本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
分析和可视化
Amazon SageMaker Data Wrangler 包含内置分析,只需点击几下即可帮助您生成可视化和数据分析。您还可以使用自己的代码创建自定义分析。
通过在数据流中选择一个步骤,然后选择添加分析,可以将分析添加到数据框中。要访问您创建的分析,请选择包含该分析的步骤,然后选择分析。
所有分析都是使用包含 10 万行数据的数据集生成的。
您可以将以下分析添加到数据框中:
-
数据可视化,包括直方图和散点图。
-
数据集的快速摘要,包括条目数、最小值和最大值(对于数字数据)以及最频繁和最少的类别(对于分类数据)。
-
数据集的快速模型,可用于为每个特征生成重要性得分。
-
目标泄漏报告,您可以使用该报告来确定一个或多个特征是否与目标特征密切关联。
-
使用自己的代码进行自定义可视化。
可通过以下部分了解有关这些选项的更多信息。
直方图
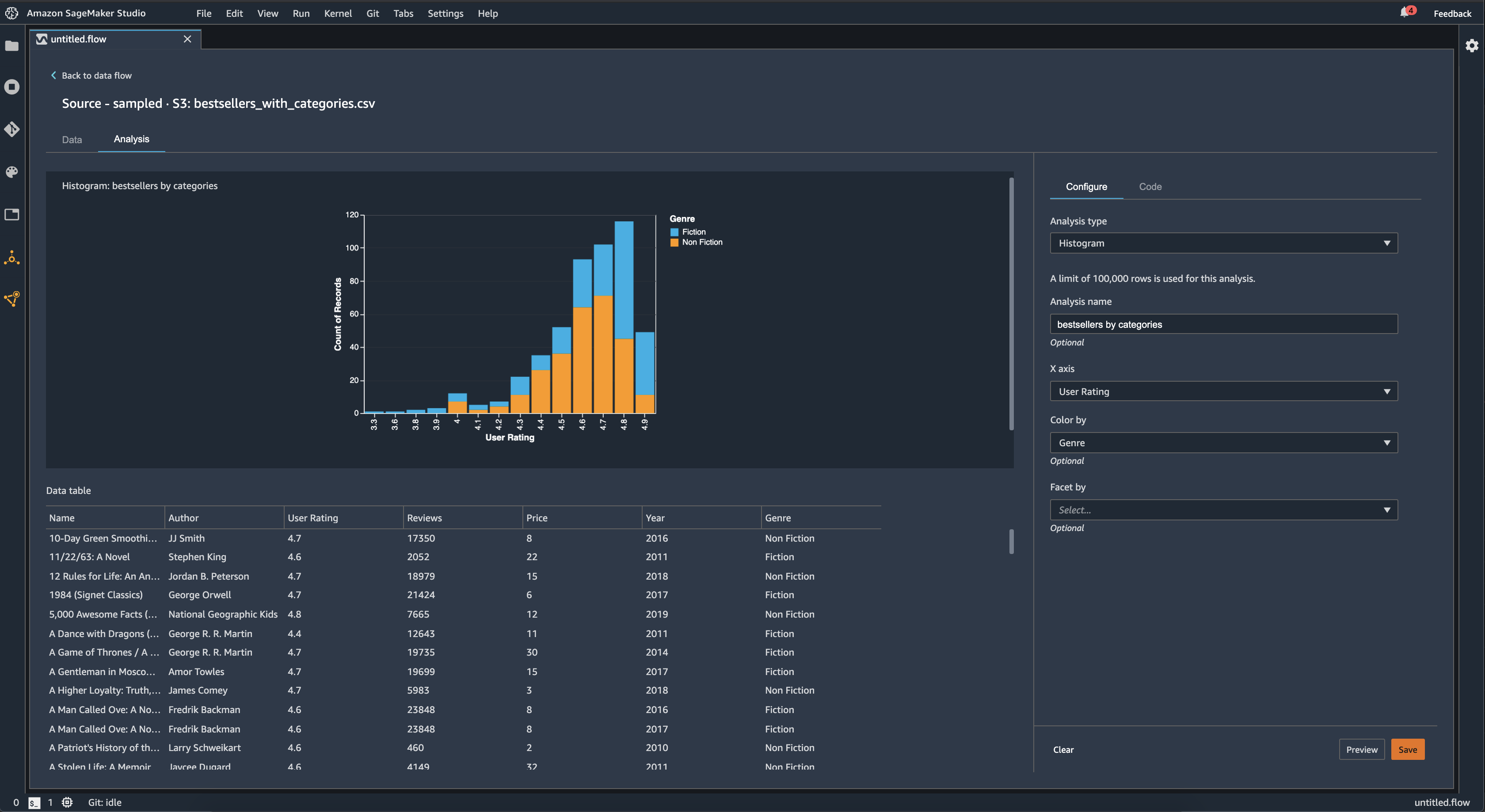
使用直方图可以查看特定特征的特征值计数。您可以使用着色方式选项检查特征之间的关系。例如,以下直方图显示了 2009-2019 年亚马逊畅销书的用户得分分布情况,按类型着色。
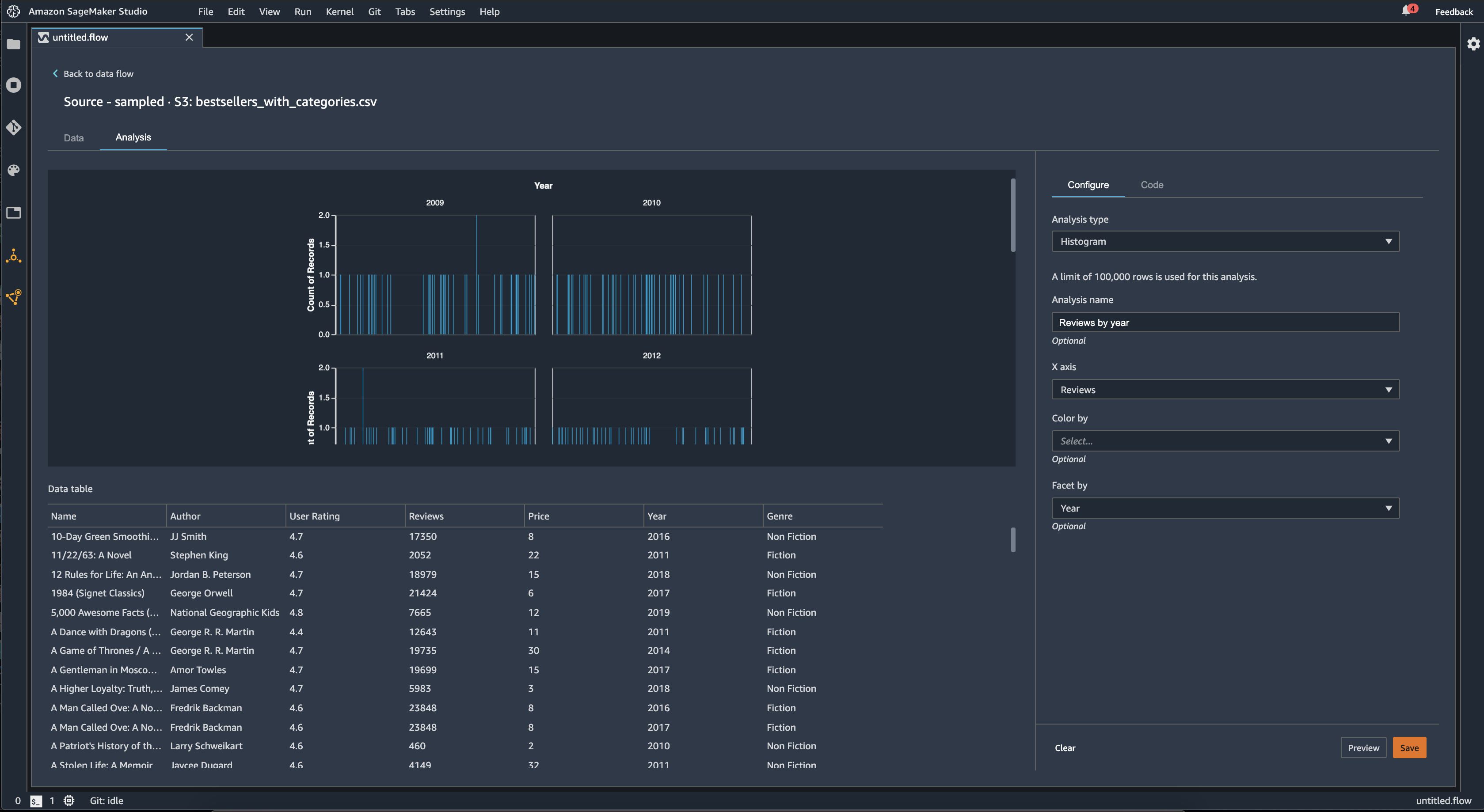
您可以使用划分方式功能为一个列中的每个值创建另一个列的直方图。例如,下图显示了用户对亚马逊上畅销书的评论的直方图(如果按年份划分)。
散点图
使用散点图功能可以检查各特征之间的关系。要创建散点图,请选择要在 X 轴和 Y 轴上绘制的特征。这两列都必须是数字类型的列。
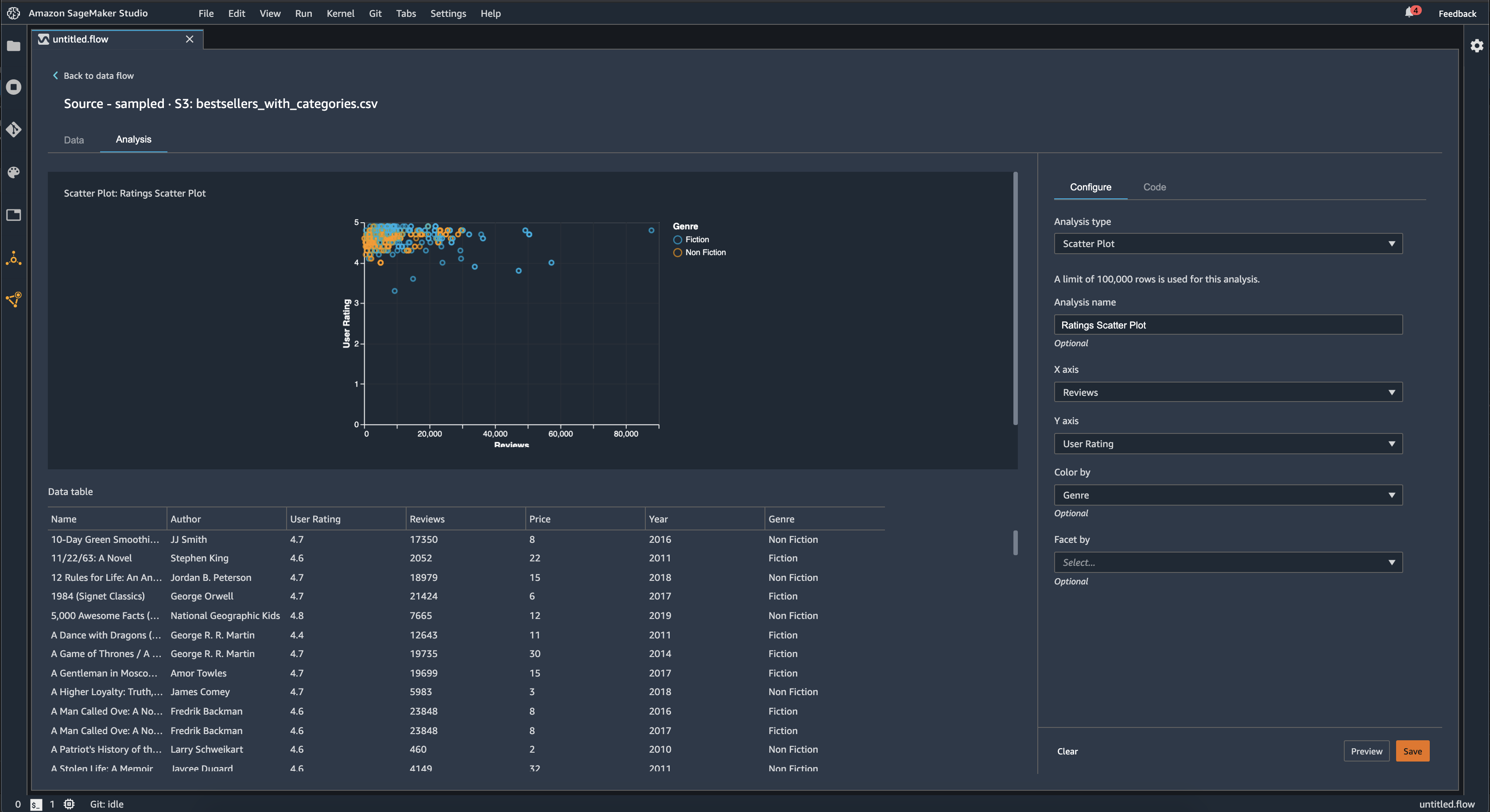
您可以通过额外的列为散点图着色。例如,以下示例显示了一个散点图,该散点图将 2009 年至 2019 年间亚马逊上畅销书的评论数量与用户得分进行了比较。散点图按书籍类型着色。
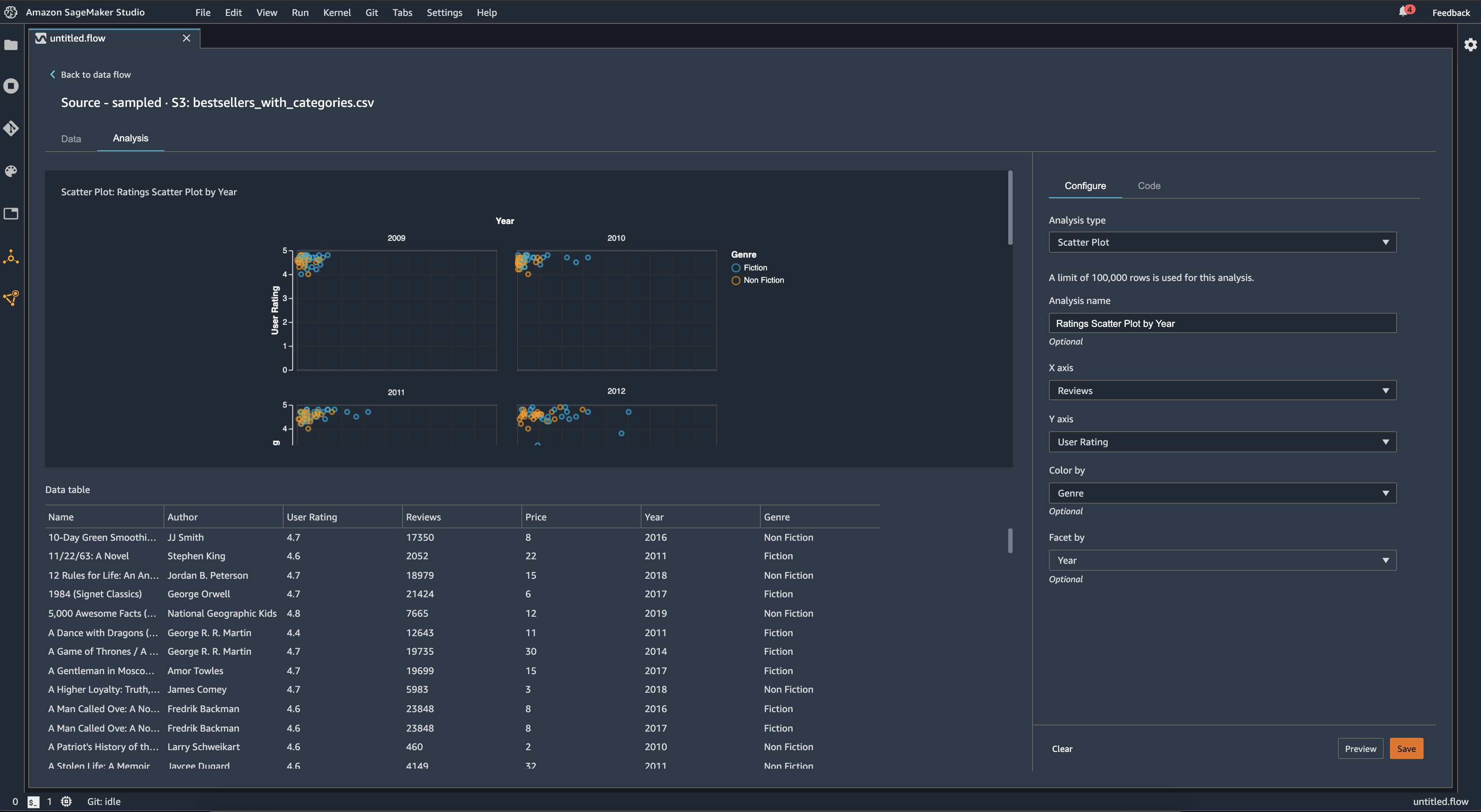
此外,您还可以按特征划分散点图。例如,下图显示了按年份划分的相同评论与用户得分散点图的示例。
表摘要
使用表摘要分析可以快速总结数据。
对于包含数值数据(包括日志和浮点数据)的列,表摘要会报告每列的条目数 (count)、最小值 (min)、最大值 (max)、均值和标准差 (stddev)。
对于包含非数字数据的列,包括具有字符串、布尔值或日期/时间数据的列,表摘要将报告条目数(计数)、最低频率值(最小值)和最常见值(最大值)。
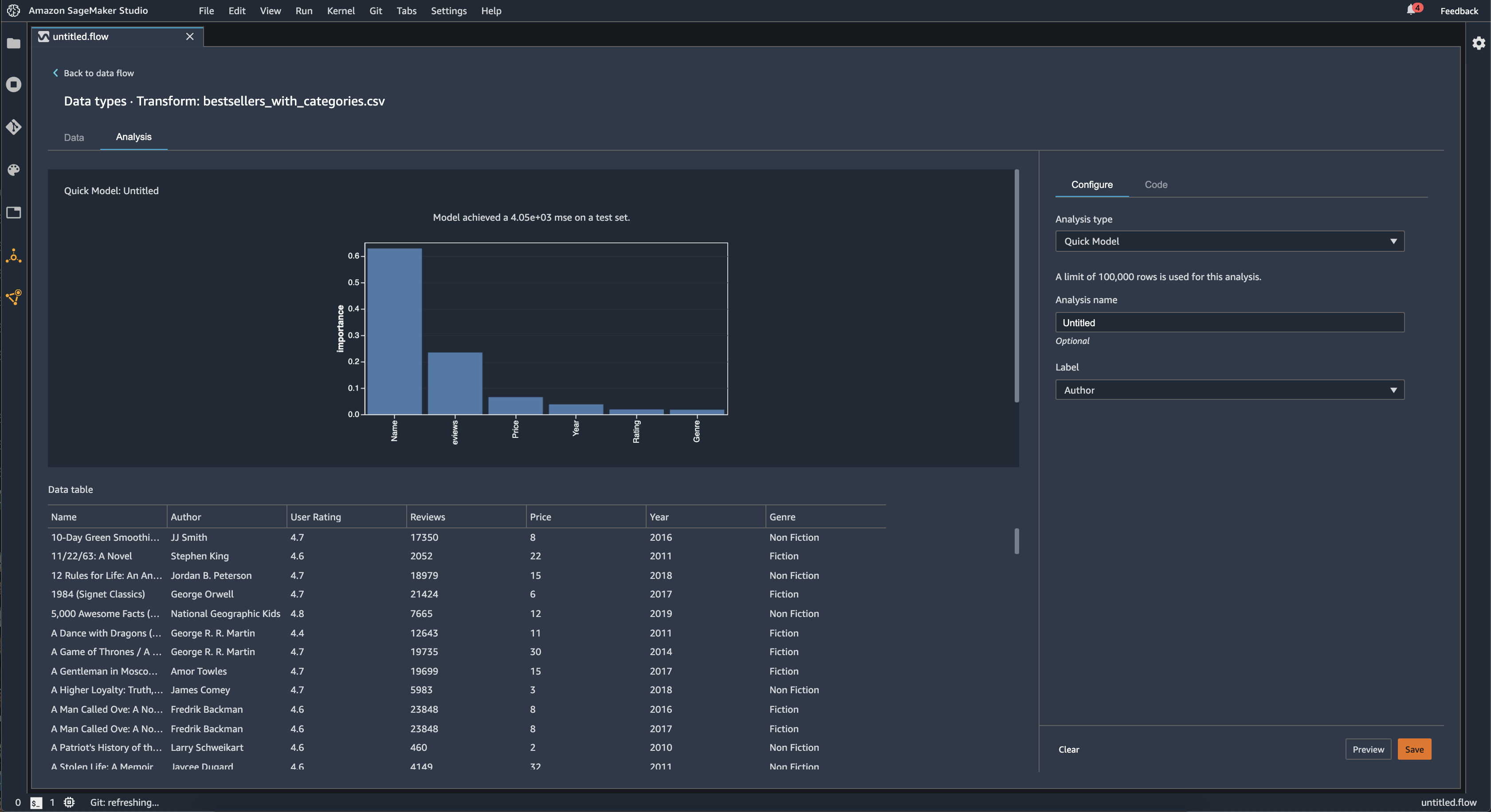
快速模型
使用快速模型可视化可以快速评估数据并为每个特征生成重要性得分。一个特征重要性得分
创建快速模型图表时,您可以选择要评估的数据集,以及要比较特征重要性的目标标签。Data Wrangler 会执行以下操作:
-
推断目标标签的数据类型以及所选数据集内的每个特征的数据类型。
-
确定问题类型。根据标签列中不同值的数量,Data Wrangler 确定这是回归还是分类问题类型。Data Wrangler 将分类阈值设置为 100。如果标签列中存在超过 100 个不同的值,Data Wrangler 会将其归类为回归问题;否则,会将其归类为分类问题。
-
预处理特征和标签数据以供训练。所使用的算法要求将特征编码为向量类型,将标签编码为双精度类型。
-
使用 70% 的数据训练随机森林算法。Spark RandomForestRegressor
's 用于训练回归问题的模型。RandomForestClassifier 用于训练模型以解决分类问题。 -
使用剩余 30% 的数据评估随机森林模型。Data Wrangler 使用 F1 分数评估分类模型,并使用分数评估回归模型。MSE
-
使用基尼重要性方法计算每个特征的特征重要性。
下图显示了快速模型特征的用户界面。
目标泄漏
当机器学习训练数据集内存在与目标标签密切相关但在真实世界数据中不可用的数据时,就会发生目标泄漏。例如,您的数据集内可能有一列作为您要在模型中预测的列的代理。
使用目标泄漏分析时,可以指定以下内容:
-
目标:这是您希望机器学习模型能够预测的特征。
-
问题类型:这是您正在处理的 ML 问题类型。问题类型可以是分类,也可以是回归。
-
(可选)最大特征数:这是要在可视化中显示的最大特征数,它显示了按目标泄漏风险排序的特征。
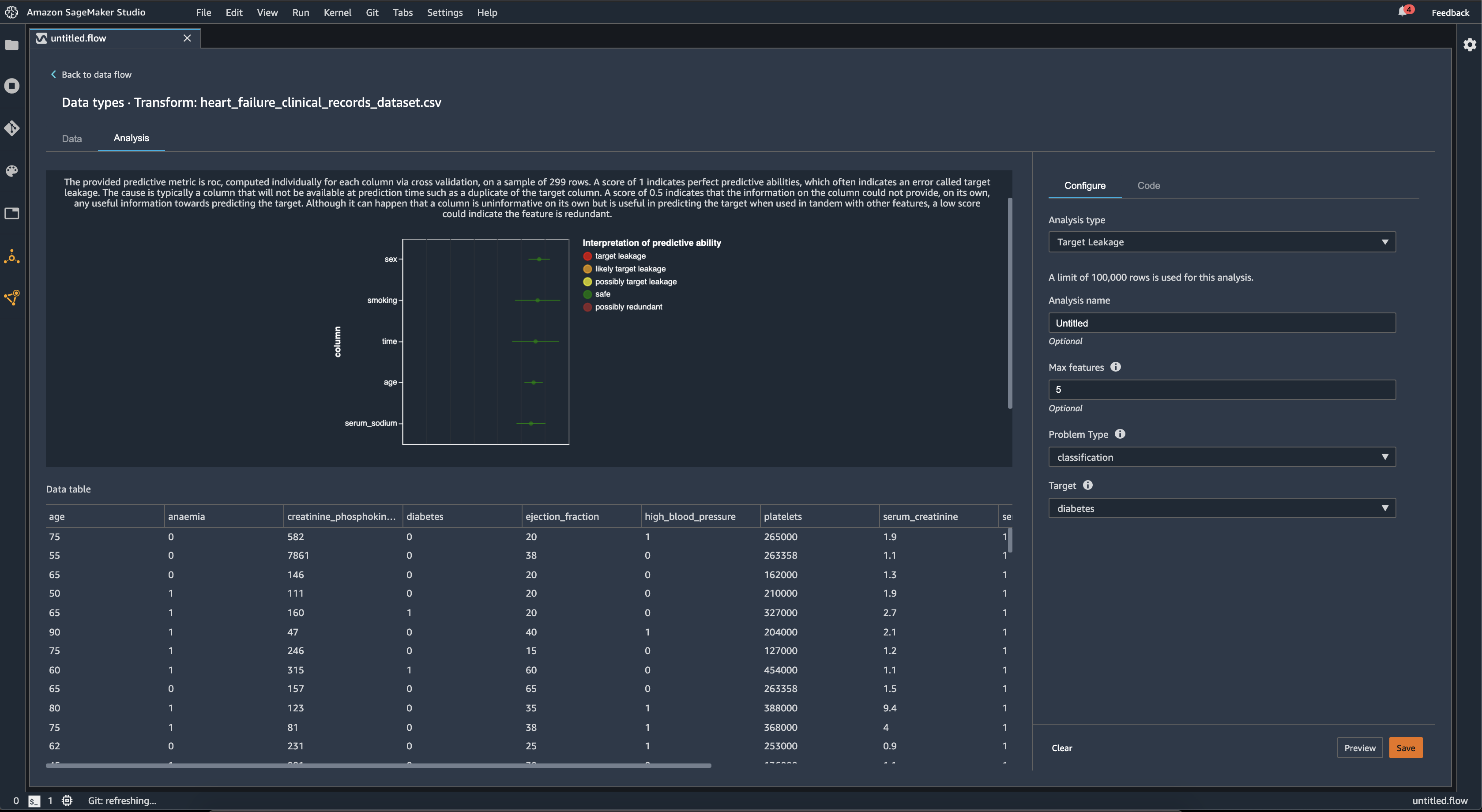
为了进行分类,目标泄漏分析使用接收器工作特性下方的区域,或每列的 AUC-ROC 曲线,直至最大特征。对于回归,使用确定系数或 R2 指标。
AUC-ROC 曲线提供了预测指标,该指标使用交叉验证为每列单独计算,样本最多约为 1000 行。得分为 1 表示完美的预测能力,这通常表示目标泄漏。得分为 0.5 或更低,表明该栏中的信息本身无法提供预测目标的任何有用信息。尽管一列本身可能无法提供信息,但与其他特征一起使用时可用于预测目标,但如果得分较低,可能表示该特征是多余的。
例如,下图显示了糖尿病分类问题的目标泄漏报告,即预测一个人是否患有糖尿病。AUC-ROC 曲线用于计算五个特征的预测能力,所有特征都被确定为不受目标泄漏的影响。
多重共线性
多重共线性是指两个或多个预测变量相互关联的情况。预测变量是数据集内用来预测目标变量的特征。当您具有多重共线性时,预测变量不仅可以预测目标变量,还可以相互预测。
您可以使用方差膨胀因子 (VIF)、主成分分析 (PCA) 或 L asso 特征选择作为数据中多重共线性的度量。有关更多信息,请参阅下列内容。
检测时间序列数据中的异常
您可以使用异常检测可视化来查看时间序列数据中的异常值。要了解决定异常的因素,您需要明白,我们将时间序列分解为预测项和误差项。我们将时间序列的季节性和趋势视为预测项。我们将残差视为误差项。
对于误差项,您可以指定阈值,当残差远离平均值的偏差标准数达到该阈值时,便会将其视为异常。例如,您可以将阈值指定为 3 个标准差。任何距离平均值大于 3 个标准差的残差均为异常。
您可以使用以下步骤执行异常检测分析。
-
打开 Data Wrangler 数据流。
-
在您的数据流中,在数据类型下,选择 +,然后选择添加分析。
-
对于分析类型,选择时间序列。
-
对于可视化,选择异常检测。
-
对于异常阈值,选择将某个值视为异常的阈值。
-
选择预览以生成分析的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
时间序列数据中的季节性趋势分解
您可以使用季节性趋势分解可视化,来确定时间序列数据中是否存在季节性。我们使用STL(季节性趋势分解使用LOESS)方法进行分解。我们将时间序列分解为季节性、趋势和残差成分。这一趋势反映了该系列的长期进展。季节性成分是在一段时间内重复出现的信号。从时间序列中删除趋势和季节性成分后,您就获得了残差。
可以使用以下步骤执行季节性趋势分解分析。
-
打开 Data Wrangler 数据流。
-
在您的数据流中,在数据类型下,选择 +,然后选择添加分析。
-
对于分析类型,选择时间序列。
-
对于可视化,请选择季节性趋势分解。
-
对于异常阈值,选择将某个值视为异常的阈值。
-
选择预览以生成分析的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
偏差报告
您可以使用 Data Wrangler 中的偏差报告,来发现数据中的潜在偏差。要生成偏差报告,必须指定要预测的目标列或标签,以及要检查偏差的分面或列。
标签:您希望模型进行预测的特征。例如,如果您在预测客户转化率,则可以选择一个列,其中包含客户是否已下订单的数据。您还必须指定此特征是标签还是阈值。如果指定标签,则必须指定数据中积极结果应该是什么样的。在买家转化示例中,积极结果可能是订单列中的 1,表示买家在过去三个月内下订单的积极结果。如果指定阈值,则必须指定定义积极结果的下限。例如,如果您的客户订单列包含去年下的订单数,则可能需要指定 1。
分面:您要检查偏差的列。例如,如果您尝试预测客户转化率,您的分面可能是客户的年龄。您之所以选择这个分面,是因为您认为自己的数据偏向于某个年龄组。您必须确定分面是以值还是阈值来衡量。例如,如果您希望检查一个或多个特定年龄,则可以选择值并指定这些年龄。如果想要查看某个年龄组,可以选择阈值,然后指定要检查的年龄阈值。
选择特征和标签后,可以选择要计算的偏差指标类型。
要了解更多信息,请参阅为训练前数据中的偏差生成报告。
创建自定义可视化
您可以向 Data Wrangler 流添加分析,来创建自定义可视化。您的数据集以及您应用的所有变换,都可以 Pandas DataFramedf 变量来存储数据框。可以通过调用变量来访问该数据框。
必须提供输出变量 chart,以便存储 Altair
import altair as alt df = df.iloc[:30] df = df.rename(columns={"Age": "value"}) df = df.assign(count=df.groupby('value').value.transform('count')) df = df[["value", "count"]] base = alt.Chart(df) bar = base.mark_bar().encode(x=alt.X('value', bin=True, axis=None), y=alt.Y('count')) rule = base.mark_rule(color='red').encode( x='mean(value):Q', size=alt.value(5)) chart = bar + rule
要创建自定义可视化,请执行以下操作:
-
在包含要可视化的变换的节点旁边,选择 +。
-
选择添加分析。
-
对于分析类型,选择自定义可视化。
-
在分析名称中指定名称。
-
在代码框中输入您的代码。
-
选择预览以预览可视化。
-
选择保存以添加可视化。
如果您不知道如何在 Python 中使用 Altair 可视化包,可以使用自定义代码片段来协助您开始入手。
Data Wrangler 有一系列可搜索的可视化代码片段。要使用可视化代码片段,请选择搜索示例代码片段,然后在搜索栏中指定查询。
下面的示例使用分仓散点图代码片段,其中绘制了一个双维度直方图。
这些代码片段包含注释,有助于您了解需要对代码进行哪些更改。您通常需要在代码中指定自己的数据集的列名。
import altair as alt # Specify the number of top rows for plotting rows_number = 1000 df = df.head(rows_number) # You can also choose bottom rows or randomly sampled rows # df = df.tail(rows_number) # df = df.sample(rows_number) chart = ( alt.Chart(df) .mark_circle() .encode( # Specify the column names for binning and number of bins for X and Y axis x=alt.X("col1:Q", bin=alt.Bin(maxbins=20)), y=alt.Y("col2:Q", bin=alt.Bin(maxbins=20)), size="count()", ) ) # :Q specifies that label column has quantitative type. # For more details on Altair typing refer to # https://altair-viz.github.io/user_guide/encoding.html#encoding-data-types
