本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建 Multi-Model 终端节点
您可以使用 SageMaker AI 控制台或创建多模型终端节点。 AWS SDK for Python (Boto) 要通过控制台创建 CPU 或 GPU 支持的端点,请参阅以下各部分中的控制台过程。如果要使用创建多模型终端节点 AWS SDK for Python (Boto),请使用以下各节中的 CPU 或 GPU 过程。CPU 和 GPU 工作流相似但有一些区别,例如容器要求。
主题
创建多模型端点(控制台)
您可以通过控制台创建 CPU 和 GPU 支持的多模型端点。使用以下步骤通过 SageMaker AI 控制台创建多模型终端节点。
创建多模型端点(控制台)
-
打开 Amazon A SageMaker I 控制台,网址为https://console.aws.amazon.com/sagemaker/
。 -
选择 Models (模型),然后从 Inference (推理) 组选择 Create models (创建模型)。
-
对于 Model name (模型名称),输入一个名称。
-
对于 IAM 角色,选择或创建附加
AmazonSageMakerFullAccessIAM 策略的 IAM 角色。 -
在容器定义部分中,为提供模型构件和推理映像选项选择使用多个模型。
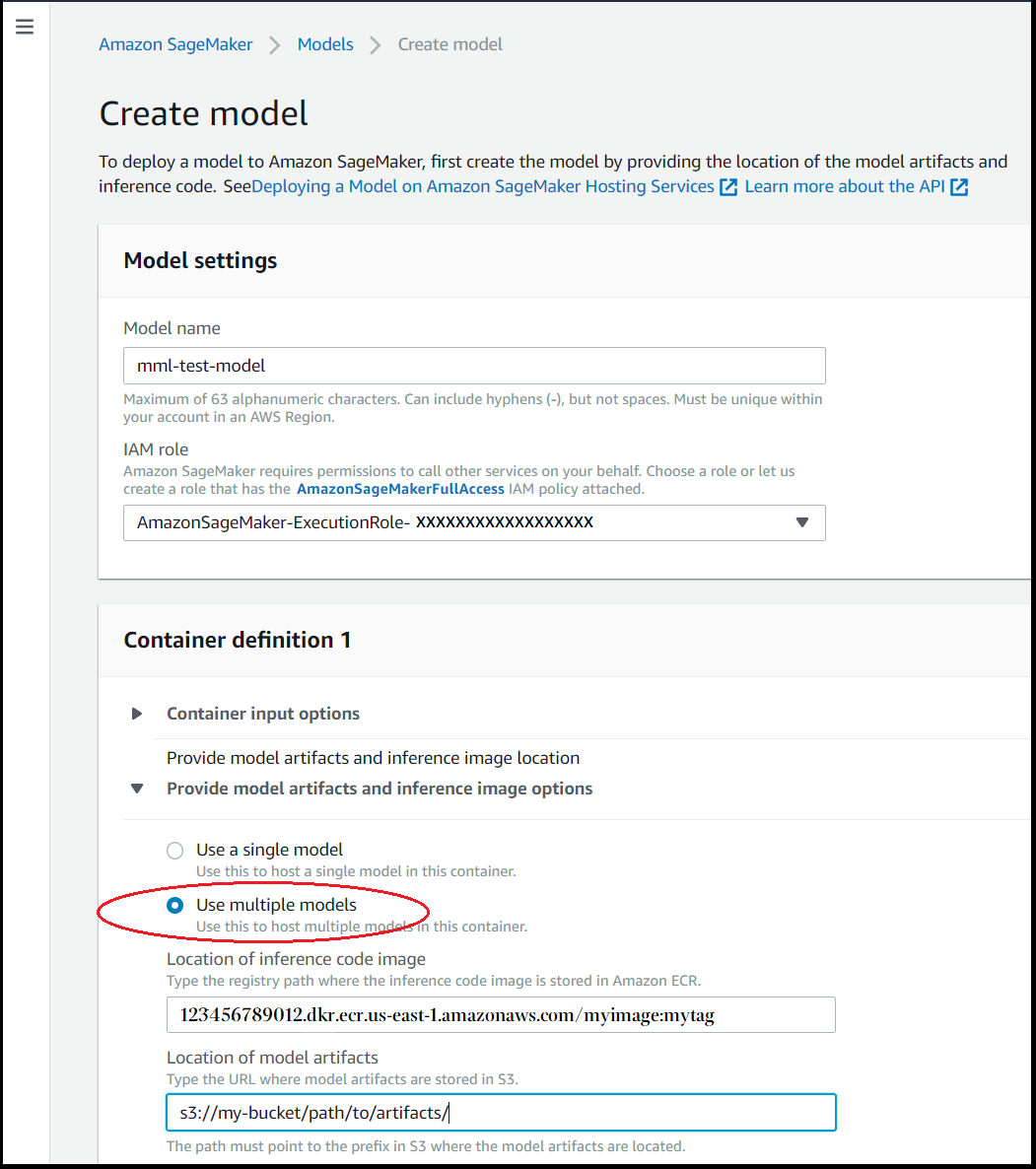
-
对于推理容器镜像,请输入所需容器镜像的 Amazon ECR 路径。
对于 GPU 型号,必须使用由 NVIDIA Triton 推理服务器支持的容器。有关使用 GPU 支持的端点的容器映像列表,请参阅 NVIDIA Triton 推理容器(仅支持 SM)
。有关 NVIDIA Triton 推理服务器的更多信息,请参阅将 T riton 推理服务器与 AI 配合使用。 SageMaker -
选择创建模型。
-
按照单个模型端点的部署方式来部署多模型端点。有关说明,请参阅将模型部署到 SageMaker AI 托管服务。
使用 CPU 创建多模型终端节点 适用于 Python (Boto3) 的 AWS SDK
使用以下部分创建由 CPU 实例支持的多模型端点。您可以使用 Amazon A SageMaker I create_modelcreate_endpoint_configcreate_endpointMode 参数值 MultiModel。您还需要传递 ModelDataUrl 字段,该字段指定模型构件在 Amazon S3 中位置的前缀,而不是像部署单个模型时一样指定单个模型构件的路径。
有关使用 SageMaker AI 将多个 XGBoost 模型部署到端点的示例笔记本,请参阅 Endpoint xgBoos Multi-Model t
以下过程概述了创建 CPU 支持的多模型端点的示例中所使用的关键步骤。
要部署模型 (AWS 适用于 Python 的软件开发工具包 (Boto 3)
-
获取包含支持部署多模型端点的映像的容器。有关支持多模型端点的内置算法和框架容器的列表,请参阅支持多模型终端节点的算法、框架和实例。在此示例中,我们使用 K-Nearest 邻居 (k-nn) 算法 内置算法。我们调用 SageMaker Python SDK
实用函数 image_uris.retrieve()来获取 Neighbor K-Nearest s 内置算法图像的地址。import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
获取 A 适用于 Python (Boto3) 的 AWS SDK SageMaker I 客户端并创建使用此容器的模型。
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(可选)如果您使用的是串行推理管道,请获取要包含在管道中的其他容器,并将其包含在
CreateModel的Containers参数中:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )注意
在串行推理管道中只能使用一个启用多模型的端点。
-
(可选)如果您的使用案例不能通过模型缓存受益,请将
MultiModelConfig参数的ModelCacheSetting字段值设置为Disabled,并将其包含在调用create_model的Container参数中。ModelCacheSetting字段的默认值是Enabled。container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
为模型配置多模型端点。我们建议您至少为端点配置两个实例。这允许 SageMaker AI 为模型提供跨多个可用区域的高可用性预测集。
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )注意
在串行推理管道中只能使用一个启用多模型的端点。
-
使用
EndpointName和EndpointConfigName参数创建多模型端点。response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
使用 GPU 创建多模型终端节点 适用于 Python (Boto3) 的 AWS SDK
使用以下部分创建由 GPU 支持的多模型端点。您可以使用 Amazon A SageMaker create_endpointcreate_modelcreate_endpoint_configMode 参数值 MultiModel。您还需要传递 ModelDataUrl 字段,该字段指定模型构件在 Amazon S3 中位置的前缀,而不是像部署单个模型时一样指定单个模型构件的路径。对于 GPU 支持的多模型端点,所使用的容器必须具有已针对在 GPU 实例上运行进行优化的 NVIDIA Triton 推理服务器。有关使用 GPU 支持的端点的容器映像列表,请参阅 NVIDIA Triton 推理容器(仅支持 SM)
有关演示如何创建由 GPU 支持的多模型终端节点的示例笔记本,请参阅使用 Amazon A SageMaker I Multi-model 终端节点 (MME) 在 GPU 上运行多个深度学习模型
以下过程概述了创建由 GPU 支持的多模型端点的关键步骤。
要部署模型 (AWS 适用于 Python 的软件开发工具包 (Boto 3)
-
定义容器映像。要为模型创建支持 GPU 的多模型端点,请定义容器以使用 NVIDIA Triton Server 镜像。 ResNet 此容器支持多模型端点,并针对在 GPU 实例上运行进行了优化。我们调用 SageMaker AI Python SDK
实用函数 image_uris.retrieve()来获取图像的地址。例如:import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
获取 A 适用于 Python (Boto3) 的 AWS SDK SageMaker I 客户端并创建使用此容器的模型。
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(可选)如果您使用的是串行推理管道,请获取要包含在管道中的其他容器,并将其包含在
CreateModel的Containers参数中:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )注意
在串行推理管道中只能使用一个启用多模型的端点。
-
(可选)如果您的使用案例不能通过模型缓存受益,请将
MultiModelConfig参数的ModelCacheSetting字段值设置为Disabled,并将其包含在调用create_model的Container参数中。ModelCacheSetting字段的默认值是Enabled。container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
为模型配置使用由 GPU 支持的实例的多模型端点。我们建议在您的端点上配置多个实例,以实现高可用性和更高的缓存命中率。
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
使用
EndpointName和EndpointConfigName参数创建多模型端点。response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
