示每个时间戳的归属。offset 值代表模型对基线数据的预测,描述了模型在没有接收到数据时的行为。
下面的代码段显示了一个模型的输出示例,该模型对两个时间步长进行预测。因此,所有归因都是由两个元素组成的列表,其中第一个元素指的是第一个预测时间步长。
{
"item_id": "item1",
"offset": [1.0, 1.2],
"explanations": [
{"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]},
{"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]},
{"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]},
]
}
{
"item_id": "item2",
"offset": [1.0, 1.2],
"explanations": [
{"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]},
{"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]},
{"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]},
]
}精细
下面的示例演示了粒度为 fine_grained 时的归因结果。offset 值的含义与上一节所述相同。对目标时间序列和相关时间序列(如果有)的每个时间戳的每个输入功能,以及每个静态协变量(如果有),都要计算归因。
{
"item_id": "item1",
"offset": [1.0, 1.2],
"explanations": [
{"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]},
{"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]},
{"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]},
{"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "static_covariate_1", "scores": [0.6, 0.1]},
{"feature_name": "static_covariate_2", "scores": [0.1, 0.3]},
]
}对于 timewise 和 fine-grained 使用场景,结果均以 JSON Lines (.jsonl) 格式存储。
